1. 서론: 범용 로봇 지능을 향한 길
인간 세계에서 일상적인 작업을 자율적으로 수행하는 로봇을 개발하는 것은 로봇 공학 분야의 오랜 목표이자 중대한 기술적 과제였습니다.
최근 로봇 하드웨어, 인공지능, 그리고 가속 컴퓨팅 기술의 발전은 범용 로봇 자율성 구현을 위한 견고한 토대를 마련했습니다.
인간 수준의 물리적 지능으로 나아가기 위해서는 하드웨어, 모델, 데이터라는 세 가지 핵심 요소를 통합하는 풀스택(full-stack) 솔루션이 필수적입니다.
이 중 인간형 로봇은 인간과 유사한 신체 구조와 다재다능함 덕분에 로봇 지능을 구축하기 위한 매우 매력적인 하드웨어 플랫폼으로 주목받고 있습니다.
그러나 이러한 지능을 훈련시키는 과정에서 로봇 학습은 중대한 데이터 문제에 직면합니다. 텍스트나 이미지 분야와 달리, 대규모 사전 훈련에 필요한 웹 스케일의 인간형 로봇 데이터셋은 존재하지 않습니다.
개별 로봇 하드웨어에서 수집된 데이터는 그 양이 턱없이 부족하며, 다양한 로봇의 기종, 센서, 제어 방식의 차이로 인해 데이터가 통합되지 못하고 서로 고립된 "데이터 섬(data island)" 현상이 발생합니다. 이는 진정한 범용 모델을 훈련하는 데 가장 큰 걸림돌입니다.
이러한 문제를 해결하기 위한 강력한 대안으로 파운데이션 모델이 부상하고 있습니다. 파운데이션 모델은 웹 스케일 데이터로 훈련되어 강력한 일반화 성능과 빠른 적응 능력을 보여주며, 로봇 지능의 핵심 "백본(backbone)"이 될 잠재력을 지니고 있습니다. 이러한 비전 아래 개발된 것이 NVIDIA GR00T N1입니다.
GR00T N1은 범용 인간형 로봇을 위한 개방형 파운데이션 모델로서, 데이터 섬 문제를 해결하기 위한 포괄적인 솔루션입니다.
GR00T N1의 핵심 기술 혁신은 다음 세 가지로 요약할 수 있습니다.
- 이중 시스템(Dual-System) 아키텍처: 인간의 인지 과정에서 영감을 받아, 환경을 해석하는 추론 모듈(System 2)과 실시간으로 행동을 생성하는 액션 모듈(System 1)을 긴밀하게 결합했습니다.
- 데이터 피라미드(Data Pyramid) 전략: 웹 데이터, 인간 비디오, 합성 데이터, 실제 로봇 데이터를 양과 기종 특이성에 따라 계층적으로 구성하여 이기종 데이터 소스를 효과적으로 활용합니다.
- 교차 기종(Cross-Embodiment) 학습 능력: 기종별 인코더와 디코더를 통해 탁상용 로봇 팔부터 인간형 로봇에 이르기까지 다양한 하드웨어를 단일 모델로 지원합니다.
GR00T N1의 아키텍처, 훈련 방법론, 그리고 성능 평가 결과를 심층적으로 분석함으로써, 이 모델이 어떻게 범용 로봇 지능의 새로운 지평을 열었는지 좀더 자세히 이야기해보겠습니다.
2. GR00T N1 모델 아키텍처: 인지와 행동의 결합
GR00T N1의 핵심 설계 철학은 인간의 인지 과정에 대한 대니얼 카네만(Daniel Kahneman)의 이론에서 영감을 받은 이중 시스템(dual-system) 구성 아키텍처에 있습니다.
