1. 도입: 인공지능의 속도는 왜 메모리에서 결정되는가?
현재 AI 산업의 무게중심은 거대한 모델을 구축하는 '학습'에서, 완성된 모델을 실생활에 적용하는 '실시간 추론'으로 빠르게 이동하고 있습니다. 인텔리전스가 거대 데이터 센터를 넘어 우리 손안의 모바일 기기로 내려옴에 따라, 이제 AI의 경쟁력은 단순히 '지능의 깊이'가 아니라 사용자의 요구에 즉각 반응하는 '지연 시간(Latency)'에서 결정됩니다.
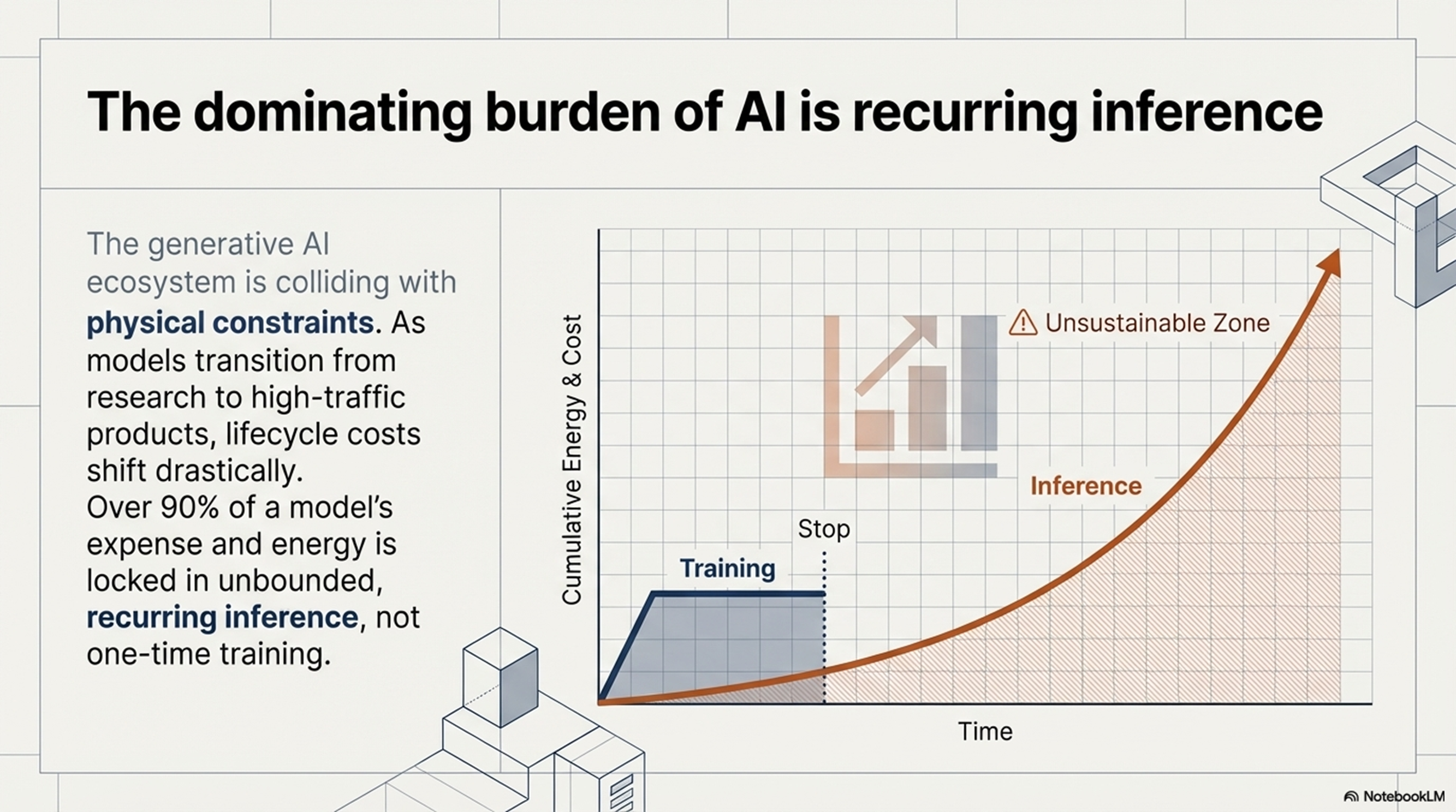
하지만 프로세서의 연산 능력이 아무리 발전해도 메모리가 데이터를 제때 공급하지 못하면 전체 성능은 하락합니다. 또한, AI 산업의 무게중심이 거대 모델의 '학습(Training)'에서 실무 서비스 구현을 위한 '추론(Inference)'으로 급격히 이동함에 따라, 엔비디아는 자사의 시장 지배력을 공고히 하기 위해 전례 없는 승부수를 던졌습니다. 2025년 12월, 엔비디아가 추론 기술의 강자였던 그록(Groq)의 자산을 200억 달러에 인수 및 라이선싱하며, 두 가지 서로 다른 메모리 철학을 하나로 통합하기 시작한 것입니다.
