(2) 2D 카메라로 구성한 Vector Space
Pure Vision 의 핵심은 데이터 학습
다른 센서에 의존하지 않는, 카메라만을 활용한 물체 인지 알고리즘의 핵심은 결국 더 완벽한 데이터 학습을 통한 카메라 단점 보완 및 이종센서의 장점 보완에 달려있을 것이다. 인공지능을 통해 카메라의 2D 이미지를 3D 로 구현하는 과정을 반복적으로 훈련하며 Lidar 와의 괴리를 줄여나가야 할 것이다.
개별 이미지 네트워크는 Vector Space 의 변환 과정에서 Noise 발생
과거에는 단순한 네트워크를 사용하여 개별 이미지를 처리하였다. 하지만 이 방법은 2D 이미지를 Vector Space 로 옮기는 과정에서 Noise 가 발생한다는 문제가 있다. 즉, 개별 이미지를 예측하는 것은 가능하지만, 이미지로 구성된 공간을 예측하는 것은 매우 어려웠던 것이다.

Occupancy Traker 는 하이퍼 파라미터가 복잡
테슬라는 이를 해결하기 위해 2D 이미지를 종합하여 가볍고 작은 지도를 구축하는 Occupancy Tracker 를 개발하였다. 그러나 하이퍼 파라미터의 복잡성으로 인해 개발자가 직접 작업을 수정하는 과정이 필요하며, 심지어 이미지의 출력이 정확하지 않다는 문제가 있었다. 이는 이미지 픽셀의 정확한 깊이(深度)를 측정할 수 없기 때문이다. 또한 한 대의 차량이 여러 대의 카메라에 부분 포착되는 경우, 한 대가 아닌 복수의 차량으로 인식되는 문제도 발생하였다.
Vector Space 라벨링은 2D 이미지를 하나의 신경망에서 융합하여 처리
따라서 이미지 단위가 아니라 Vector Space 단위의 라벨링이 필요했다. 즉, 차량의 위에서 주변을 내려다 보는 듯 360 도 공간을 구성하는 Bird’s eye view 예측이 필요했고, 이에 테슬라는 2D 이미지를 하나의 Neural Net 에 모아 Vector Space 로 옮기는 프로세스를 개발한 것이다. 먼저 모든 2D 이미지를 백본 신경망에서 융합하여 처리하고, Vector Space 로 옮겨진 특징들을 Detection Head 까지 연결할 필요가 있다.
카메라의 왜곡을 보정한 이미지 데이터를 하나의 가상 카메라로 추가
이런 과정을 위해 테슬라의 카메라 특징을 파악하는 것이 요구되었다. 차량에 탑재된 각 카메라의 각도와 위치는 조금씩 다르고, 렌즈가 둥글기 때문에 외곽의 번짐까지 교정하기 위해 카메라의 왜곡을 보정(Calibration)하는 과정을 거친다.
데이터 학습을 통해 2D 의 영상 좌표와 3D 의 공간좌표의 변환관계를 설명하는 파라미터를 찾는 과정으로, 카메라와 Lidar 의 차이를 소프트웨어로 극복하고자 한 것이다. 테슬라는 보정 변환(Rectification Transformation) 과정을 거친 이미지 데이터들을 하나의 가상 카메라로 추가한 Multi-카메라 Network 를 구축했다. 이는 객체 인식뿐만 아니라 Vector 데이터 예측까지 개선했다.
병렬적으로 연산하는 Transformer 모델로 공간을 구성
또한 공간을 구성하는 데에는 Transformer 모델을 사용하였다. 과거에는 CNN(Convolutional Neural Network)를 사용하였는데, 이는 주로 이미지 처리와 패턴 인식에서 사용된다. 이미지 데이터를 변환하지 않고 Raw Data 를 그대로 연산에 활용하는데, Pooling 과정을 통해 데이터의 양을 줄이기 때문에 넓게 적용이 가능하다.
