자연어처리(NLP)는 로봇과 컴퓨터에 명령체계로 매우 중요 - RNN 이나 LSTM 같은 알고리즘 사용
사람이 컴퓨터나 로봇에게 일정한 명령을 전달하기 위해선 약속된 수단이 있어야 한다. 지금은 주로 키보드나 마우스를 사용하지만 음성인식 인공비서에겐 자연어로 명령을 한다. 뿐만 아니라 유튜브나 포털에서 번역서비스는 이제 너무나 편리한 기능으로 자리잡았다. 그만큼 자연어 처리는 중요하다.
자연어처리(NLP: Natural Language Processing)는 인간이 사용하는 언어에 대한 이해 및 이를 바탕으로 한 다양한 자연어 활동을 인공지능이 이해하는 것을 말한다. 즉 사람이 직접 육성(肉聲)으로 지시를 하거나, 컴퓨터 언어로 이루어진 코드가 아닌 자연어 형태의 비정형적 명령을 이해하는 과정이다.
RNN 및 LSTM 은 문장의 문맥을 학습시켜 자연어를 이해하고 처리했다. 그러나 이들은 피드백 연결로 이루어진 각 시점의 데이터들 중 과거에 학습한 데이터가 시간이 경과하거나 결과값에서 멀어짐에 따라 인공지능이 기억하지 못하거나 소멸되는 Vanishing Gradient (기울기소실)을 겪기도 한다.
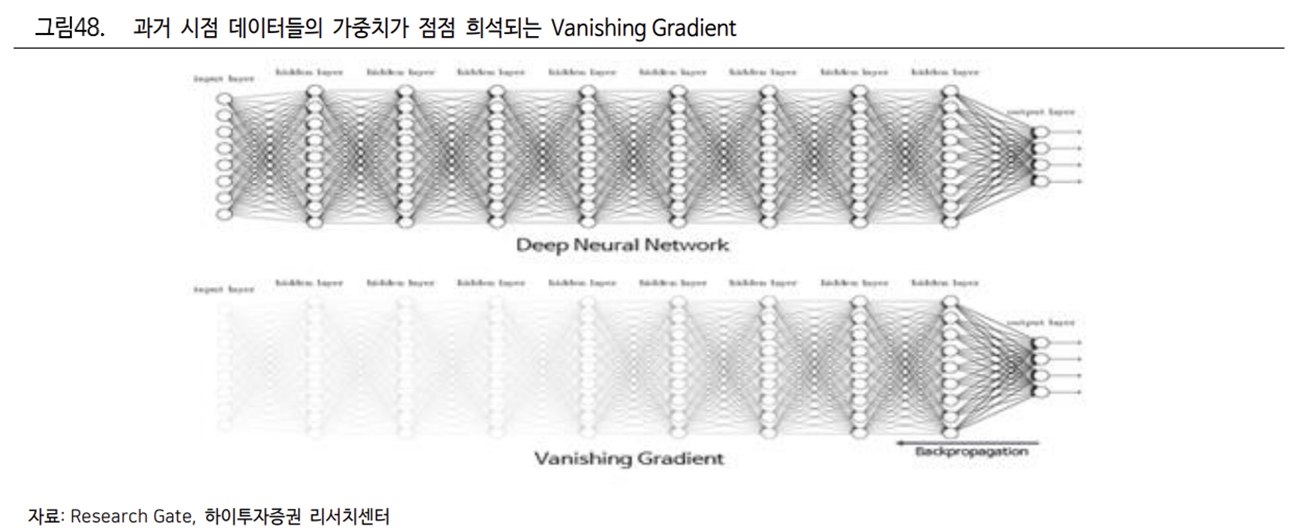
RNN 과 LSTM 은 크기제한과 데이터 투입시점 상이라는 문제점으로 기울기소실 문제가 발생
인공 신경망 학습은 모델마다 모습은 조금씩 다르지만 결국 입력 데이터들의 가중치를 조정을 하는 과정, 즉 가중치 만큼 입력 데이터의 중요도를 찾아가는 과정이란 점에서 유사하다.