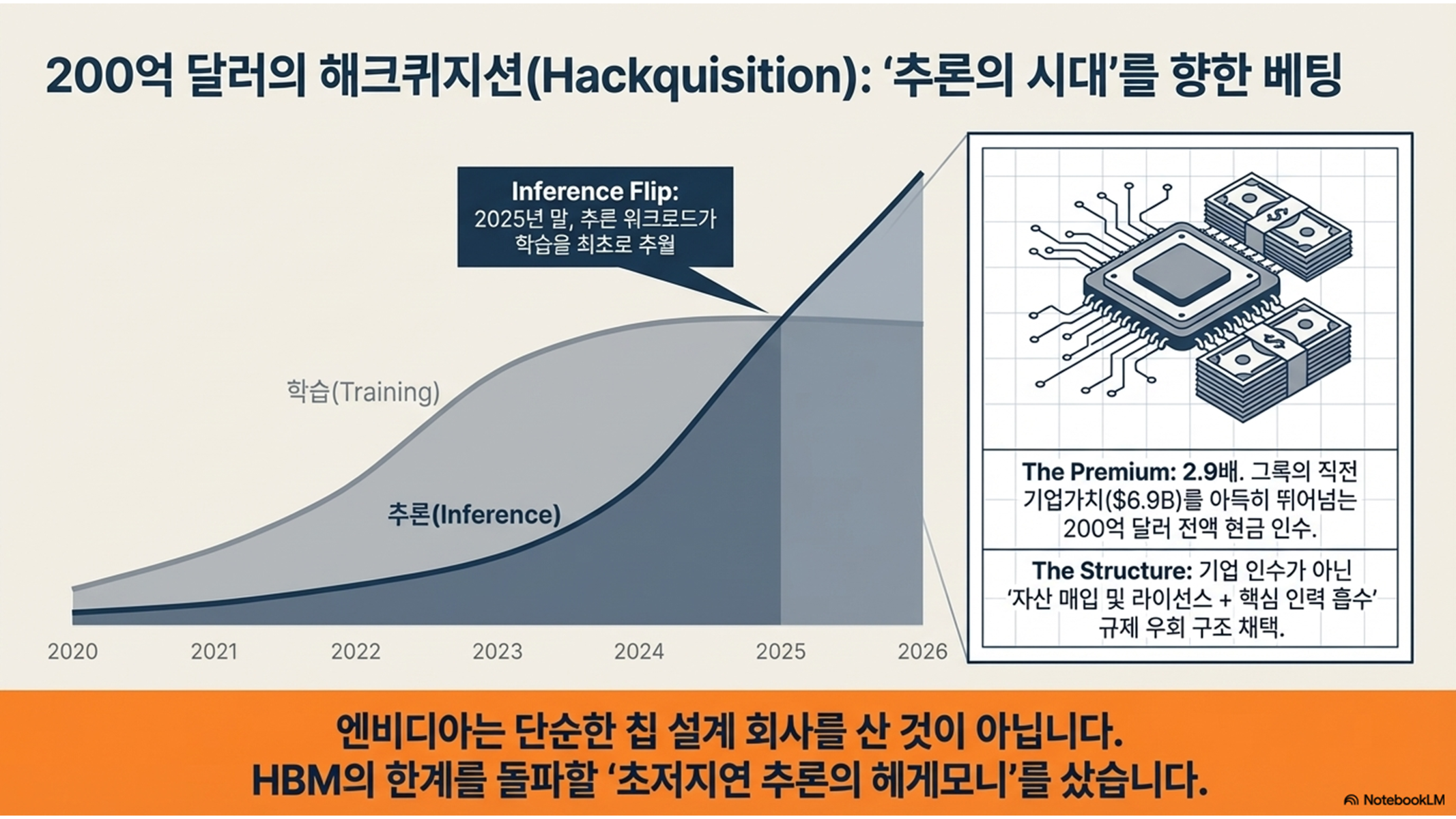
2025년 12월, 엔비디아가 AI 칩 스타트업 그록(Groq)의 핵심 자산을 **200억 달러(약 29조 원)**에 인수한 것은 단순한 기술 확보를 넘어선 '전략적 프리미엄'의 산물입니다.이번 거래의 핵심이 불과 3개월 전 69억 달러였던 그록의 기업 가치에 2.9배의 프리미엄을 얹어 준 '경쟁자 제거(Kill-zone acquisition)' 전략에 있다고 판단할 수 있기 때문입니다.

엔비디아는 구글(TPU), 아마존(Trainium) 등 하이퍼스케일러들이 자체 ASIC을 통해 HBM(고대역폭 메모리) 수급 병목을 우회하려는 움직임을 포착하고, 이를 무력화하기 위해 SRAM 기반의 LPU(Language Processing Unit) 기술을 전격 수용했습니다. 이는 엔비디아가 추론 시장의 '아키텍처 프런티어'를 중화하고, 잠재적 위협이 될 수 있는 대체 기술 스택을 자사 생태계로 흡수하여 '추론 해자(Inference Moat)'를 완성하겠다는 의지입니다.
