로봇 파운데이션 모델 기술 동향
로봇 파운데이션 모델(Robot Foundation Model, RFM)은 로봇 공학 분야에 혁신적 변화를 가져오고 있는 핵심 기술로, GPT와 같은 대규모 언어 모델의 성공을 로봇 분야에 적용하려는 시도입니다. 대규모 다양한 데이터로 사전 학습된 이 모델들은 다양한 로봇 플랫폼과 작업에 일반화될 수 있는 능력을 보여주고 있습니다.

1. Big tech 및 유니콘들의 개발 동향
업계에서는 실용적이고 상용화 가능한 로봇 파운데이션 모델 개발에 집중하고 있으며, 주요 기업들이 대규모 투자와 함께 혁신적인 모델을 발표하고 있습니다.
1.1. Google DeepMind의 RT 시리즈
Google DeepMind는 RT-1, RT-2, RT-X 시리즈를 통해 로봇 파운데이션 모델 분야를 선도하고 있습니다. RT-2는 비전-언어 모델(VLM)을 로봇 제어에 적용한 비전-언어-액션(Vision-Language-Action, VLA) 모델로, 웹 스케일 데이터에서 학습한 지식을 로봇 제어로 전환합니다. RT-2-X는 9개의 서로 다른 로봇 플랫폼 데이터로 학습되어 크로스-엠보디먼트(cross-embodiment) 일반화 능력을 입증했습니다.

