인간의 신경망처럼 학습하는 딥러닝
생성형 AI를 구축하는 방법으로 널리 사용되는 프로그래밍 방식은 딥러닝이다. 딥러닝은 인공지능의 아버지라 불리는 제프리 힌튼 교수에 의해 붙여진 이름인데 초기에는 Neural Network라는 이름으로 불려왔다. 이러한 딥러닝이 특히 세상에 널리 알려지게 된 계기는 이미지넷 대회(Image Net)에서 딥러닝이 압도적인 성과를 내면서부터이다.
이미지넷 대회, 정식 명칭으로 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)는 2010년에 시작된 컴퓨터 비전 분야의 중요한 대회로, 컴퓨터 시스템이 이미지 분류, 객체 탐지, 객체 위치 식별 등의 작업을 얼마나 잘 수행하는지 평가하는 데 목적이 있다.
참가 팀들은 주어진 이미지 내에서 객체를 정확하 게 분류하고 위치를 식별해야 한다. 쉽게 말해 개와 고양이를 비롯한 여러 객체를 사진 안에서 식 별해내는 게임으로 생각하면 될 것이다. 2012년 이 대회에서 알렉스넷이라는 딥러닝 모델이 압도 적인 성과를 거두면서 딥러닝이 컴퓨터 비전 분야의 주요 기술로 자리 잡게 되었다.
아래 <그림 10>에서 볼 수 있는 것과 같이 2012년 딥러닝을 사용한 이후 객체 식별에서 에러율이 급감하는 것을 볼 수 있는데, 알렉스넷 이후의 우승자는 모두 딥러닝 기반의 알고리즘을 사용한 팀들이다. 그리고 2015년부터는 인공지능의 객체 식별률이 인간의 식별률보다 좋은 것을 확인할 수 있다. 그렇다면 딥러닝이란 대체 무엇일까?

가중치를 자동으로 찾아주는 딥러닝이 이제는 대세
우리가 현재 사용하고 있거나 혹은 앞으로 출시될 대부분의 인공지능은 사람이 처음부터 끝까지 구성한 알고리즘을 기반으로 작동하는 인공지능이 아니다.
딥러닝이 나오기 이전에는 사람이 수많은 코드를 직접 구성해 프로그램을 만들고 그것으로 초기 인공지능을 구현했지만 사실 그러한 방법으로 인공지능을 구현하는 것에는 한계가 있기 때문에 이러한 방법은 더이상 주된 방식으로 사용되지 않는다.
예를 들어 개 사진을 보고 개라고 식별하는 과정을 알고리즘으로 구현하기 위해서는 수많은 조건을 코드로 만들어야 하는데 이러한 방식에는 한계가 있다. 예를 들어 어떠한 사진을 보고 이 사진에 있는 객체가 개인지 판별하는 인공지능을 만들었다고 가정하자.
이 인공지능의 알고리즘에는 다음과 같은 질문들이 코드로 구성되어 있을 것이다. '다리가 4개인가?', '털 이 있는가?', '꼬리가 있는가?' 이러한 무수한 질문을 알고리즘으로 구성한 후 '다리의 개념이 무엇 인지', '털의 개념이 무엇인지', '꼬리의 개념이 무엇인지'를 입력해야 한다.
이렇게 공을 들여 인공지 능을 만든 후 아래 <그림11>을 보여주면 개인지 판별할 수 있을까? 다리와 꼬리가 일단 보이지 않기 때문에 실패할 확률이 높다. 즉 너무 많은 변수들이 추론 과정에 개입하기 때문에 인간이 상 상할 수 있는 조건들을 아무리 많이 넣는다고 해도 오류가 생기고, 시간이 오래 걸리는 것이다.
하지만 같은 그림을 봤을 때 신경망을 가지고 있는 인간은 3세 유아라고 하더라도 개라는 것을 식별할 수 있다. 그리고 이러한 아이디어에 착안해 만든 프로그래밍 방식이 딥러닝(Neural Network)인 것이다.