CNN 은 연산을 순차적으로 진행하되, 데이터의 양을 점점 줄여 효율적이라는 장점이 있다. 그러나 이는 데이터 종속의 문제가 발생할 가능성이 있기 때문에 테슬라는 병렬적으로 연산을 수행하는 Transformer 모델을 사용하여 공간을 구성하기 시작했다.
(3) 실시간 Mapping 이면 충분하다.
Lidar 는 HD Map 을 필요로 함
테슬라가 Lidar 를 사용하지 않는 가장 큰 이유는 Lidar 의 경우 HD(High Definition) Map 을 요구하기 때문이다. HD Map 은 1 인치 단위의 정확도와 횡단보도, 신호등, 표지판 등 주변 환경에 충실한 데이터를 제공하기 때문에 정답지를 들고 문제를 푸는 것과 같다.
그러나 차량이 주행할 거리의 HD Map 을 만들고 유지하는 데 필요한 시간과 비용이 매우 크다. 주행 차량이 많아져서 정보의 이용자가 공급자가 된다면 비용이 줄어들겠지만, 그 때까지의 비용과 시간이 크다는 단점이 있다.
테슬라는 SD Map 을 기반으로 딥러닝과 SLAM 을 결합
HD Map 을 사용하지 않는 대신에 SD(Standard Definition) Map 을 기반으로 딥러닝과 SLAM (Simultaneous Localization and Mapping)을 결합한 자율주행 방식을 사용한다. SLAM 이란, 차량의 위치 파악(Localization)과 주변 환경 인식하여 공간 내 지도를 작성하는(Mapping) 것을 동시에(Simultaneous) 하는 기술이다.
Neural Network 에 비디오 모듈을 삽입
앞서 언급하였던 네트워크들은 병렬 구성으로 독립적으로 운영되고 있기 때문에 통합하는 과정이 필요하다. 테슬라는 Neural Network 에 비디오 모듈을 삽입하는 방법을 개발하였다.
Feature Queue 에서 Kinematics, Multi-카메라, 위치 인코딩이 연결
우선 Neural Network 에는 운동학적 데이터를 담고 있는 Ego Kinematics, Multi카메라 Features 와 위치 인코딩이 Feature Queue 에서 연결된다. Features 에는 카메라로 인지한 시간과 공간의 데이터와 IMU 센서를 통해 수집한 운동학적 데이터가 포함된다.
테슬라는 카메라 위주의 자율주행으로 유명하지만, 카메라 외에도 IMU 센서를 함께 사용한다. IMU 센서는 가속도계(Accelerometer), 각속도계(Gyroscope), 지자계(Magnetometer)가 일체형으로 탑재된 센서로 카메라 만으로는 파악하기 어려운 운동학적 데이터를 수집한다.
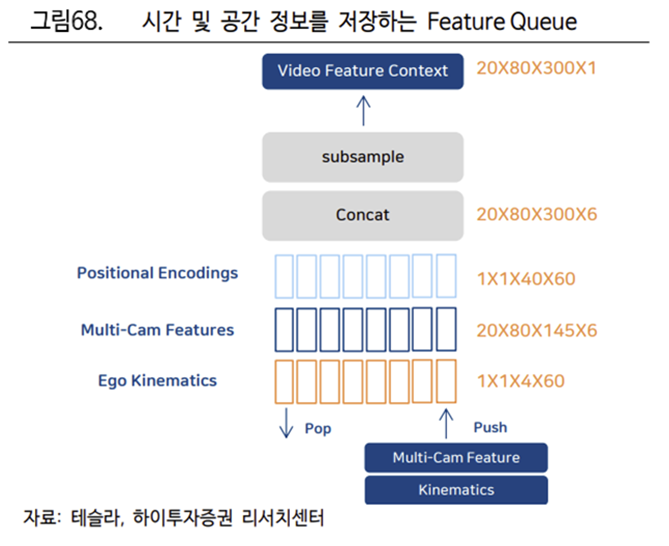
Feature Queue 는 과거의 정보 중 일부 내용을 저장
Feature 들이 연결될 Queue 는 대기열 모듈의 의미로 과거의 정보 중 일부 내용을 저장하는 역할을 의미한다. 즉, 27 밀리초마다 혹은 일정한 거리를 이동할 때마다 대기열에 Feature 를 입력해 시간과 공간의 정보를 저장한다. 이를 통해 차가 주행을 하는 과정에서 일시적으로 차선이 가려지는 경우에도 몇 초 전의 비디오 데이터를 참고하여 차선이 이어질 것이라 예측하는 것이 가능하다.