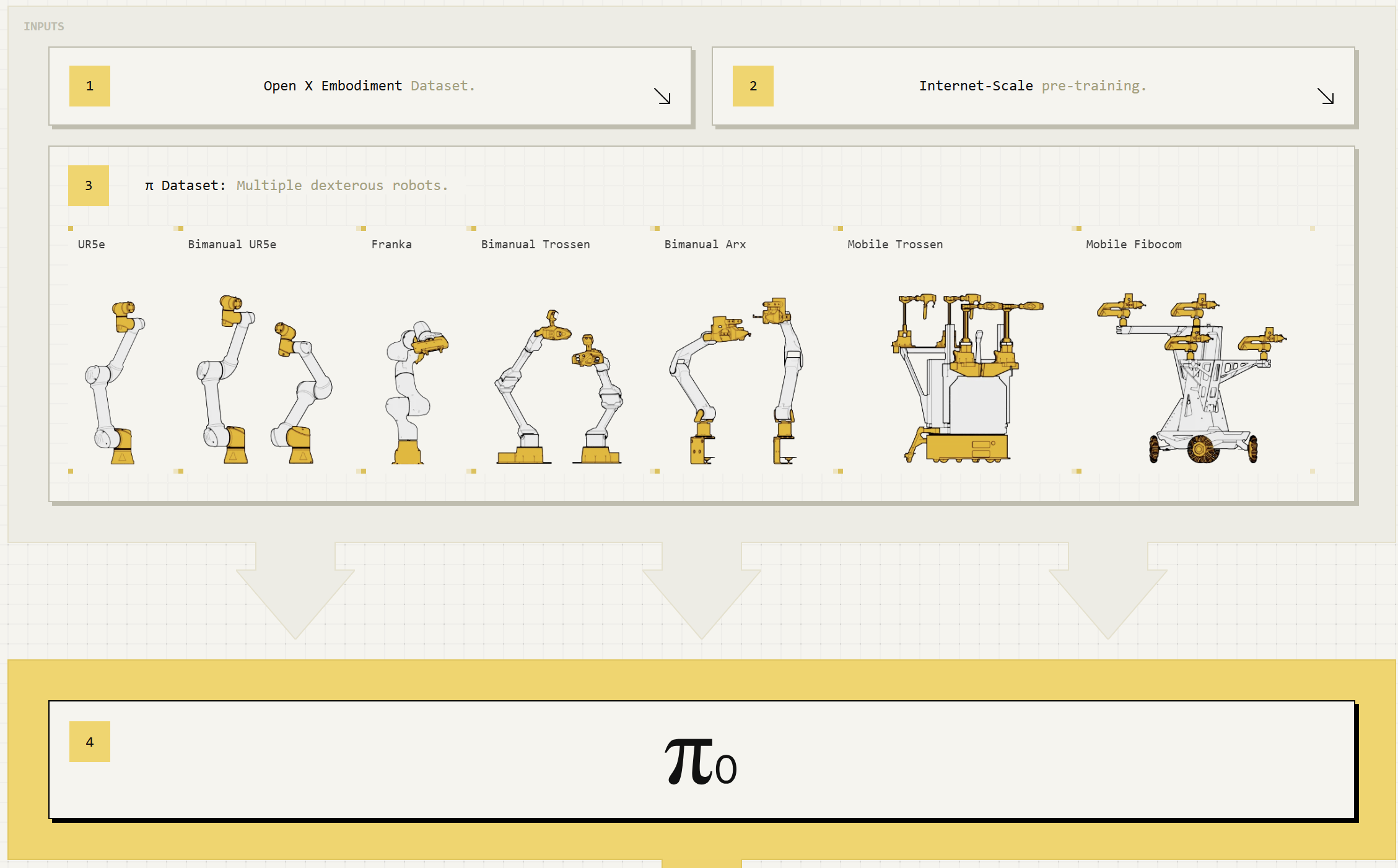
1.2. Physical Intelligence의 π₀ (Pi-Zero)
2024년 10월 공개된 π₀는 7개 로봇 플랫폼과 68개 작업 데이터를 기반으로 학습된 범용 로봇 정책 모델입니다. 인터넷 스케일의 비전-언어 사전학습과 오픈소스 로봇 데이터, 자체 수집한 손재주가 필요한 작업 데이터를 결합했습니다. π₀는 30억 파라미터의 VLM을 시작점으로 하여 실시간 정밀 로봇 제어를 위해 조정되었으며, 플로우 매칭(flow matching) 기반의 액션 전문가 모듈을 통해 정확하고 유창한 조작 기술을 구현합니다.
1.3. NVIDIA Isaac GR00T
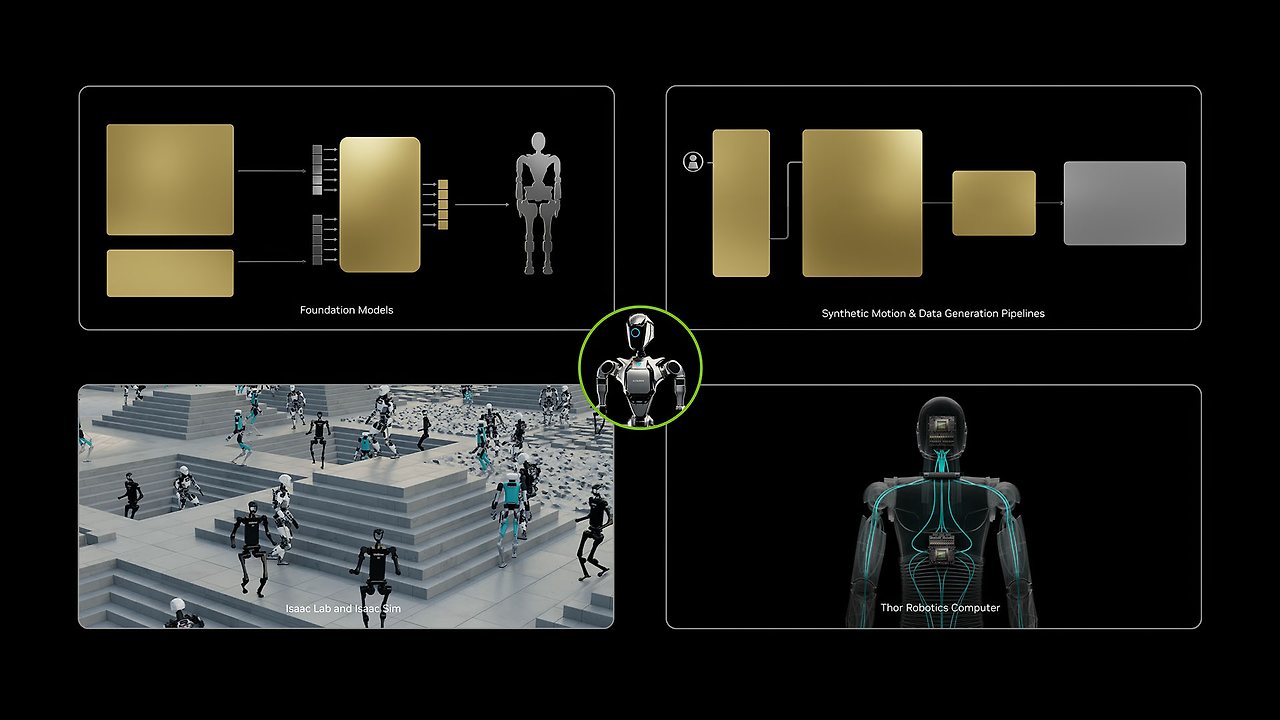
NVIDIA는 2025년 3월 Isaac GR00T N1.5를 오픈소스 파운데이션 모델로 공개했습니다. 이 모델은 언어와 이미지를 포함한 멀티모달 입력을 받아 다양한 환경에서 조작 작업을 수행하는 크로스-엠보디먼트 모델입니다. GR00T N1은 듀얼 시스템 아키텍처를 채택하여 System 1은 빠른 반사적 행동 모델로, System 2는 신중한 의사결정 모델로 작동합니다. 