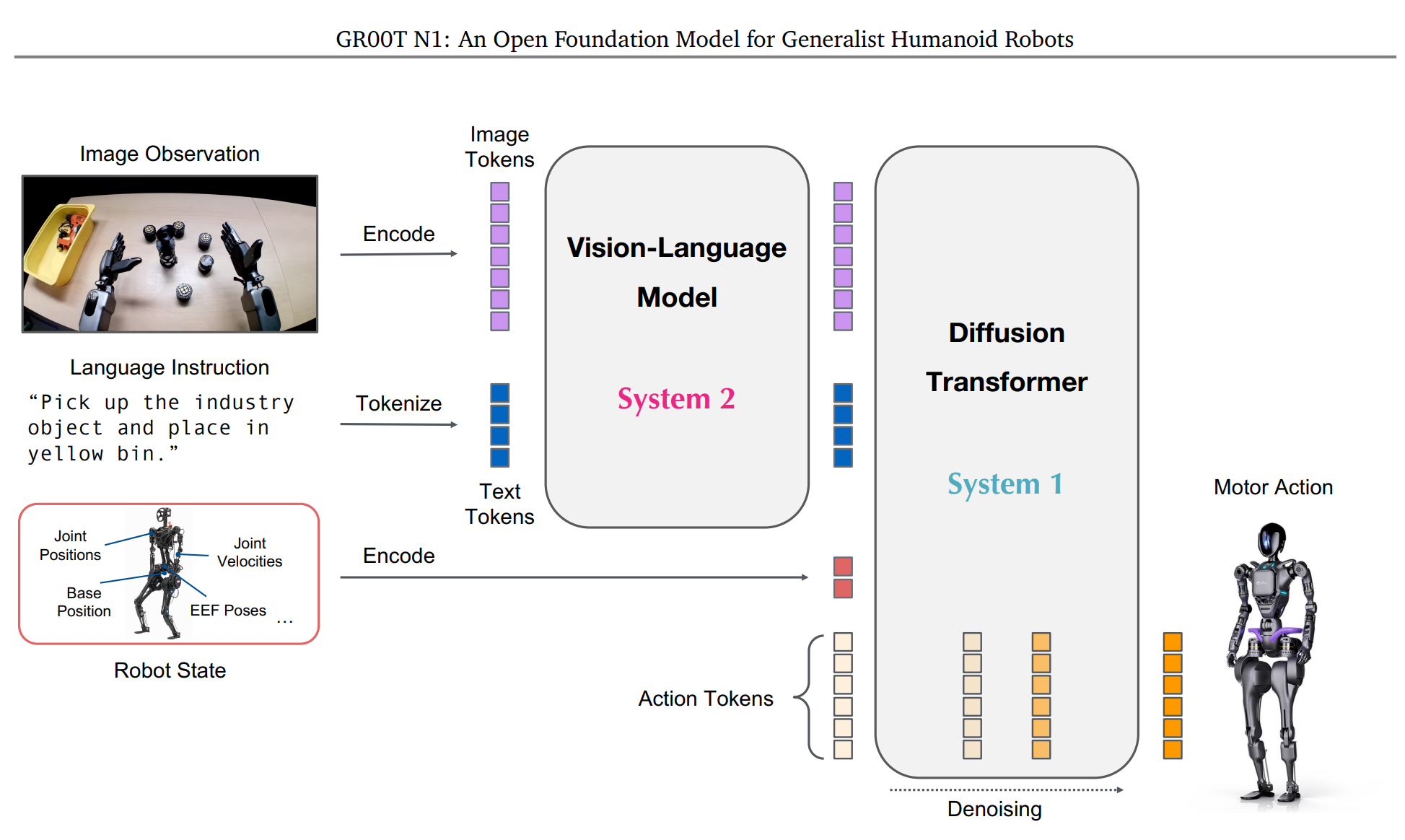
이 접근법은 신중하고 논리적인 추론을 담당하는 '시스템 2'와 빠르고 직관적인 반응을 담당하는 '시스템 1'을 모방하여, 로봇이 복잡한 환경을 이해하고 실시간으로 유연한 행동을 생성하도록 설계되었습니다.
이 두 시스템은 별개의 모듈로 작동하는 것이 아니라, 종단 간(end-to-end)으로 긴밀하게 결합되어 공동으로 최적화됨으로써 추론과 행동 사이의 유기적인 조화를 이끌어냅니다.