Vanishing Gradient(기울기소실)가 발생하면 어떤 문제가 발생할까? 예를 들어 과거 배송 로봇에게 ‘정지’라는 자연어를 입력 받으면 ‘주행을 멈추라’는 학습을 완료 후, 추가적인 자연어 학습을 진행했다고 가정해보자. 정지라는 자연어가 가지는 비중은 데이터의 양이 증가하면서 점차 희석되고, 이동이라는 자연어의 비중이 상대적으로 증가할 수 있다.
그렇다면 정지 명령을 내렸음에도 로봇이 주행을 하는 엉뚱한 상황이 생기거나, 아무 행동도 하지 않는 경우가 발생할 수 있다. 결국 이러한 문제는 입력층에 데이터를 투입할 때 크기의 제한이 있다는 점에서 발생한다. LSTM 및 RNN 을 이용하기 위해서는 동시에 일정 크기 이상의 입력 데이터를 넣을 수 없기에 시차를 두고 데이터를 투입해야 하는 문제가 있다.
2017 년 구글은 Transformer 알고리즘으로 기울기소실 문제 해결
다행히 2017 년 구글이 발표한 논문 ‘Attention is all you need’에서 제시한 자연어처리 알고리즘 ‘Transformer’덕분에 RNN, LSTM 의 Vanishing Gradient 문제가 해결됐다. Vanishing Gradient 의 원인은 학습 데이터들이 서로 피드백 연결되어 있기 때문이었고, 피드백 연결을 할 수밖에 없는 이유는 입력 데이터의 크기의 제한으로 하나의 문맥을 구성하는 단어를 함께 입력할 수 없었기 때문이다.
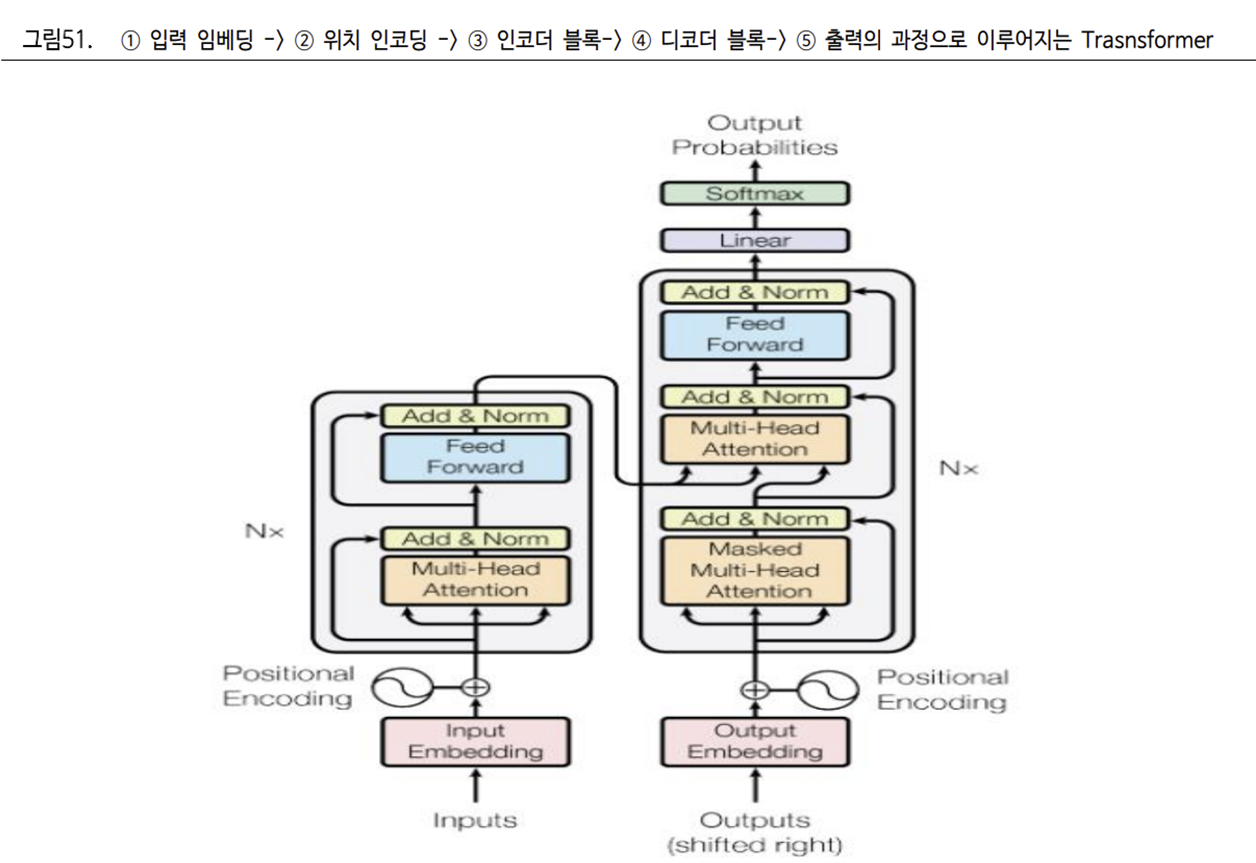
Transformer 알고리즘은 크게 ① Encoder-Decoder ② Attention ③ Word Embedding 로 구성됐다.