실제 수집 데이터, Isaac GR00T Blueprint로 생성된 합성 데이터, 인터넷 스케일 비디오 데이터로 학습되며, 특정 로봇이나 작업에 대한 후속 학습(post-training)을 통해 맞춤화가 가능합니다.
1.4. Boston Dynamics와 Toyota Research Institute의 LBM
2025년 8월 Boston Dynamics와 TRI는 Atlas 휴머노이드 로봇에 대형 행동 모델(Large Behavior Model, LBM)을 적용한 연구를 공개했습니다. 이 협력은 단일 신경망이 로봇 전체를 직접 제어하여 걷기, 웅크리기, 들기 등 전신 움직임을 결합한 복잡한 작업 시퀀스를 수행하도록 합니다. 기존에는 저수준 보행 제어와 팔의 조작 제어를 분리했지만, LBM은 손과 발을 거의 동일하게 취급하여 통합 제어를 실현합니다.

1.5. Covariant의 RFM-1
2024년 3월 공개된 RFM-1은 80억 파라미터의 트랜스포머로, 텍스트, 이미지, 비디오, 로봇 액션, 센서 데이터를 통합 토큰 공간에서 처리하는 멀티모달 any-to-any 시퀀스 모델입니다. 실제 창고 환경에서 수집된 대규모 멀티모달 데이터셋으로 학습되어 물리 법칙 이해, 세계 모델 구축, 자연어 기반 로봇 프로그래밍 등의 능력을 갖춥니다.