2.1. 시스템 2: 비전-언어 모듈 (Vision-Language Module) - 환경 해석 및 추론
시스템 2는 GR00T N1의 '추론 엔진' 역할을 수행하며, 사전 훈련된 비전-언어 모델(VLM)인 NVIDIA Eagle-2 VLM을 기반으로 합니다.
이 모듈은 로봇의 시각적 인식 정보(이미지 토큰)와 인간의 자연어 명령(텍스트 토큰)을 입력받아 처리합니다. 이를 통해 로봇은 주변 환경의 의미를 해석하고, 주어진 과업의 목표를 정확히 이해할 수 있습니다.
시스템 2는 NVIDIA L40 GPU 상에서 약 10Hz의 주파수로 작동하며, 실시간 행동 생성보다는 신중한 상황 판단과 목표 설정에 집중합니다.
2.2. 시스템 1: 디퓨전 트랜스포머 모듈 (Diffusion Transformer Module) - 행동 생성
시스템 1은 액션 플로우 매칭(action flow-matching) 기법으로 훈련된 **디퓨전 트랜스포머(Diffusion Transformer, DiT)**로 구성됩니다.
이 모듈은 시스템 2가 생성한 VLM 출력 토큰에 교차 어텐션(cross-attention)하여, 로봇의 현재 상태를 지속적으로 피드백 받아 다음 액션을 결정하는 폐쇄 루프(closed-loop) 방식으로 모터 액션을 직접 생성합니다.
시스템 1은 시스템 2보다 훨씬 높은 120Hz의 주파수로 작동하여, 복잡한 조작 작업을 위한 부드럽고 유연한 실시간 모션을 구현합니다.
이 두 시스템은 훈련 과정에서 공동으로 최적화되어 완벽한 시너지를 발휘합니다. 또한, GR00T N1은 다양한 로봇 하드웨어에 적용될 수 있도록 **기종별 인코더 및 디코더(embodiment-specific encoders and decoders)**를 사용합니다.
각 로봇 기종의 고유한 상태 및 액션 차원을 공통된 임베딩 공간으로 투영함으로써, 단일 모델이 여러 종류의 로봇을 효과적으로 제어할 수 있는 교차 기종 지원 능력을 확보했습니다.
이러한 이중 시스템 아키텍처는 데이터 피라미드의 각기 다른 계층을 효과적으로 소화하기 위해 필연적으로 요구되는 설계입니다.
시스템 2의 VLM은 피라미드 하단의 방대한 웹/비디오 데이터로부터 시각-언어적 사전 지식을 흡수하고, 시스템 1의 디퓨전 트랜스포머는 상단의 기종 특화적인 실제/합성 궤적 데이터를 정교한 행동으로 변환하는 데 최적화되어 있습니다.
3. 이기종 데이터 훈련 전략: 데이터 피라미드
기존 로봇 학습이 단일 데이터 소스에 의존해 한계를 보인 반면, GR00T N1의 **데이터 피라미드(Data Pyramid)**는 이기종 데이터의 전략적 융합을 통해 시너지 효과를 창출하는 새로운 패러다임을 제시합니다.

이 접근법은 데이터의 양과 기종 특이성(embodiment-specificity)을 기준으로 데이터 소스를 체계적으로 계층화합니다. 피라미드의 하단에는 양이 풍부하지만 일반적인 데이터가 위치하고, 상단으로 갈수록 양은 줄어들지만 특정 로봇에 특화된 데이터가 위치합니다.
이를 통해 모델은 광범위한 사전 지식부터 실제 로봇의 물리적 실행에 이르는 다층적인 학습을 수행하게 됩니다.
3.1. 기반 계층: 웹 데이터 및 인간 비디오 (Web Data & Human Videos)
데이터 피라미드의 가장 넓은 기반을 형성하는 이 계층은 모델에 광범위한 시각적, 행동적 사전 지식(prior)을 주입하는 역할을 합니다.
여기에는 VLM 사전 훈련에 사용된 웹 데이터와 더불어, Ego4D, EPIC-KITCHENS와 같은 대규모 인간 중심 비디오 데이터셋이 포함됩니다.
