1. 성능과 효율성의 통합
Intel의 차세대 클라이언트 CPU 아키텍처인 Panther Lake, 즉 '코어 울트라 시리즈 3' 제품군에 대해 기술적인 측면으로 좀더 심층 분석을 해보려 합니다.
Panther Lake의 핵심 설계 목표는 이전 세대 아키텍처의 강점을 전략적으로 융합하는 것입니다. 이는 Lunar Lake의 선도적인 x86 효율성과 Arrow Lake의 고성능을 단일 패키지에 통합하여, 성능과 전력 효율성 사이의 균형을 재정의하려는 기술적 과제에 대한 Intel의 해답입니다.

이 아키텍처는 차세대 모바일 및 데스크톱 플랫폼을 설계하는 시스템 설계자와 하드웨어 엔지니어에게 전례 없는 수준의 확장성과 유연성을 제공함으로써 중요한 기술적 이정표를 제시합니다. Panther Lake는 CPU 코어, 신경망 처리 장치(NPU), 그리고 전력 관리에 이르는 다방면에 걸쳐 중요한 혁신을 도입했습니다.
2. 모듈형 아키텍처: 분산 설계와 고급 패키징
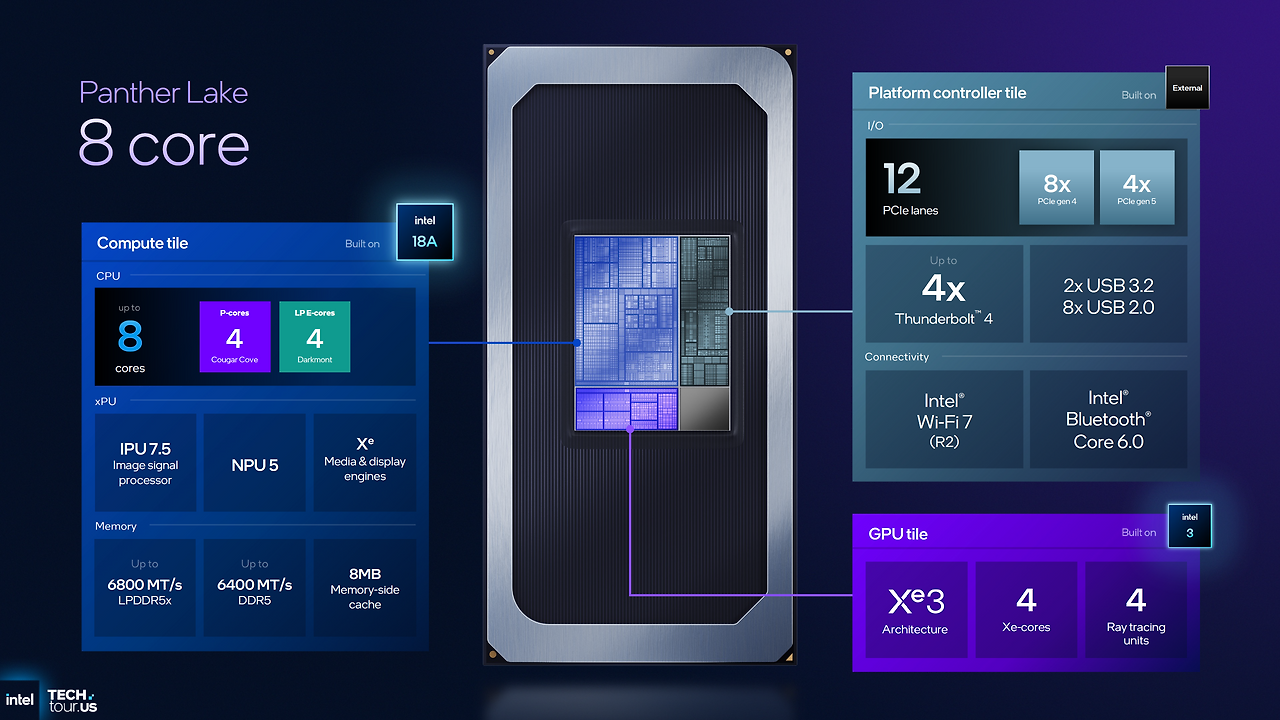
Panther Lake 아키텍처의 물리적 기반은 전략적으로 중요한 모듈형 칩렛(disaggregated) 설계에 있습니다. 이 접근 방식은 다양한 공정 기술로 제작된 여러 개의 전문화된 '타일(tile)'을 단일 패키지에 통합함으로써, 제품 개발의 유연성과 확장성을 극대화합니다.
이는 Intel이 각 기능에 가장 최적화된 공정을 선택하고, 시장 요구에 맞춰 신속하게 제품 구성을 변경할 수 있게 하는 핵심 전략입니다.

