지난 2024 OCP 글로벌 서밋에서 NVIDIA는 NVIDIA GB200 NVL72 랙 및 컴퓨트와 스위치 트레이 액체 냉각 설계를 Open Compute Project(OCP)에 제공했다고 발표했다.
NVIDIA는 이에 대한 세부 사항을 제공하며, 현대 데이터 센터의 높은 컴퓨팅 밀도 요구를 충족하기 위해 기존 설계 표준의 활용성을 어떻게 증가시키는지 설명하였다. 또한 GB200 설계를 기반으로 생태계가 구축되면서 새로운 AI 데이터 센터의 비용과 구현 시간을 줄이는 방법도 연구하고 있다.

NVIDIA의 오픈 소스 이니셔티브
NVIDIA는 오픈 소스 이니셔티브에 대해 다양한 활동 역사를 가지고 있다. NVIDIA 엔지니어들은 GitHub에 900개 이상의 소프트웨어 프로젝트를 공개했으며, AI 소프트웨어 스택의 필수 구성 요소를 오픈 소스로 제공했다. 예를 들어, NVIDIA Triton Inference Server는 현재 모든 주요 클라우드 서비스 제공업체에 통합되어 AI 모델을 프로덕션에서 서비스하고 있다.
또한 NVIDIA 엔지니어들은 Linux Foundation, Python Software Foundation, PyTorch Foundation과 같은 다양한 오픈 소스 재단 및 표준 기관에서 적극적으로 활동하고 있다.
이러한 개방성에 대한 기여는 Open Compute Project에도 확장되어, NVIDIA는 여러 세대의 하드웨어 제품에 걸쳐 지속적으로 설계 기여를 해왔다. 주목할만한 기여로는 AI 서버의 사실상 표준이 된 NVIDIA HGX H100 베이스보드와 OCP Network Interface Card(NIC) 3.0의 기본 설계로 사용되는 NVIDIA ConnectX-7 어댑터가 있다.
NVIDIA는 또한 OCP SAI(Switch Abstraction Interface) 프로젝트의 창립 및 거버넌스 이사회 멤버이며, SONiC(Software for Open Networking in the Cloud) 프로젝트의 두 번째로 큰 기여자이다.
데이터 센터의 컴퓨팅 수요 충족
자가회귀 변환기 모델을 훈련하는 데 필요한 컴퓨팅 성능은 지난 5년 동안 20,000배 증가했다. 예를 들어, Meta의 Llama 3.1 405B 모델은 380억 페타플롭의 가속 컴퓨팅을 필요로 했으며, 이는 1년 전 출시된 Llama 2 70B 모델보다 50배 많은 수치입니다. 이러한 대형 모델의 훈련 및 서비스는 단일 GPU로는 관리할 수 없으며, 대규모 GPU 클러스터로 병렬화해야 한다.
병렬화는 텐서 병렬, 파이프라인 병렬, 전문가 병렬 등 여러 형태로 이루어지며, 각 방식은 처리량과 사용자 상호작용 측면에서 고유한 이점을 제공한다. 이러한 방법들은 종종 결합되어 사용자 경험 요구사항 및 데이터 센터 예산 목표를 충족시키는 최적의 훈련 및 추론 배포 전략을 만든다.
멀티 GPU 인터커넥트의 중요성
모델 병렬화와 관련된 일반적인 과제 중 하나는 GPU 간의 높은 통신량이다. 텐서 병렬 GPU 통신 패턴은 GPU들이 얼마나 상호 연결되어 있는지를 보여준다. 예를 들어, AllReduce의 경우, 모든 GPU는 최종 모델 출력을 결정하기 전에 신경망의 각 레이어에서 자신의 계산 결과를 다른 모든 GPU에 전송해야 한다. 이러한 통신 중 발생하는 지연은 비효율성을 초래하며, GPU가 통신 프로토콜이 완료되기를 기다리며 유휴 상태가 된다.

이러한 통신 병목 현상을 해결하기 위해 데이터 센터와 클라우드 서비스 제공업체는 NVIDIA NVSwitch와 NVLink 인터커넥트 기술을 활용한다. NVSwitch와 NVLink는 GPU 간 통신을 가속화하도록 특별히 설계되어 GPU의 유휴 시간을 줄이고 처리량을 증가시킨다.
NVIDIA GB200 NVL72 도입 이전에는 단일 NVLink 도메인에서 연결할 수 있는 GPU의 최대 수가 HGX H200 베이스보드에서 8개로 제한되었으며, GPU당 통신 속도는 900GB/s였다. 그러나 GB200 NVL72 설계가 도입되면서 이러한 기능이 크게 확장되었다.