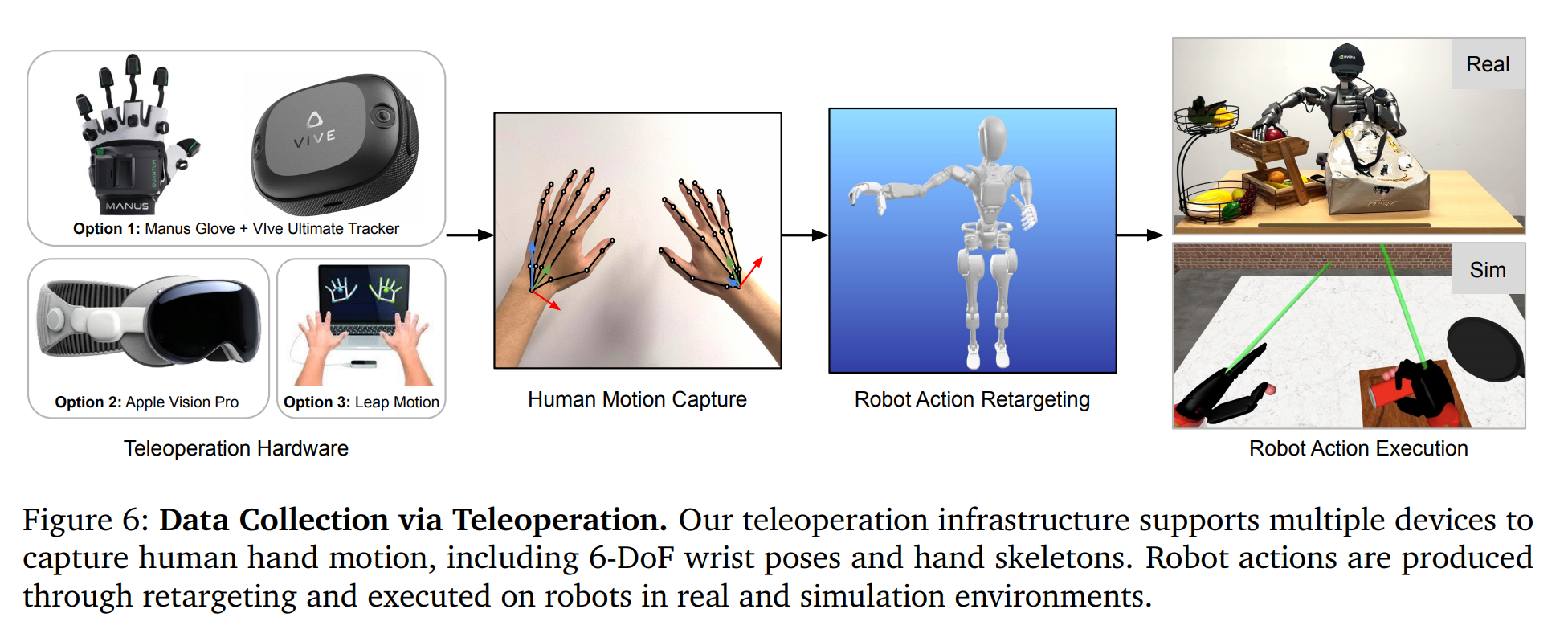
이 데이터들은 인간이 일상 환경에서 물체와 상호작용하는 방식을 보여줌으로써, 로봇이 세상의 물리적 법칙과 행동의 의미에 대한 의미론적 사전 지식을 학습하는 데 중요한 기반을 제공합니다.
3.2. 중간 계층: 합성 데이터 (Synthetic Data)
중간 계층은 물리 시뮬레이션과 신경망 모델을 통해 생성된 합성 데이터로 구성되어, 웹 데이터의 일반적 지식과 실제 로봇 데이터의 물리적 기반 사이의 간극을 효과적으로 메웁니다. GR00T N1은 두 가지 주요 합성 데이터 생성 방식을 활용합니다.
- 시뮬레이션 궤적 (Simulation Trajectories): DexMimicGen과 같은 자동화된 데이터 생성 시스템을 사용하여 소수의 인간 시연 데이터를 대규모로 확장합니다. 예를 들어, 소수의 인간 시연을 바탕으로 단 11시간 만에 **78만 개의 시뮬레이션 궤적(총 6,500시간 분량)**을 생성하여 데이터셋을 기하급수적으로 늘렸습니다.