딥러닝은 입력 데이터셋과 가중치의 곱 그리고 함수를 통해 결과값을 출력
아래 <그림12>은 딥러닝의 신경망을 표현한 것이다. 딥러닝의 프로그래밍은 그 흐름도가 <그림12>처럼 마치 인간의 신경망을 닮았다고 하여 Neural Network(신경망)라고 표현했던 것이다.
<그림12>의 검은 원(노드)을 조금 더 자세히 살펴보자면 <그림13>처럼 기능하는데, 숫자들 끼리의 곱을 모두 더한 후에 f(x)=Max(x,0) 과 같은 렐루 함수나 시그모이드 함수 등을 거쳐 값을 추출하는 기능을 한다. (이 과정에서 가장 중요한 값은 W값이다.) 이러한 과정을 거쳐 마지막 검은 원(노드)을 통해 나온 숫자가 그 결과값이 되는 것이다.
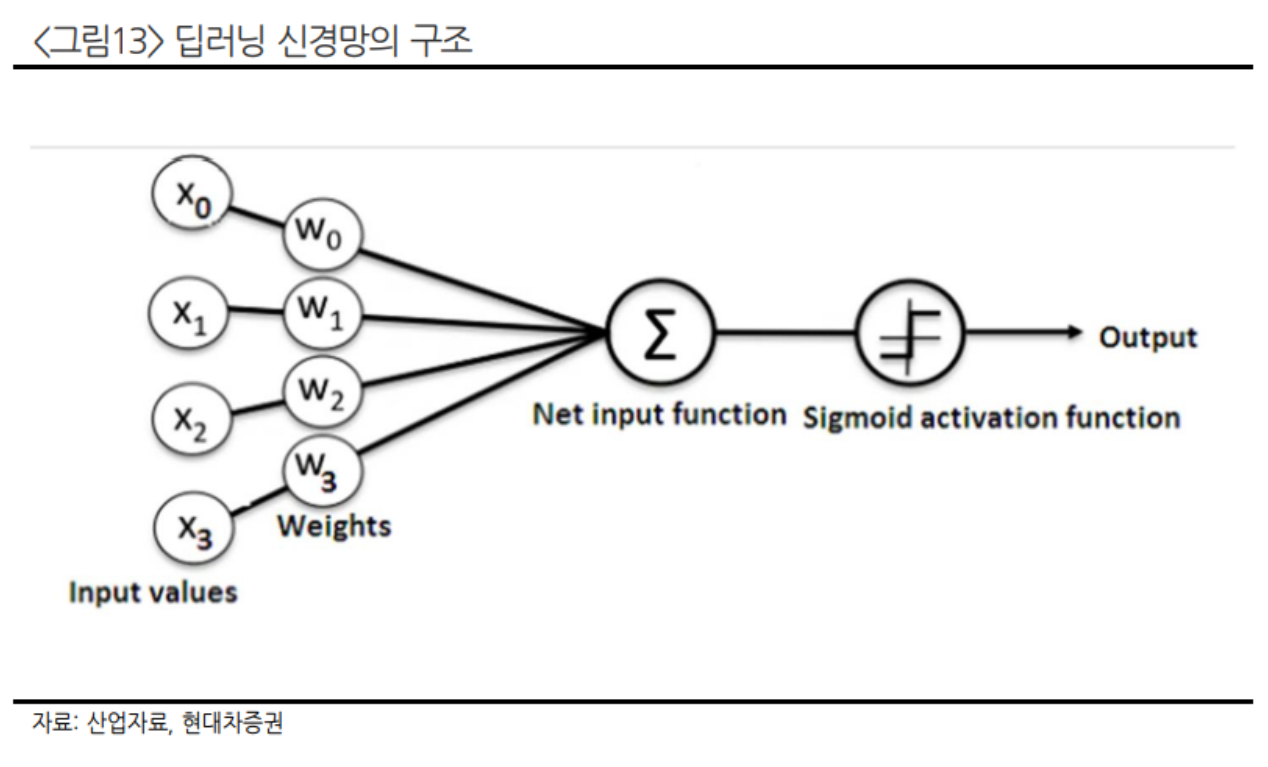
인공신경망의 주된 기능은 W(가중치)를 찾는 것
이제 개 사진을 구분하는 인공지능의 예시로 설명해보겠다. 먼저 인공지능을 학습시키기 위해 수많은 개 사진을 수치화하여 신경망에 입력해준다.