이제 NVLink 도메인은 최대 72개의 NVIDIA Blackwell GPU를 지원할 수 있으며, GPU당 통신 속도는 1.8TB/s에 달해 최첨단 400Gbps 이더넷 표준보다 36배 빠르다. NVLink 도메인의 크기와 속도에서의 이러한 발전은 GPT-MoE-1.8T와 같은 수조 개 매개변수 모델의 훈련과 추론 속도를 각각 최대 4배와 30배까지 가속화할 수 있다


인프라 혁신 및 기여 가속화
이처럼 대규모 GPU NVLink 도메인을 단일 랙에 수용하려면, GPU와 NVSwitch 칩을 포함하는 컴퓨트 및 스위치 섀시와 함께 랙 아키텍처에 대한 정밀한 전기적 및 기계적 수정이 필요하다.
NVIDIA는 기존 설계 원칙을 기반으로 활용도를 높이고 GB200 NVL72의 높은 컴퓨팅 밀도와 에너지 효율성을 지원하기 위해 파트너들과 긴밀히 협력해 왔다. 랙, 트레이 및 내부 구성 요소 설계는 NVIDIA MGX 아키텍처에서 파생되었다. 오늘날 NVIDIA는 이러한 설계를 OCP(Open Compute Project)와 공유하고 개방하여 AI를 위한 모듈형 및 재사용 가능한 고컴퓨팅 밀도 인프라를 구축하는 데 기여하고 있다.
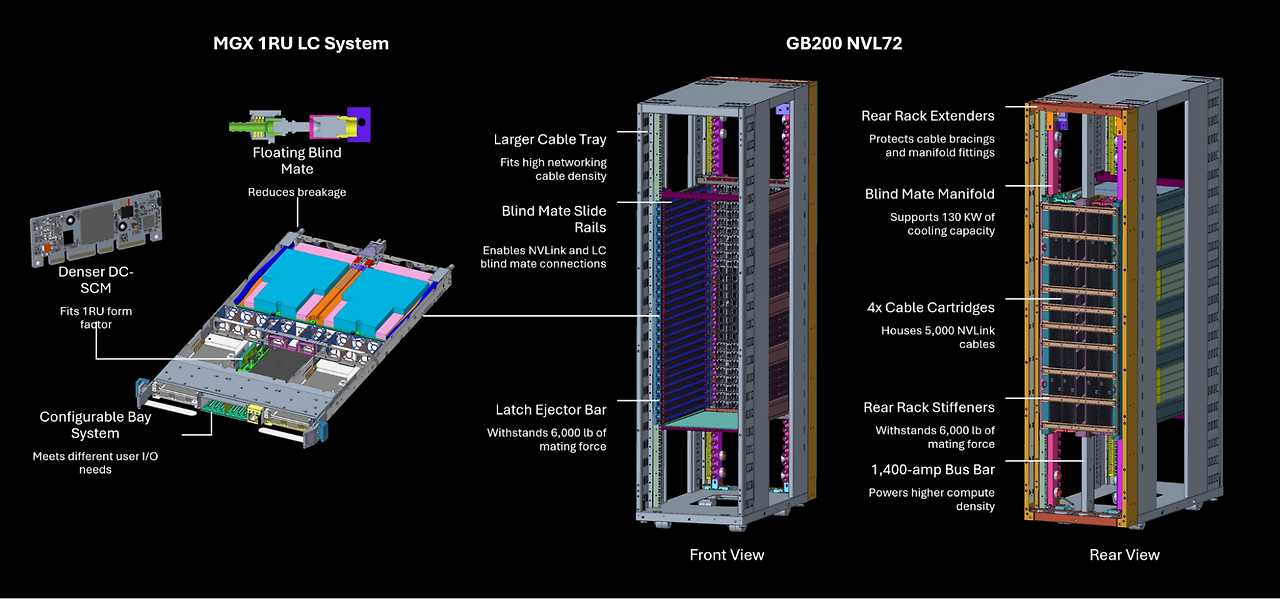
랙 보강
하나의 랙에 18개의 컴퓨트 트레이, 9개의 스위치 트레이, 5,000개 이상의 구리 케이블을 지원하는 4개의 NVLink 카트리지를 효율적으로 수용하기 위해 NVIDIA는 기존 랙 설계를 다음과 같이 주요 부분에서 수정했다:
- 랙 내부에서 1RU 폼 팩터로 19인치 EIA 장비를 지원하도록 수정하여 I/O 케이블링 공간을 두 배로 늘리고 트레이 밀도를 향상
- 100파운드 이상의 강철 보강재를 추가해 구성 요소와 프레임 간 발생하는 6,000파운드의 접합력을 견딜 수 있도록 랙의 강도와 안정성을 대폭 향상
- 케이블 브레이싱과 매니폴드 피팅을 보호하기 위한 후면 랙 확장 기능 도입으로 해당 요소의 수명과 올바른 작동 보장
- 블라인드 메이트 슬라이드 레일과 잠금 기능을 도입해 NVLink 설치, 액체 냉각 시스템 통합, 블라인드 메이트 커넥터를 사용한 유지보수를 보다 쉽게 지원
이러한 랙 재설계는 공간 활용도를 최적화하고 구조적 완전성을 강화하며 시스템의 신뢰성과 유지보수성을 향상시킨다.