- 신경망 궤적 (Neural Trajectories): 사전 훈련된 비디오 생성 모델을 미세 조정하여 실제 로봇 데이터를 증강합니다. 이 방법을 통해 88시간 분량의 실제 원격 조작 데이터를 약 10배에 달하는 827시간 분량의 다양하고 반사실적인(counterfactual) 비디오 데이터로 확장했습니다.

3.3. 최상위 계층: 실제 로봇 데이터 (Real-World Robot Data)
피라미드의 정점에는 실제 로봇에서 수집된 고품질 데이터가 위치합니다. 이 데이터는 모델의 행동을 실제 로봇의 물리적 제약과 동역학에 기반(grounding)시키는 결정적인 역할을 합니다.
주요 데이터 소스로는 Fourier GR-1 인간형 로봇을 원격 조작하여 수집한 데이터와 Open X-Embodiment와 같은 공개된 다중 기종 데이터셋이 포함됩니다.
데이터 피라미드의 가장 큰 난제는 액션 레이블이 없는 인간 비디오(기반 계층)와 명시적 액션 레이블이 있는 로봇 데이터(최상위 계층)를 어떻게 통합하는가였습니다.
GR00T N1은 **잠재적 액션(Latent Actions)**과 **역동역학 모델(Inverse Dynamics Model, IDM)**을 통해 이 문제를 해결합니다.

이 기술들은 비디오의 시각적 흐름에서 로봇이 모방할 수 있는 '의사 액션(pseudo-actions)'을 역으로 추론하여, 모든 이종 데이터를 '상태-관측-언어-액션'이라는 통일된 형식으로 변환합니다.
이는 사실상 액션이 없는 모든 비디오를 학습 가능한 데이터로 전환하는 번역기 역할을 수행합니다.
4. 훈련 방법론 및 인프라
GR00T N1의 학습 과정은 크게 **사전 훈련(Pre-training)**과 **사후 훈련(Post-training)**의 두 단계로 구성됩니다. 각 단계는 뚜렷한 목표를 가지며, 모델이 범용성과 전문성을 모두 갖출 수 있도록 전략적으로 설계되었습니다.
4.1. 사전 훈련 (Pre-training)
사전 훈련의 핵심 목표는 데이터 피라미드를 구성하는 모든 이기종 데이터를 활용하여 일반화 성능이 뛰어난 **범용 정책(generalist policy)**을 학습하는 것입니다.
이 단계에서 모델은 실제 로봇 데이터, 합성 데이터, 그리고 의사 액션이 레이블링된 인간 비디오 데이터를 포함한 거대한 데이터셋을 대상으로 훈련됩니다.
훈련은 **플로우 매칭 손실(flow-matching loss)**을 최소화하는 방향으로 진행되며, 이를 통해 모델은 다양한 기종과 작업에 걸쳐 공유될 수 있는 근본적인 시각-언어-행동 지식을 내재화하게 됩니다.

4.2. 사후 훈련 (Post-training / Fine-tuning)
사후 훈련은 사전 훈련된 범용 모델을 특정 로봇 기종(single embodiment) 및 특정 작업에 맞게 미세 조정하는 과정입니다.
이 단계의 목표는 데이터 효율성을 극대화하여 제한된 양의 데이터만으로도 특정 작업에서 높은 성능을 달성하는 것입니다.
이를 위해 비전-언어 백본의 언어 구성 요소는 동결(freeze)하여 사전 학습된 지식을 보존하고, 나머지 모델(비전-언어 백본의 비전 구성 요소 포함)은 특정 기종의 데이터셋에 맞게 미세 조정합니다.
특히, 데이터가 부족한 시나리오에서는 신경망 궤적 생성 기술을 활용하여 소량의 실제 데이터를 증강하고, 이를 통해 모델 성능을 효과적으로 향상시킬 수 있습니다.