1.6. Skild AI의 Skild Brain
2024년 7월 3억 달러 투자를 유치한 Skild AI는 범용 로봇 두뇌인 Skild Brain을 개발하고 있습니다. 경쟁 모델 대비 1,000배 이상의 데이터로 학습되었으며, 쿼드러페드, 휴머노이드, 테이블탑 암, 모바일 매니퓰레이터 등 다양한 형태의 로봇에 적용 가능한 옴니바디(omni-bodied) 모델을 표방합니다.
https://www.youtube.com/watch?v=lC1M_Zaje9o
1.7. Figure AI의 Helix VLA
Figure AI는 2025년 2월 Helix를 공개했으며, 이는 두 대의 로봇을 동시에 제어하고 상호 협력하도록 지시할 수 있는 차세대 VLA 신경망입니다. System 2는 초당 7-9회 고수준 계획을 수행하고, System 1은 초당 200회 저수준 제어를 담당하는 이중 시스템 구조를 가집니다. Figure 03은 2025년 10월 출시되었으며, Helix를 위해 구축된 차세대 센서 스위트와 핸드 시스템을 특징으로 합니다.
https://www.youtube.com/watch?v=Eu5mYMavctM
2. 학계의 연구 동향
학계는 로봇 파운데이션 모델의 이론적 기반을 강화하고, 새로운 아키텍처와 학습 방법론을 제시하며, 데이터셋 구축과 벤치마크 개발에 주력하고 있습니다.
2.1. VLA 모델 연구
비전-언어-액션 모델은 비전, 언어, 행동 데이터를 통합하여 다양한 작업, 객체, 로봇 형태, 환경에 일반화될 수 있는 정책을 학습합니다. 2024-2025년 VLA 연구는 아키텍처 전환, 모달리티별 처리 기법, 학습 패러다임에 집중하고 있습니다.
OpenVLA는 2024년 6월 공개된 70억 파라미터 오픈소스 VLA 모델로, 97만 개의 실제 로봇 시연 데이터로 학습되었습니다. Llama 2 언어 모델과 DINOv2 및 SigLIP 특징을 융합한 비전 인코더를 결합했으며, RT-2-X(550억 파라미터)를 29개 작업에서 16.5% 절대 성공률로 능가하면서 파라미터는 7배 적습니다.
2.2. 데이터셋과 벤치마크
Open X-Embodiment 데이터셋은 현재까지 가장 큰 오픈소스 실제 로봇 데이터셋으로, 21개 기관의 22개 로봇 플랫폼에서 수집된 100만 개 이상의 실제 로봇 궤적을 포함합니다. 싱글 암부터 바이매뉴얼 로봇, 쿼드러페드까지 다양한 로봇 형태를 아우릅니다.

DROID(Distributed Robot Interaction Dataset)는 북미, 아시아, 유럽의 50명의 데이터 수집자가 12개월간 564개 장면과 86개 작업에서 수집한 76,000개의 시연 궤적(350시간)을 포함합니다. DROID로 학습한 정책은 성능, 강건성, 일반화 능력이 평균 20% 향상되었습니다.

RLBench는 100개의 고유한 손으로 설계된 작업을 특징으로 하는 대규모 벤치마크 및 학습 환경입니다. 모션 플래너를 통해 무한한 데모를 제공하여 강화학습, 모방학습, 멀티태스크 학습, 기하학적 컴퓨터 비전, 특히 few-shot 학습 연구를 촉진합니다.
2.3. 아키텍처 혁신
DiffusionVLA는 자기회귀 추론과 확산 정책을 통합한 프레임워크입니다. 자기회귀 VLA 모델이 정확한 행동 생성이 부족하고 확산 기반 정책이 추론 능력이 없는 한계를 극복하기 위해, 사전학습된 VLM이 가능하게 하는 작업 분해 및 설명 과정인 자기회귀 추론을 활용합니다.