Panther Lake를 구성하는 핵심 요소는 다음과 같습니다.
- 분산 타일(Disaggregated Tiles): Panther Lake는 여러 개의 독립적인 타일로 구성됩니다. 여기에는 최신 Intel 18A 공정으로 제작된 컴퓨트 타일, Intel 3 또는 TSMC N3E 공정을 활용하는 그래픽스 타일, TSMC N6 기반의 플랫폼 컨트롤러 타일, 그리고 이들을 연결하는 Intel 1227.1 공정의 베이스 타일이 포함됩니다.
- Foveros 패키징 기술: Intel의 고급 Foveros-S 2.5D 패키징 기술은 이러한 다중 타일을 수직 및 수평으로 연결하여 하나의 고성능 프로세서로 통합하는 역할을 합니다. 이는 타일 간의 고대역폭, 저지연 통신을 가능하게 하는 핵심 기술입니다.
- Scalable Fabric Gen2: 이 IP 및 파티션에 구애받지 않는 코히런트 패브릭은 Panther Lake의 확장성을 뒷받침합니다. 서로 다른 IP 블록과 타일들이 원활하게 데이터를 교환하고 일관성을 유지할 수 있도록 하여, 다양한 IP의 혼합 및 매칭을 통한 맞춤형 설계가 가능해집니다.
- 필러 타일(Filler Tile): 패키지 내 빈 공간을 채우는 필러 타일은 단순한 공간 채우기 이상의 중요한 역할을 합니다. Intel의 Robert Hallock(VP & General Manager Client AI and Technical Marketing)에 따르면, 필러 타일은 "히트스프레더가 아래에서 기계적으로 지지될 수 있도록 균일하고 공동 없는 표면을 제공"하여 히트스프레더의 휨이나 손상을 방지하고 기계적 무결성을 유지합니다.

이처럼 정교하게 설계된 물리적 구조는 Panther Lake의 핵심인 차세대 CPU 코어의 성능을 안정적으로 뒷받침하는 견고한 토대가 됩니다.
3. CPU 코어 아키텍처 혁신
3.1 개요: 차세대 하이브리드 컴퓨팅
Panther Lake는 성능 코어(P-Core), 효율 코어(E-Core), 저전력 효율 코어(LP-E Core)로 구성된 3-way 하이브리드 아키텍처를 한 단계 더 발전시켰습니다.

이전 세대인 Meteor Lake는 LP-E 코어의 수가 부족했고, Lunar Lake는 MT 처리량에 한계가 있었던 반면, Panther Lake는 이 두 아키텍처의 장점을 결합하여 단일 스레드 성능, 다중 스레드 처리량, 그리고 전력 효율성 모두를 최적화했습니다. 특히, 컴퓨트 타일 전체가 Intel의 최신 Intel 18A 공정 노드를 기반으로 제작되어 성능과 효율성의 새로운 기준을 제시합니다.

Cougar Cove P-Core와 Darkmont E-Core 및 LP E-Core는 각 제품 세대에 거쳐서 지속적으로 upgrade 되어 오고 있습니다. Pather lake에서의 각 core의 발전에 대해 자세히 살펴보겠습니다.

3.2 Cougar Cove P-Core: 성능 최적화
Cougar Cove P-Core는 Arrow Lake와 Lunar Lake에 사용된 Lion Cove 아키텍처의 진화된 형태입니다. Cougar Cove는 Lion Cove의 기본 구조를 유지하면서 18A 공정에 맞게 최적화되어 더 높은 효율성을 달성하는 데 중점을 두었습니다.
Intel은 다음과 같은 세 가지 핵심 영역에서 개선을 이루었습니다.
- 메모리 디스앰비규에이션 (Memory Disambiguation): 프로그램 실행 시 발생하는 로드(load)와 스토어(store) 명령어 간의 연관성을 예측하는 능력이 향상되었습니다. 이 예측이 정확할수록 불필요한 대기 시간을 줄이고 로드 명령을 더 효율적으로 스케줄링할 수 있어, 직접적인 IPC(Instructions Per Clock) 및 성능 향상으로 이어집니다.