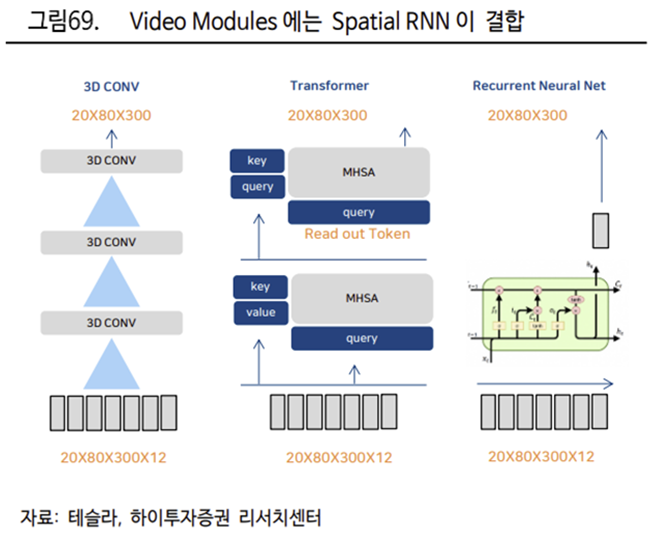
Transformer 모델로 Spatial RNN 업데이트
카메라는 차량 근처의 이미지만 업데이트가 가능하고, IMU 센서는 차량의 위치를 히든 그리드에 통합한다. 그리고 Transformer 모델을 통해 데이터와 그리드를 융합하여 Spatial RNN 을 업데이트한다.
RNN 은 이전 데이터로 이후의 데이터에 대한 중요도를 분석
RNN(Recurrent Neural Network, 순환신경망)은 이전에 입력된 데이터가 이후의 데이터에 영향을 주는 신경망을 의미한다. 즉, 이전의 데이터를 통해 이후의 데이터에 대한 중요도를 분석한다. RNN 을 자율주행에 적용해 각 차량이 근처의 환경을 예측하기 때문에, 여러 차량이 각각 예측한 데이터를 융합해 하나의 지도를 만드는 것 또한 가능하다
이러한 아키텍쳐를 통해 2D 의 이미지로 3D 공간을 구현할 수 있을 뿐만이 아니라 LiDAR 를 사용하는 자율주행 업체들의 가장 큰 단점이었던 실시간 Map 구축과 확장성에 대한 문제까지 해결하는 모습이다.
https://www.youtube.com/watch?v=XLsGkp7mY2c
to be continued
출처: 하이투자증권, 테슬라
뜨리스땅
https://tristanchoi.tistory.com/390
로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 1
테슬라는 21 년 8 월 AI Day 에서 궁극적인 지향점은 ‘전기차를 넘은 인공지능(AI) 및 로봇 회사’이라 언급하면서, 로봇 산업에 대한 의지를 공식적으로 발표하였다. 또한 휴머노이드 로봇 Optimus
tristanchoi.tistory.com
'로보틱스' 카테고리의 다른 글
| 로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 4 (1) | 2023.01.02 |
|---|---|
| 로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 3 (0) | 2023.01.01 |
| 로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 1 (0) | 2023.01.01 |
| 로봇 기업 탐구: 테슬라 vs. 엔비디아 (0) | 2022.12.31 |
| 로봇 기술 탐구: 로봇의 뇌(인공지능) 어디까지 왔나? - 3 (강화학습) (0) | 2022.12.31 |




댓글