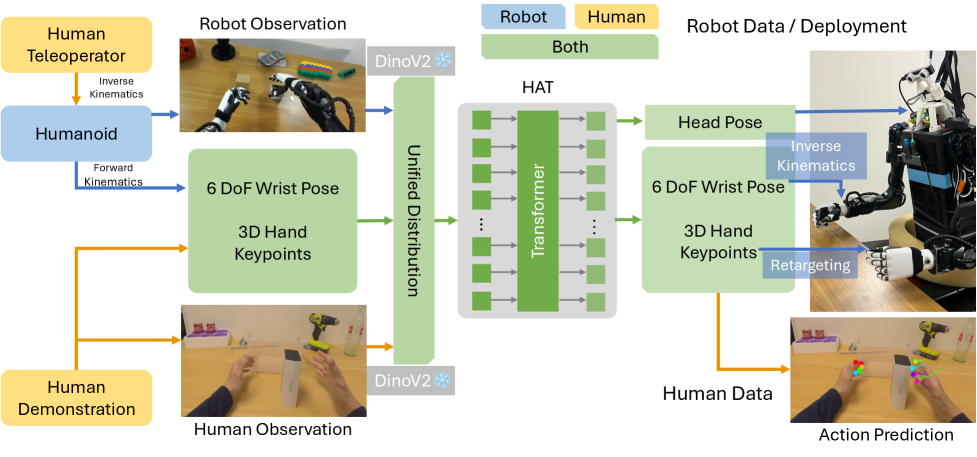
HAT(Human-humanoid Action Transformer)는 인간의 1인칭 시연 데이터를 휴머노이드 로봇 학습을 위한 크로스-엠보디먼트 훈련 데이터로 활용합니다. 인간과 휴머노이드 로봇을 다른 구현체로 취급하여 통합 인간 중심 상태-행동 표현 공간에서 미래 손-손가락 궤적을 예측합니다.
Behavior Foundation Model(BFM)은 휴머노이드 로봇을 위한 생성 모델로, 대규모 행동 데이터셋에서 사전학습되어 광범위하고 재사용 가능한 행동 지식을 포착합니다. 전체 작업 학습이 아닌 통합 행동 학습에 초점을 맞추어, 다양한 제어 모드로 직접 조종 가능하며 재학습 없이 효율적으로 새로운 행동을 습득할 수 있습니다.
2.4. 세계 모델과 확산 모델 연구
세계 모델(World Model)은 로봇이 환경의 내부 표현을 구축하고 미래 예측을 수행하여 체화된 AI를 강화합니다. Genie 2는 대규모 비디오 데이터셋으로 학습된 자기회귀 잠재 확산 모델로, 다양한 3D 세계를 생성할 수 있습니다.
Unified World Models(UWM)는 비디오와 액션 데이터를 모두 활용하여 정책 학습을 가능하게 하는 프레임워크로, 동역학과 액션 예측을 모두 사용한 대규모 멀티태스크 로봇 데이터셋의 효과적인 사전학습을 가능하게 합니다.
2.5. 시뮬레이션 환경
NVIDIA Isaac Sim은 Omniverse 기반의 오픈소스 레퍼런스 애플리케이션으로, 로봇 모델 훈련을 위한 합성 데이터 생성, 소프트웨어 및 하드웨어 인 루프 테스트를 통한 로봇 스택 검증, Isaac Lab을 통한 로봇 학습을 촉진합니다. Gazebo와의 연동도 지원하여 ROS 개발자들이 고충실도 렌더링이나 합성 데이터 생성 작업을 위해 시뮬레이션 자산을 Isaac Sim으로 가져올 수 있습니다.

3. 연구 주제별 동향
최근 서베이 논문들은 로봇 파운데이션 모델을 인지 및 상황 인식(객체 탐지 및 분류, 의미 이해, 매핑, 내비게이션), 의사결정 및 작업 계획(미션 이해, 작업 분해 및 조정, 계획 검증 및 수정, LLM-로봇 상호작용), 모션 계획 및 제어(모션 계획, 제어 명령 및 보상 생성, 확산 모델을 통한 궤적 생성 및 최적화)로 체계적으로 분류하고 있습니다.