- TLB 향상 (TLB Enhancements): 18A 공정의 이점을 활용하여 TLB(Translation Lookaside Buffer) 용량을 1.5배 늘렸습니다. TLB는 가상 메모리 주소를 물리적 주소로 변환하는 속도를 높이는 캐시로, 용량이 커지면 최신 애플리케이션과 같이 복잡하고 큰 메모리 공간을 사용하는 워크로드를 더 빠르고 안정적으로 실행할 수 있습니다.

- 분기 예측 (Branch Prediction): 분기 예측은 CPU 성능의 핵심 요소입니다. Cougar Cove는 기본 알고리즘을 개선하고 다단계 예측기(multi-level predictor)를 도입하여 예측 정확도를 높였습니다. 이는 잘못된 예측으로 인한 파이프라인 플러시를 줄여 성능을 향상시키는 동시에, 더 빠르고 낮은 지연 시간으로 예측을 수행하여 에너지 효율성까지 개선합니다.

Cougar Cove의 주요 아키텍처 사양은 다음과 같습니다.
- 8-Wide Decode
- 4-Wide MSROM
- 12-Wide uOP Cache
- 8-Wide Allocate/Rename/Move Elimination/Zero IDIOM
3.3 Darkmont E-Core: 효율성과 처리량의 도약
Darkmont E-Core는 Skymont 아키텍처를 기반으로 한 중요한 발전입니다. 가장 주목할 만한 성과는 동일 전력 소비 조건에서 이전 세대 P-Core인 Raptor Cove보다 더 빠른 성능을 제공한다는 점입니다. 이 성과는 E-Core가 단순한 배경 작업 처리용 코어를 넘어, 이전에는 P-Core의 영역이었던 워크로드까지 처리할 수 있는 강력한 연산 자원으로 진화했음을 의미하며, 이는 성능 대비 전력 효율 계산법을 근본적으로 바꾸는 전략적 전환점입니다.

Darkmont E-Core의 네 가지 주요 개선 사항은 다음과 같습니다.
- 분기 예측 (Branch Prediction): 용량 증가와 알고리즘 개선을 통해 예측 정확도를 높였고, 루프 스트림 감지(Loop Stream detection)와 같은 새로운 기능을 도입하여 반복적인 코드 실행 시 프론트엔드를 비활성화함으로써 상당한 에너지를 절약하고 안정적인 성능을 제공합니다.
- 동적 프리페처 제어 (Dynamic Prefetcher Controls): 워크로드의 변화에 동적으로 반응하는 프리페처 제어 기능을 강화했습니다. 이는 필요한 데이터를 미리 메모리에서 가져오는 프리페칭 작업을 최적화하여 에너지 효율성을 높이고 시스템 응답성을 개선합니다.
- 나노코드 성능 (Nanocode Performance): 복잡한 x86 명령을 처리하기 위해 전통적으로 사용되던 마이크로코드 대신, 일부 명령을 하드웨어(PLA)에 직접 내장하는 Intel 고유의 나노코드 방식을 개선했습니다. 이는 각 프론트엔드 클러스터에서 병렬 처리가 가능하게 하여 지연 시간, 대역폭, 다이 면적을 모두 절약하고 성능을 크게 향상시킵니다.
- 메모리 디스앰비규에이션 (Memory Disambiguation): P-Core 팀과의 기술 공유를 통해 E-Core 역시 메모리 접근 효율성을 높여, 더 안정적인 성능을 확보했습니다.

Darkmont의 업데이트된 아키텍처 사양은 다음과 같습니다.
- 9-wide Decode (3x3 클러스터)
- 96개 항목 Uop 큐
- 416개 항목 Out-of-Order Window
이러한 코어 수준의 연산 능력은 상응하는 데이터 공급 능력을 갖춘 캐시 및 메모리 서브스트레이트에 의해 뒷받침될 때 비로소 완성됩니다.
4. 메모리 및 캐시 서브시스템
Panther Lake의 캐시 및 메모리 서브시스템은 새롭게 설계된 코어 아키텍처의 잠재력을 최대한 발휘하도록 설계되었습니다. 지연 시간을 줄이고 대역폭을 향상시키는 것은 개별 코어의 성능을 넘어 전체 시스템의 응답성과 처리량을 결정하는 전략적으로 중요한 요소입니다.