수치화는 흑백 사진일 경우 2차원 행렬로 컬러 사진일 경우 3차원 행렬로 표현된다. 이렇게 데이터셋이 투입되면 처음에는 W(가중치, 파라미터의 일종)가 모두 랜덤으로 설정되어 있기 때문에 이상한 결과값이 나오게 된다. 예를 들어 개 사진이라면 결과값이 0을 넘는 값이 나와야 하는데 개사진을 넣었는데도 불구하고 0의 값이 나오는 것이다.

인공신경망이 지금부터 하는 일은 수많은 시행착오를 통해 W의 적정값을 찾는 것이다. 먼저 인공지능은 학습을 통해 추출된 결과값의 오차를 측정하는 손실함수를 통해 오차를 계산한다. 이후 각각의 W(가중치)가 손실함수의 기울기에 미치는 영향을 계산한다.
W는 개의 여러 가지 특성(왼쪽 귀의 모양, 질감, 오른쪽 다리의 색 등)에 대한 가중치인데 어떤 특성에 부여된 가 중치가 오차에 큰 영향을 미치고 있는지를 계산하는 것이다. 이후 적절한 W값을 찾는 것에는 경사하강법이 사용되는데 간단히 말해 손실함수(결과값의 오차를 측정하는 함수)의 오차를 최소화 하는 방향으로 W값을 업데이트하고 더 많은 개 사진을 데이터셋으로 투하하며 학습을 반복하는 것이다.
이러한 W(가중치)나 바이어스(Bias) 값을 흔히 파라미터라고 하는데 이러한 파라미터는 학습을 거듭할수록 더욱 정확한 값을 향해 조정된다. 이렇게 하여 적정 W 값을 찾고 난 후 개 사진을 보여주면 더욱 높은 정확도로 개 사진을 식별하며 오류가 생길 경우에는 역방향 전파 (Backward Propagation)를 통해 자동으로 W값이 업데이트된다.
이 W값을 찾는 과정이 딥러닝과 일반 프로그래밍의 차이인데 이전에는 이 W값을 인간이 특정 연구결과를 기반으로 찾아내었으나 딥러닝을 사용하면서부터는 데이터를 투하만 해주면 몇시간 혹은 몇분만에도 적절한 W값을 찾아준다. 여러 신기한 AI 서비스들은 대부분 이러한 딥러닝으로 만들어지고 있으며 이러한 딥러닝에 가장 적합한 반도체로 평가받는 것은 NPU(Neural Processing Unit)이다.
출처: 현대차증권, 언론자료
뜨리스땅
https://tristanchoi.tistory.com/540
LLM을 품은 클라우드와 AGI 트렌드
2022년 11월 말 출시된 오픈AI의 챗GPT가 세상을 떠들썩하게 하고 있다. 모든 IT 주제들을 블랙홀 마냥 빨아들일 정도다. 역사상 단기간 내 수억 명의 사용자를 가입자로 확보할 만큼 시장의 호응이
tristanchoi.tistory.com
'반도체, 소.부.장.' 카테고리의 다른 글
| NVIDIA GPU의 Core 구조: CUDA Core와 Tensor Core (1) | 2024.02.28 |
|---|---|
| NPU: 딥러닝에 최적화된 칩 (0) | 2024.02.27 |
| 엔비디아(NVIDIA) 아키텍처 로드맵 (0) | 2024.02.26 |
| 에스티아이 - 2024Q1 전망 (0) | 2024.02.25 |
| 에이직랜드(ASIC Land) Overview (1) | 2024.02.24 |




댓글