4. 도전과제 및 미래 방향
데이터 부족 문제: 인터넷 스케일의 텍스트 데이터와 달리, 로봇 조작, 이동, 내비게이션 등의 물리적 상호작용 데이터는 수집이 어렵고 비용이 많이 듭니다. 이를 해결하기 위해 시뮬레이션 기반 합성 데이터 생성, 인간 비디오 활용, 텔레오퍼레이션 기반 데이터 수집 등 다양한 접근이 시도되고 있습니다.
안전성 및 불확실성 정량화: 로봇이 인간과 상호작용하는 환경에서 작동하기 때문에 안전성 보장이 매우 중요합니다. 인스턴스 수준 불확실성(언어 모호성, LLM 환각), 분포 수준 불확실성, 폐루프 로봇 배치로 인한 분포 이동 문제를 다루어야 합니다.
실시간 실행: 대규모 파운데이션 모델의 추론은 계산 비용이 높아 실시간 로봇 제어에 어려움이 있습니다. 모델 경량화, 지식 증류, 효율적인 주의 메커니즘 등의 연구가 진행되고 있습니다.
엠보디먼트 갭: 물리적 로봇 플랫폼의 다양성(형태, 센서, 액추에이터)을 다루면서도 일반성을 유지하는 것이 핵심 과제입니다. 크로스-엠보디먼트 학습, 통합 표현 공간, 모듈러 아키텍처 등이 해결책으로 제시되고 있습니다.
5. 한국의 연구 동향
한국에서도 로봇 파운데이션 모델 연구가 활발히 진행되고 있습니다. 과학기술정보통신부는 2025년 '독자 AI 파운데이션 모델' 프로젝트를 통해 2,000억 원 규모의 투자를 진행하고 있으며, 삼성전자는 KAIST 및 서울대와 협력하여 로봇 파운데이션 모델 개발에 집중하고 있습니다.
KAIST에서는 여러 연구실이 로봇 파운데이션 모델 관련 연구를 수행하고 있습니다. 박대형 교수 연구실(RIRO Lab)은 휴머노이드 로봇의 전신 조작을 위한 기초 학습 방법론 개발에 집중하며, VLA 모델과 LLM을 활용한 고수준 계획 전략을 설계하고 있습니다. 성영철 교수 연구실은 강화학습, LLM, 로봇 파운데이션 모델 연구를 수행하고 있습니다.
NAVER Labs Europe은 AI for Robotics 연구에 집중하며, 컴퓨터 비전, 자연어 처리, 최적화를 위한 기계학습, 로봇 학습, 인간-로봇 상호작용 분야에서 핵심 역량을 보유하고 있습니다. 2022년 네이버는 세계 최초 로봇 친화적 고층 사무 빌딩 '1784'를 건설하여 실제 일상 공간에서 로봇을 테스트할 수 있는 대규모 테스트베드를 구축했습니다.

로봇 파운데이션 모델은 범용 인공지능 실현을 위한 핵심 기술로 자리잡고 있으며, 업계의 대규모 투자와 학계의 체계적인 연구가 결합하여 빠르게 발전하고 있습니다. 앞으로 데이터 확보, 안전성 보장, 계산 효율성 향상, 크로스-엠보디먼트 일반화 등의 과제를 해결하면서, 로봇이 인간의 일상 생활과 산업 현장에서 더욱 유용하고 지능적인 동반자로 자리잡을 것으로 전망됩니다.
출처: 여러곳...
뜨리스땅
'로보틱스' 카테고리의 다른 글
| NVIDIA GR00T N1: 범용 인간형 로봇을 위한 개방형 파운데이션 모델 (0) | 2025.12.21 |
|---|---|
| 피규어01: AI로봇의 시작 (0) | 2024.03.20 |
| 로봇 소프트웨어 - ROS에 대해 좀 더 자세히(ROS1 & ROS2) (1) | 2024.02.08 |
| 로봇 소프트웨어 - 협동로봇 사용자 S/W (1) | 2024.02.07 |
| 로봇 소프트웨어 - 로봇플랫폼과 ROS (0) | 2024.02.06 |



댓글