주요 구조적 변화와 그 이점은 다음과 같습니다.
- 통합 L3 캐시 링: 8개의 E-Core 클러스터가 L3 캐시 링에 직접 연결됩니다. 이를 통해 P-Core와 E-Core가 18MB의 대용량 L3 캐시를 공유하게 되어, 코어 간 데이터 공유 시 지연 시간을 크게 줄이고 다중 스레드 워크로드의 성능을 향상시킵니다. 이전 Lunar Lake 아키텍처에서는 LP-E 코어가 별도의 타일에 위치하여 컴퓨트 타일의 L3 캐시 링과 동일한 지연 시간 이점을 누릴 수 없었던 한계를 극복한 설계입니다.
- LP-E 코어 L2 캐시 확장: 저전력 작업을 담당하는 LP-E 코어 클러스터의 L2 캐시가 4MB로 두 배 증가했습니다. 이는 LP-E 코어가 더 많은 작업을 독립적으로 처리하고, 메인 컴퓨트 타일을 깨우는 빈도를 줄여 시스템 전체의 유휴 전력 소비를 낮추는 데 기여합니다.
- 메모리 사이드 캐시 (Memory-Side Cache): SoC 타일에 8MB의 온다이 캐시가 위치합니다. 이 캐시는 메인 메모리(DRAM)로의 접근 트래픽을 줄여 전력 소비를 낮추고, 시스템 전체의 메모리 지연 시간과 유효 대역폭을 개선하는 효과를 가져옵니다.
- 캐시 전용 파워 레일: 캐시 전용 전력 레일을 도입하여 캐시 클럭이 이전 세대의 한계였던 3.5GHz를 넘어 작동할 수 있게 되었습니다. 이를 통해 더 많은 워크로드를 더 높은 동작 지점에서 실행하여 성능을 극대화할 수 있습니다.

각 코어 유형별 캐시 구성은 다음과 같습니다.
| 코어/클러스터 유형 | L2 캐시 | L1 캐시 |
| Cougar Cove P-Core | 3 MB | 256 Kb (192KB L1D + 48KB L0D) |
| Darkmont E-Core Cluster | 4 MB | 96 Kb (64KB L1I + 32KB L0D) |
최적화된 하드웨어는 지능적인 소프트웨어 제어와 결합될 때 최고의 성능을 발휘합니다. 다음으로 Thread Director와 전력 관리 기술에 대해 알아보겠습니다.
5. 지능형 워크로드 스케줄링 및 전력 관리
Panther Lake의 복잡하고 강력한 하이브리드 아키텍처를 효과적으로 활용하기 위해서는 지능적인 워크로드 스케줄러인 Thread Director의 역할이 매우 중요합니다. 올바른 워크로드를 올바른 유형의 코어에 실시간으로 할당하는 것은 최고의 성능과 최적의 전력 효율성 사이의 균형을 맞추는 핵심 기술입니다.

Panther Lake에 탑재된 Thread Director는 새로운 아키텍처에 맞춰 업데이트된 분류 모델을 사용합니다. 기본적인 스케줄링 정책은 가벼운 작업을 LP-E 코어에서 시작하고, 작업량이 늘어나면 E-코어, 그리고 최종적으로 최대 성능이 필요할 때 P-코어로 순차적으로 작업을 이동시키는 방식을 채택하여 효율성을 극대화합니다.

특히 GPU 부하가 높은 게이밍 시나리오에서는 특화된 스케줄링 최적화가 적용됩니다. 시스템이 GPU 병목 상태(GPU-bound)에 있다고 판단되면, Thread Director는 그래픽 드라이버로부터 힌트를 받아 게임 관련 스레드를 P-코어가 아닌 E-코어에서 먼저 시작하도록 선제적으로 유도합니다. 이 방식은 P-코어의 전력 소비를 억제하여 GPU에 더 많은 전력 헤드룸을 확보해주며, 이를 통해 최종적으로 최대 10%의 프레임률 향상을 달성할 수 있습니다.