훈련 인프라
GR00T N1과 같은 대규모 파운데이션 모델의 훈련은 방대한 컴퓨팅 자원을 필요로 합니다.
본 프로젝트는 복잡한 로봇 공학 워크로드를 확장하기 위한 오케스트레이션 플랫폼인 NVIDIA OSMO를 통해 관리되는 클러스터에서 수행되었습니다.
훈련에는 최대 1024개의 NVIDIA H100 GPU가 사용되었으며, 사전 훈련 단계에만 약 50,000 H100 GPU 시간이 소요되었습니다. 이는 GR00T N1 프로젝트의 막대한 규모와 기술적 투자를 보여주는 지표입니다.
5. 성능 평가 및 분석
GR00T N1 모델의 성능은 시뮬레이션과 실제 로봇 환경 양쪽에서 다각적으로 검증되었습니다.
평가는 사전 훈련된 모델의 일반화 능력과, 사후 훈련된 모델의 데이터 효율성 및 특정 과제 성공률에 중점을 두었습니다.
이를 통해 GR00T N1이 기존 최첨단 모방 학습 모델들과 비교하여 얼마나 뛰어난 성능을 보이는지 객관적으로 분석했습니다.
5.1. 시뮬레이션 벤치마크 평가
시뮬레이션 환경에서는 RoboCasa, DexMG, GR-1 세 가지 표준 벤치마크를 사용하여 GR00T-N1-2B 모델의 성능을 평가했습니다.
아래 표는 각 벤치마크에서 기존의 강력한 기준 모델인 BC-Transformer 및 Diffusion Policy와 비교한 평균 성공률을 보여줍니다.
표 2: 시뮬레이션 벤치마크 평균 성공률 (100개 시연/태스크 기준)
| 모델명 | RoboCasa | DexMG | GR-1 | 평균 |
| BC Transformer | 26.3% | 53.9% | 16.1% | 26.4% |
| Diffusion Policy | 25.6% | 56.1% | 32.7% | 33.4% |
| GR00T-N1-2B | 32.1% | 66.5% | 50.0% | 45.0% |
결과에서 볼 수 있듯이, GR00T-N1-2B는 모든 벤치마크에서 기존 모델들을 일관되게 능가했습니다. 특히, 인간형 로봇의 탁상 조작 능력을 평가하는 GR-1 벤치마크에서는 Diffusion Policy 대비 17%p 이상 높은 성공률을 기록하며, 사전 훈련을 통한 강력한 일반화 성능을 입증했습니다.
5.2. 실제 로봇 벤치마크 평가
Fourier GR-1 인간형 로봇을 이용한 실제 환경 테스트에서는 모델의 데이터 효율성이 두드러졌습니다. 전체 데이터셋을 사용한 경
우와 데이터의 10%만 사용한 소량 데이터 시나리오에서 GR00T-N1-2B와 Diffusion Policy의 성능을 비교했습니다.
- 전체 데이터 사용 시, GR00T-N1-2B는 평균 성공률 76.8%를 기록하여 Diffusion Policy(46.4%)를 30.4%p 차이로 크게 앞섰습니다.
- 10% 소량 데이터 사용 시, GR00T-N1-2B는 42.6%의 성공률을 보여 Diffusion Policy(10.2%)를 32.4%p라는 압도적인 격차로 능가했습니다.
이 결과는 단순히 점진적인 성능 향상이 아닙니다. 이는 데이터 피라미드와 대규모 사전 훈련이 모델에 강력하고 일반화 가능한 사전 지식을 성공적으로 주입했음을 명확히 증명하는 것입니다.
이 사전 지식은 새로운 작업에 대한 샘플 복잡도를 극적으로 낮추어, GR00T N1이 해결하고자 했던 바로 그 문제, 즉 실제 로봇 데이터의 높은 수집 비용과 희소성을 직접적으로 해결합니다.
10%의 데이터만으로 훈련한 GR00T-N1-2B가 전체 데이터로 훈련한 Diffusion Policy와 거의 유사한 성능(42.6% vs 46.4%)을 보였다는 점이 이를 뒷받침합니다.