고용량 버스 바
랙의 높은 컴퓨팅 밀도와 전력 요구 사항을 충족하기 위해, 기존 ORV3와 동일한 폭을 유지하면서 프로파일을 깊게 설계한 새로운 고용량 버스 바 사양을 개발했다.
새로운 설계는 1,400암페어의 전류를 지원하여 기존 표준보다 암페어 수를 두 배로 증가시켰다. 이 개선 사항은 랙 내부에 추가적인 수평 공간을 요구하지 않고도 현대 고성능 컴퓨팅 환경에서의 높은 전력 수요를 효과적으로 처리할 수 있도록 보장한다.
NVLink 카트리지
NVLink 도메인 내 72개의 NVIDIA Blackwell GPU 간 고속 통신을 지원하기 위해, 랙 후면에 수직으로 장착되는 4개의 NVLink 카트리지를 특징으로 하는 새로운 설계를 구현했다.
이 카트리지는 5,000개 이상의 구리 케이블을 수용하며, 총 All-to-All 대역폭 130TB/s와 AllReduce 대역폭 260TB/s를 제공한다.
이 설계를 통해 도메인의 모든 GPU는 GPU당 1.8TB/s의 속도로 다른 모든 GPU와 통신할 수 있어 시스템 성능이 크게 향상됩니다. 이 기여의 일환으로 NVLink 카트리지에 대한 볼륨 정보와 정확한 장착 위치를 제공하여 향후 고성능 컴퓨팅 인프라 구현과 개선에 기여한다.
액체 냉각 매니폴드와 플로팅 블라인드 메이트
랙에서 요구되는 120KW 냉각 용량을 효율적으로 관리하기 위해 직접 액체 냉각 기술을 구현했다. 기존 설계를 기반으로 다음과 같은 두 가지 주요 혁신을 도입했다:
- 효율적인 냉각을 제공할 수 있는 향상된 블라인드 메이트 액체 냉각 매니폴드 설계.
- 컴퓨트 및 스위치 트레이 모두에 냉각수를 효과적으로 분배하는 새로운 플로팅 블라인드 메이트 트레이 연결 방식 개발. 이를 통해 액체 퀵 디스커넥트가 랙 내에서 정렬되고 안정적으로 접합되는 능력을 크게 개선.
이러한 향상된 액체 냉각 솔루션을 활용하여 현대 고성능 컴퓨팅 환경의 높은 열 관리 요구를 충족시키며, 랙 구성 요소의 최적 성능과 내구성을 보장한다.
컴퓨트 및 스위치 트레이 기계적 폼 팩터
랙의 높은 컴퓨팅 밀도를 수용하기 위해 1RU 액체 냉각 컴퓨트 및 스위치 트레이 폼 팩터를 도입했습니다. 또한, 기존 표준보다 10% 더 작은 새로운 고밀도 DC-SCM(데이터 센터 보안 제어 모듈) 설계를 개발했다.
추가적으로 후면 패널 공간을 극대화하기 위해 좁은 버스 바 커넥터를 구현했다.
이와 더불어 다양한 사용자 I/O 요구 사항에 유연하게 적응할 수 있는 컴퓨트 트레이용 모듈형 베이 디자인을 생성했다. 이러한 개선 사항은 컴퓨트 및 스위치 트레이의 1RU 액체 냉각 폼 팩터를 지원하며, 랙의 컴퓨팅 밀도와 네트워킹 기능을 크게 향상시키는 동시에 효율적인 냉각 및 다양한 사용자 요구에 대한 적응성을 보장한다.
새로운 NVIDIA GB200 NVL72 참조 아키텍처
OCP에서 NVIDIA는 전력 및 냉각 기술의 선두 주자이자 고밀도 컴퓨팅 데이터 센터 설계, 구축, 유지보수 전문가인 Vertiv와 함께 새로운 GB200 NVL72 참조 아키텍처를 발표했다. 이 새로운 레퍼런스 아키텍처는 NVIDIA Blackwell 플랫폼을 배치하려는 CSP(클라우드 서비스 제공업체)와 데이터 센터의 구현 시간을 크게 단축할 것으로 보인다.
새로운 레퍼런스 아키텍처는 데이터 센터 업체들이 GB200 NVL72에 맞는 전력, 냉각 및 공간 설계를 처음부터 자체적으로 개발할 필요가 없게 도와준다. Vertiv의 공간 절약형 전력 관리 및 에너지 효율적인 냉각 기술 전문성을 활용하여 데이터 센터 업체들은 7MW 규모의 GB200 NVL72 클러스터를 전 세계적으로 배치할 수 있다. 이를 통해 구현 시간을 최대 50% 단축하고, 전력 및 공간 사용량을 줄이며 냉각 에너지 효율성을 높일 수 있게 해준다.