또한, "Intelligent Experience Optimizer"라는 새로운 전력 관리 도구가 도입되었습니다. 이 도구는 사용자가 수동으로 윈도우의 전원 모드를 조정할 필요 없이, 시스템이 더 많은 성능을 필요로 할 때 자동으로 '균형' 모드에서 '성능' 모드로 전력 프로필을 동적으로 조정합니다. 이를 통해 유사한 전력 예산 내에서 최대 19-20%의 추가 성능을 제공합니다.
범용 컴퓨팅 외에도, AI 가속은 현대 CPU의 핵심 요소가 되었습니다. 다음으로 Panther Lake의 NPU5에 대해 살펴보겠습니다.
6. NPU5: 차세대 AI 가속
Panther Lake에 탑재된 NPU5는 이전 세대인 Lunar Lake의 NPU4를 기반으로, 면적 효율성과 최적화에 중점을 두고 발전한 차세대 AI 가속기입니다. Intel은 NPU4의 이중 Neural Compute Engine(NCE) 설계가 비효율적임을 확인하고, NPU5에서는 이를 단일 엔진으로 간소화하는 대신 MAC(Multiply-Accumulate) 어레이의 처리량을 두 배로 늘리는 방식으로 재설계했습니다.

이 구조적 개선을 통해 단위 면적당 AI 연산 성능(TOPS/area)을 40% 이상 개선하여 더 효율적인 AI 가속을 가능하게 했습니다.
NPU5의 주요 기술적 특징은 다음과 같습니다.
- FP8 형식 지원: Intel NPU 최초로 FP8 데이터 형식을 지원합니다. 이는 기존의 INT8, FP16과 함께 AI 모델의 정밀도와 성능 사이에서 더 넓은 선택지를 제공하며, INT8, FP8, FP16 연산을 병렬로 동시에 처리할 수 있어 유연성을 극대화합니다.
- 성능 수치: NPU5는 단독으로 약 50 TOPS(Trillion Operations Per Second)의 AI 연산 성능을 제공합니다. 이는 CPU(10 TOPS), GPU(120 TOPS)의 성능을 포함한 전체 플랫폼에서 총 180 TOPS에 달하는 강력한 AI 처리 능력을 의미합니다.

NPU 세대별 TOPS 성능 발전 과정은 다음과 같습니다.
- NPU1: 0.5 TOPS
- NPU2: 7.0 TOPS
- NPU3 (Meteor Lake): 11.5 TOPS
- NPU4 (Lunar Lake): 48.0 TOPS
- NPU5 (Panther Lake): ~50.0 TOPS
이러한 아키텍처 개선이 실제 성능 수치로 어떻게 나타나는지 다음 섹션에서 확인해 보겠습니다.
7. 성능 벤치마크 및 향상
이 섹션에서는 Panther Lake의 아키텍처 개선이 실제 워크로드에서 어떤 정량적 성능 향상으로 이어지는지 SPECrate 2017 (INT) 벤치마크 결과를 기반으로 분석합니다.

7.1 단일 스레드(ST) 성능
단일 스레드 성능은 시스템의 응답성을 결정하는 중요한 척도입니다. Panther Lake는 동일한 전력 소비 조건에서 Lunar Lake 및 Arrow Lake와 비교하여 10% 더 높은 성능을 제공합니다. 반대로, 동일한 성능 수준을 유지할 경우 40% 더 낮은 전력을 소비하여 모바일 장치의 배터리 수명을 크게 향상시킬 수 있습니다.

7.2 다중 스레드(MT) 성능
다중 스레드 성능에서 Panther Lake의 진정한 강점이 드러납니다. Lunar Lake 대비 동일 전력에서 50% 이상 높은 성능을 제공하며, 고성능을 지향하는 Arrow Lake와 비교해서도 유사한 성능 수준에서 30% 더 낮은 전력을 소비합니다. 이는 P-Core, E-Core, LP-E 코어의 조화로운 작동과 효율적인 캐시 서브시스템이 만들어낸 결과입니다.
이러한 인상적인 성능 향상은 플랫폼 수준의 지원, 특히 메모리와 연결성 없이는 불가능합니다.
8. 플랫폼 유연성: 메모리 지원 및 연결성
Panther Lake는 코어 성능뿐만 아니라 시스템 통합의 유연성과 최신 I/O 표준 지원을 통해 전체 플랫폼의 가치를 높입니다.

메모리 지원과 관련하여 가장 큰 변화는 Lunar Lake의 MoP(Memory-on-Package) 설계에서 벗어나 표준 PCB 메모리 설계를 다시 채택한 점입니다.
MoP 설계는 OEM에게 비용 절감 효과를 제공했지만, Intel이 기대했던 비용 확장성(cost scaling)을 달성하지는 못했습니다.