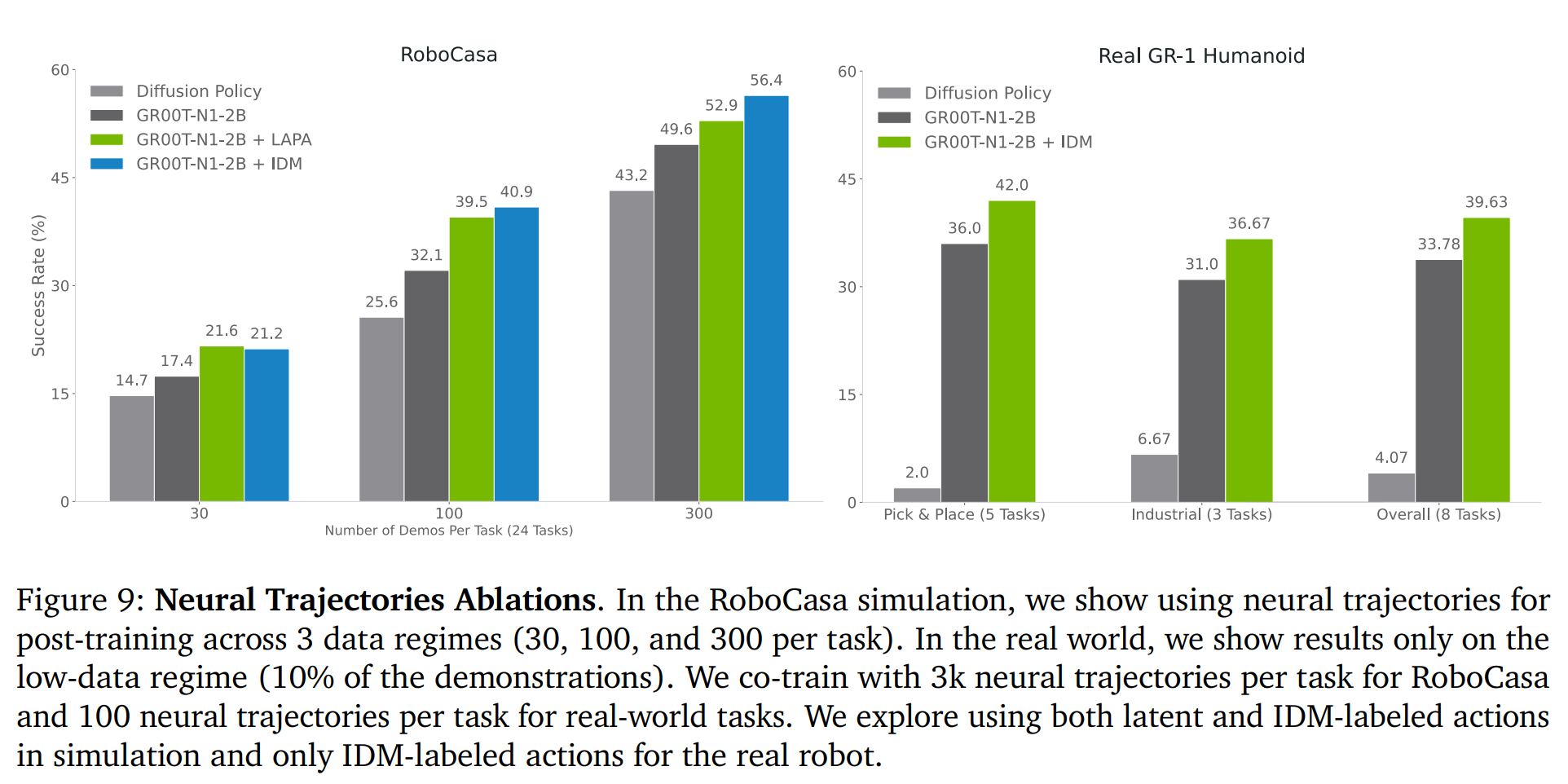
5.3. 정성적 분석: 행동의 질
수치적 결과를 넘어, 생성된 행동의 질적인 측면에서도 GR00T N1은 우수성을 보였습니다.