Encoder-Decoder 구조로 자연어의 입력과 출력을 담당하는 별개의 Layer 를 구축하고, Encoder 에서는 입력 데이터를 벡터 값으로 변환을 통해 인공지능이 이해할 수 있게 만들었다. Decoder 에서는 학습을 하고, 결과값을 출력한다.
Attention 이란 입력 데이터들을 서로 모두 동일한 가중치로 학습하는 것이 아니라, 사전 학습 내용을 바탕으로 중요도가 높은 데이터를 집중해서 기억하는 것을 말한다. 이를 통해 학습 중요도가 낮은 데이터는 제거하여. 학습 중요도가 높은 데이터 비중이 증가할 수 있게 했다.
또한 Word Embedding을 통해 RNN, LSTM 과 달리 하나의 Context 를 구성하는 Word 들을 벡터 값으로 변환하며 Vanishing Gradient 를 해결하도록 설계했다.
Transformer 알고리즘을 기반으로 다양한 초거대 AI 등장 – GPT, BERT 등
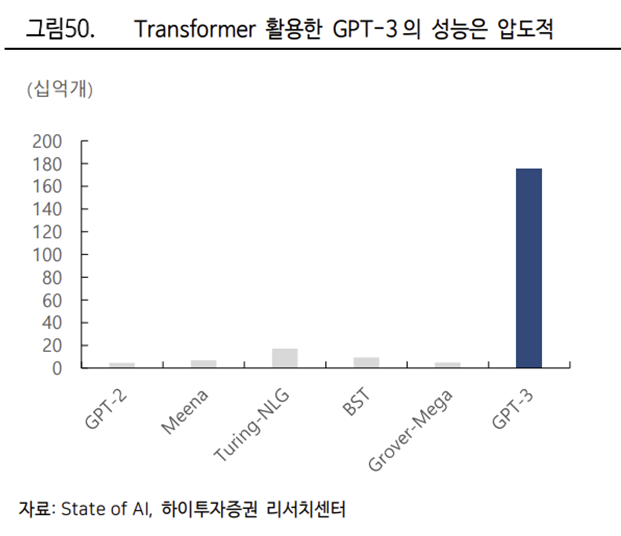
트랜스포머 알고리즘은 RNN, LSTM 의 문제를 해결할 뿐 아니라 탁월한 성능을 보이며 RNN 과 LSTM 을 대체해나가고 있다. 트랜스포머 알고리즘을 기반으로 하는 자연어처리 모델은 대표적으로 OpenAI 의 GPT-3, 구글의 BERT 가 있다
GPT-3 는 2020 년 일론 머스크와 샘 알트만이 공동 설립한 비영리법인 OpenAI 에서 개발한 트랜스포머 기반 자연어처리 모델이다. 전작 GPT-2 대비 100 배의 규모 및 10 배 이상의 데이터학습 능력을 보여준다. 또한 1750 억개의 매개변수 연산이 가능한 대규모 언어모델로서 8~9 개국 언어 번역 및 텍스트 작성이 가능하며 MS, Amazon 등 글로벌 빅테크 기업의 자연어 학습 도구로서 사용되고 있다.