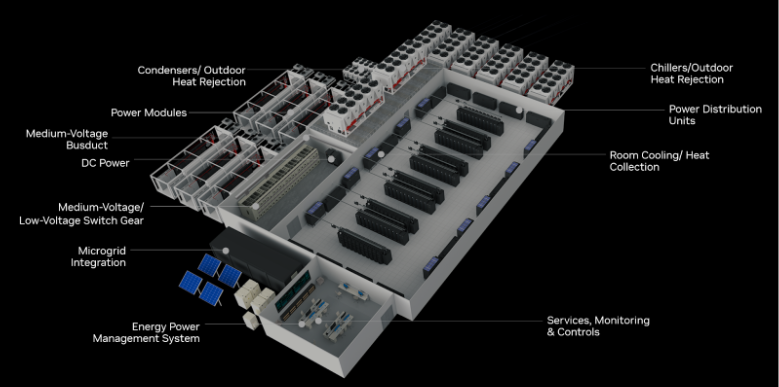
Vertiv와 NVIDIA Blackwell 플랫폼 기반의 데이터 센터 혁신
Vertiv는 NVIDIA Blackwell 플랫폼을 기반으로 데이터 센터 인프라(DCI: Data Center Infrastructure) 제공업체들이 어떻게 발전과 혁신을 이루고 있는지를 보여주고 있다.
현재 Amphenol, Auras, Astron, AVC, Beehe, Bellwether, BizLink, Boyd, Chenbro, Chengfwa, CoolIT, Cooler Master, CPC, Danfoss, Delta, Envicool, Flex, Foxconn, Interplex, JPC, Kingslide, Lead Wealth, LiteOn, LOTES, Luxshare, Megmeet, Molex, Motivair, Nidec, Nvent, Ourack, Parker, Pinda, QCT, Refas, Readore, Repon, Rittal, Sanyo Denki, Schneider Electronic, Simula, Staubli, SUNON, Taicheng, TE Connectivity, Yuans Technology를 포함한 40개 이상의 DCI 업체들이 Blackwell 플랫폼을 기반으로 구축 및 혁신을 이루고 있다.
또한, AsRock Rack, ASUS, Dell Technologies, GIGABYTE, Hewlett Packard Enterprise, Hyve, Inventec, MSI, Pegatron, QCT, Supermicro, Wiwynn과 같은 시스템 파트너들이 Blackwell 제품을 기반으로 다양한 서버를 개발하고 있다.
결론
많은 논란이 있지만, NVIDIA GB200 NVL72 설계는 현대 고성능 컴퓨팅 데이터 센터의 진화에서 중요한 이정표가 될 수 있는 제품이다. 증가하는 AI 모델의 학습 및 서비스 요구와 높은 GPU 간 통신 문제를 해결함에 있어서, 에너지 효율적인 고성능 컴퓨팅 플랫폼의 데이터 센터의 표준으로 NVIDIA가 만들고자 하는 제품이다.
하지만, NVIDIA는 GB200 NVL72 설계가 완벽하지 않다는 것을 알고 있으며, 많은 설치 사례를 빠르게 구현함으로써, 잠재된 문제를 발견해내고 이를 해결할 수 있는 지혜를 AI컴퓨팅의 여러 주체들로부터 도움을 받고 싶어한다. 그것이 현실적으로 가장 빠르면서 유일한 해결책이기 때문이다. NVIDIA는 과거 다른 제품의 개발 사례와 경험에서 이러한 것을 잘 알고 있다. 그래서 개방형 생태계 내 협업의 중요성을 강조하고 있는 것이다. NVIDIA는 OCP 커뮤니티를 활성화 시킴으로써, GB200 NVL72 설계 기여를 활용하고 이를 기반으로 구축할 방식을 기대하고 있다.
보다 상세한 내용은 아래 document에서 참조할 수 있다.
출처: NVIDIA technical blog
뜨리스땅
'반도체, 소.부.장.' 카테고리의 다른 글
| 서버용 CPU 시장의 판도를 바꾸고 있는 AMD의 V-cache 기술 (0) | 2025.02.08 |
|---|---|
| NVIDIA의 Blackwell 발열 이슈는 해결 가능할까? (2) | 2025.01.19 |
| 자동차 반도체 아키텍처와 국제 표준 - ISO26262 (1) | 2024.12.28 |
| 구글 딥마인드, 반도체를 설계하는 AI - 'AlphaChip' 공개 (2) | 2024.09.30 |
| AI반도체 설계 시 중요한 부분: 메모리 계층 구조 (5) | 2024.09.28 |




댓글