- 일반화 능력: 사전 훈련된 GR00T N1 모델은 훈련 데이터에 명시적으로 포함되지 않았던 양손 물체 전달(handover) 동작을 성공적으로 수행했습니다. 이는 모델이 다양한 데이터로부터 암묵적인 협응 전략을 학습했음을 보여주는 강력한 증거입니다.
- 동작의 유연성: 사후 훈련된 GR00T N1의 동작은 기준 모델인 Diffusion Policy에 비해 훨씬 더 부드럽고 안정적이었으며, 물체를 파지하는 정확도 또한 현저히 높았습니다. 반면, 기준 모델은 부정확한 파지나 초기 동작 지연과 같은 문제를 자주 보였습니다.
6. 한계 및 향후 연구
GR00T N1은 현재의 성취를 바탕으로, 범용 로봇 지능의 다음 단계를 위한 명확한 연구 방향을 제시합니다. 현재의 주요 개척 과제는 다음과 같습니다.
- 작업 범위의 한계: 현재 모델은 주로 단기(short-horizon) 탁상 조작 작업에 초점을 맞추고 있습니다. 장거리 이동과 조작이 결합된 장기(long-horizon) 이동-조작(loco-manipulation) 작업으로의 확장은 향후 과제입니다.
- 합성 데이터의 한계: 시뮬레이션 및 비디오 생성 모델을 활용한 합성 데이터 생성 기술은 매우 유용하지만, 아직 물리 법칙을 완벽히 준수하면서 다양하고 반사실적인(counterfactual) 데이터를 생성하는 데 어려움이 있습니다.
- VLM 백본의 성능: 더 강력한 비전-언어 백본 모델을 통합하면 공간 추론 및 언어 이해 능력이 향상되어 모델의 전반적인 성능을 더욱 끌어올릴 수 있을 것으로 기대됩니다.
이러한 한계를 극복하기 위해 향후 연구는 모델의 기능을 장기 이동-조작 작업으로 확장하고, 물리 법칙을 더 잘 반영하도록 합성 데이터 생성 기술을 고도화하며, 새로운 모델 아키텍처와 사전 훈련 전략을 지속적으로 탐구하여 로봇 모델의 견고함과 일반화 성능을 개선해 나갈 것입니다.
7. 결론
NVIDIA GR00T N1은 개방형 파운데이션 모델로서, 범용 인간형 로봇 개발에 중요한 이정표를 제시합니다. GR00T N1은 이중 시스템 아키텍처를 통해 추론과 행동을 효과적으로 결합하고, 데이터 피라미드 전략으로 이기종 데이터를 통합하여 "데이터 섬" 문제를 해결했으며, 다중 기종 지원을 통해 높은 확장성을 확보했습니다.
시뮬레이션과 실제 로봇 실험을 통해 입증된 GR00T N1의 강력한 일반화 능력과 높은 데이터 효율성은 이 모델이 실제 환경에서 복잡한 조작 기술을 빠르고 효과적으로 학습할 수 있음을 보여줍니다.
NVIDIA는 GR00T-N1-2B 모델 체크포인트, 관련 훈련 데이터셋, 그리고 시뮬레이션 환경을 공개함으로써 로봇 공학 커뮤니티의 발전을 가속화할 예정이라고 합니다. 또한, 이러한 노력이 유능한 인간형 로봇을 현실 세계에 배치하는 공동의 목표를 향한 진보를 가속화하고, 새로운 혁신의 장을 열 것이라 확신에 기반하여 연구를 진행하고 있습니다.
출처: NVIDIA
뜨리스땅
'로보틱스' 카테고리의 다른 글
| 로봇파운데이션 모델 기술 개발 동향 (0) | 2025.11.20 |
|---|---|
| 피규어01: AI로봇의 시작 (0) | 2024.03.20 |
| 로봇 소프트웨어 - ROS에 대해 좀 더 자세히(ROS1 & ROS2) (1) | 2024.02.08 |
| 로봇 소프트웨어 - 협동로봇 사용자 S/W (1) | 2024.02.07 |
| 로봇 소프트웨어 - 로봇플랫폼과 ROS (0) | 2024.02.06 |



댓글