BERT 는 2019년 구글이 공개한 대규모 사전 자연어학습 모델로서 GPT-3 와 함께 가장 많이 쓰이고 있는 자연어 처리 모델이다. BERT 의 경우 일방향 Attention 을 이용하여 디코더에서 출력이 보다 정확하게 이루어질 수 있게 도와준다. 반면 GPT-3 는 인코더에서부터 디코더까지 양방향 Attention 을 사용하여 인코더와 디코더에서 입력과 출력에 모두 관여한다. 이러한 대규모 사전 학습 언어 모델들은 질의 응답 프로그램, 번역 및 문장 분류, 챗봇 시스템에 사용되고 있다.
Transformer 모델은 자연어처리 뿐 아니라 시각 처리로 분야를 확장
더 나아가 트랜스포머는 활동 영역을 시각 처리 분야로 넓혀가고 있다. 지난 2021 년 AI 데이에서 테슬라는 자율주행에 필요한 데이터를 수집할 때, 다른 각도로 촬영한 2D 이미지들의 색과 방향의 특징값을 학습하여 랜더링하는 과정에서 트랜스포머 알고리즘을 적용했다고 발표했다.
트랜스포머 알고리즘은 중요도가 낮은 데이터를 Attention 을 활용하여 제거하고, 중요도가 높은 데이터에 집중하여 연산 가능 매개변수를 증가시켰다.
로봇의 학습은 자율 주행 차량 및 챗봇 시스템 등의 학습보다 월등히 많은 데이터 학습이 필요하다. 도로 및 주변 지형 지물, 사고 시나리오뿐 아니라 인도 및 골목길과 비포장도로와 같이 로봇이 다닐 수 있는 데이터가 추가적으로 필요하기 때문이다. 또한 사람의 명령을 듣고 움직여야 하기 때문에 더 많은 자연어 학습 데이터가 필요하다.
따라서 Transformer 가 활용된 대규모 언어 모델 및 비전 학습은 로봇에게 필요한 방대한 학습 데이터를 제공할 수 있을 것이며, 이는 곧 로봇 뇌의 발전으로 이어질 것이다.
https://www.youtube.com/watch?v=DUyjMQo9zkY
출처: Talk IT, 하이투자증권, Google, State of AI
뜨리스땅
https://tristanchoi.tistory.com/386
로봇 기술 탐구: 로봇의 뇌(인공지능) 어디까지 왔나? - 1 (Neural Network)
인공지능은 인지-판단-제어에 있어 가장 중요한 ‘로봇의 뇌’에 해당한다. 인공지능 (AI: Artificial Intelligence)은 인간이 가지고 있는 지적 능력을 컴퓨터에서 구현하는 다양한 기술이나 소프트웨
tristanchoi.tistory.com
'로보틱스' 카테고리의 다른 글
| 로봇 기업 탐구: 테슬라 vs. 엔비디아 (0) | 2022.12.31 |
|---|---|
| 로봇 기술 탐구: 로봇의 뇌(인공지능) 어디까지 왔나? - 3 (강화학습) (0) | 2022.12.31 |
| 로봇 기술 탐구: 로봇의 뇌(인공지능) 어디까지 왔나? - 1 (Neural Network) (1) | 2022.12.31 |
| 로봇 기술 탐구: 인공지능 용어 정리 (1) | 2022.12.30 |
| 로봇 산업 탐구: 5. 테크기업들의 진출 - 네이버 (0) | 2022.08.25 |



댓글