따라서 Panther Lake는 OEM(제조사)에게 특정 메모리 구성에 얽매이지 않고 제품의 목표 가격대와 성능에 맞춰 다양한 메모리 표준, 속도, 용량을 선택할 수 있는 유연성을 제공합니다. 이는 비용 최적화와 제품 라인업 다각화에 큰 이점을 줍니다.
지원되는 메모리 표준과 속도를 이전 세대와 비교하면 다음과 같습니다.
| 제품군 | DDR5 지원 속도 | LPDDR5/x 지원 속도 |
| Panther Lake | DDR5-7200 | LPDDR5-9600 |
| Arrow Lake | DDR5-6400 | LPDDR5-8400 |
| Lunar Lake | 미지원 | LPDDR5-8533 |
또한 Panther Lake 플랫폼에는 두 가지 주요 무선 연결 기술 업그레이드가 통합되었습니다.
- Wi-Fi 7 R2: Whale Peak 2 통합 솔루션을 통해 제공되며, 여러 링크의 리소스를 동적으로 관리하는 Multi-Link Reconfiguration과 같은 새로운 기능을 지원하여 더 빠르고 안정적인 무선 연결을 제공합니다.
- Bluetooth LE Audio: 진정한 무선 스테레오와 멀티 스트림 오디오를 지원하며, 기존 대비 최대 50% 낮은 전력 소비로 액세서리의 배터리 수명을 크게 늘립니다.

9. 다이 구성 및 결론
Panther Lake는 세 가지 주요 다이 구성을 통해 저전력 모바일 시장부터 고성능 게이밍 및 크리에이터 시장까지 폭넓은 제품군을 포괄하는 뛰어난 확장성을 달성합니다. 각 구성은 목표 시장에 최적화된 CPU, GPU, 메모리 지원을 제공합니다.

세 가지 주요 다이 구성은 다음과 같습니다.
- Panther Lake 8C: 초경량 및 저전력 노트북 시장을 겨냥하여 Lunar Lake 제품군을 대체하는 역할을 합니다. 4개의 P-Core와 4개의 LP-E Core로 구성되며(E-Core 없음), 그래픽은 Intel 3 공정 기반의 4개의 Xe3 코어를 탑재합니다. 메모리는 최대 LPDDR5x-6800을 지원합니다.
- Panther Lake 16C: 고성능 노트북 시장에서 Arrow Lake-H 제품군을 대체하는 구성입니다. 4개의 P-Core, 8개의 E-Core, 4개의 LP-E Core로 강력한 다중 스레드 성능을 제공합니다. 그래픽은 Intel 3 공정 기반의 4개의 Xe3 코어를 유지하며, 메모리 지원은 최대 LPDDR5X-8533으로 향상됩니다.

- Panther Lake 16C (12 Xe): 플래그십 구성으로, 16코어 CPU 구조는 유지하면서 그래픽 성능을 대폭 강화했습니다. GPU 타일은 TSMC N3E 공정을 기반으로 제작된 12개의 Xe3 코어를 탑재합니다. 이 강력한 GPU 성능을 완벽하게 뒷받침하기 위해 메모리 지원은 최고 속도인 LPDDR5X-9600까지 확장됩니다.

결론적으로, Panther Lake는 Intel 클라이언트 CPU 로드맵에서 중요한 이정표라고 할 수 있습니다. Lunar Lake의 효율성과 Arrow Lake의 성능을 성공적으로 통합하고, Cougar Cove P-Core와 Darkmont E-Core로 구성된 진화된 하이브리드 아키텍처인 것입니다.
여기에 면적 효율성을 극대화한 NPU5, 지능적인 Thread Director 및 전력 관리 기술, 그리고 OEM에게 폭넓은 선택권을 제공하는 플랫폼 유연성까지 갖춤으로써, 향후 Panther Lake는 차세대 PC가 요구하는 모든 요소를 만족시키는 포괄적인 솔루션으로 자리매김할 것으로 보입니다.
출처: wccftech, Intel
뜨리스땅
'반도체, 소.부.장.' 카테고리의 다른 글
| Datacenter를 위해 태어난 인텔의 새로운 서버용 CPU: Xeon 6+ (Clearwater Forest) (0) | 2025.10.19 |
|---|---|
| IBM의 AI 서버 신제품 - Power11: AI 서버 위한 아키텍처 진화 (0) | 2025.10.16 |
| Intel의 Panther Lake - AI PC 시장의 경쟁 구도 재편 (0) | 2025.10.13 |
| 양자 컴퓨팅의 원리는 무엇인가? (1) | 2025.10.04 |
| 스타게이트 프로젝트와 Open AI 샘 알트먼 방한 (1) | 2025.10.02 |




댓글