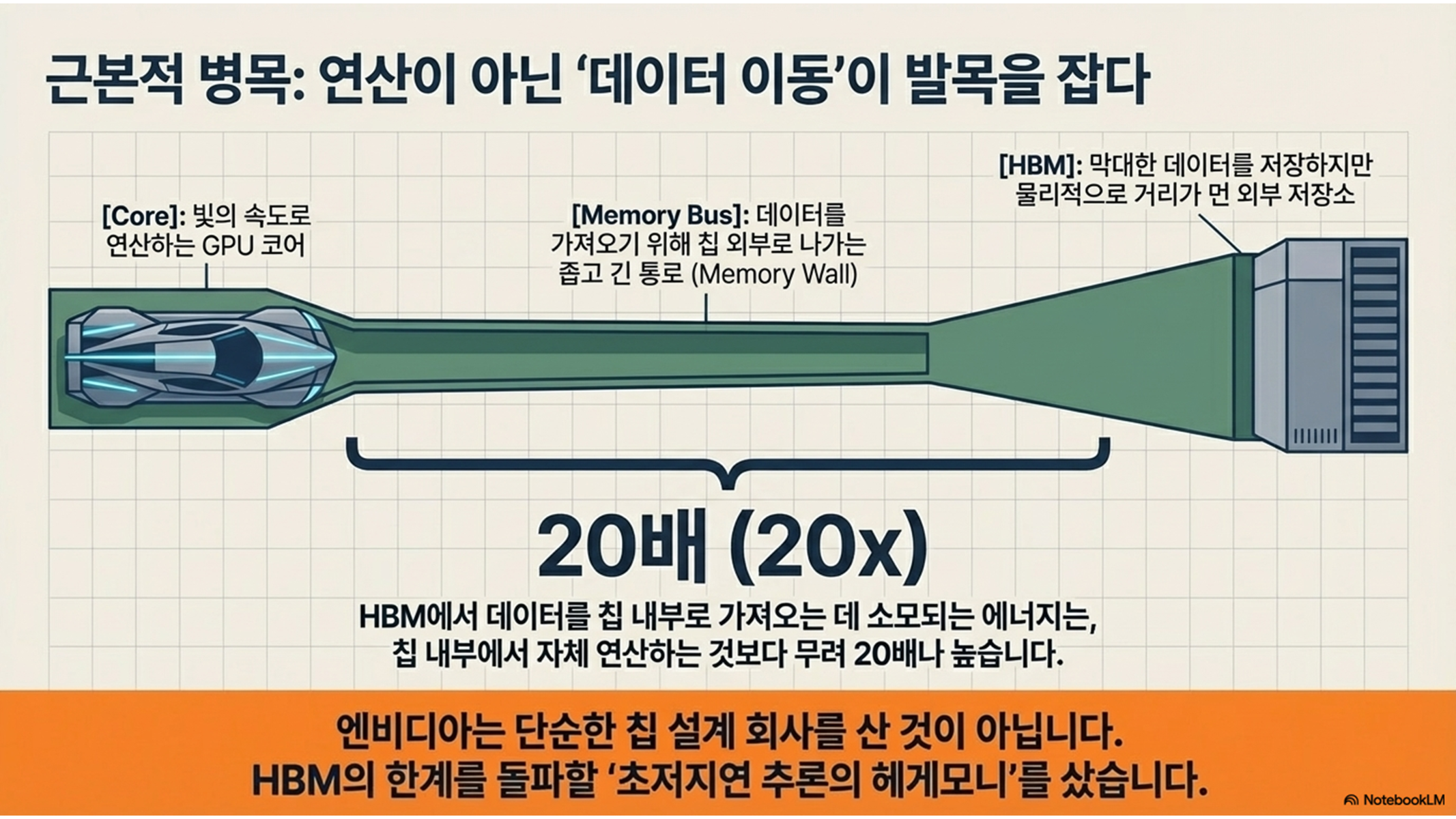
"AI 성능의 진정한 병목은 연산 장치가 데이터를 처리하는 속도가 아니라, 메모리에서 데이터를 꺼내오는 과정에서 발생합니다. 아무리 빠른 슈퍼카라도 좁은 골목길(대역폭)과 먼 주차장(지연 시간) 앞에서는 속도를 낼 수 없는 것과 같습니다."
그렇다면 이 병목 현상을 해결하기 위해 엔비디아와 그록은 각각 어떤 길을 걸어왔으며, 이제 하나로 합쳐진 두 기술은 어떤 원리로 작동할까요? 비유를 통해 알아봅시다.
2. 비유로 이해하는 메모리 구조: '외부 창고' vs '책상 위 서랍'
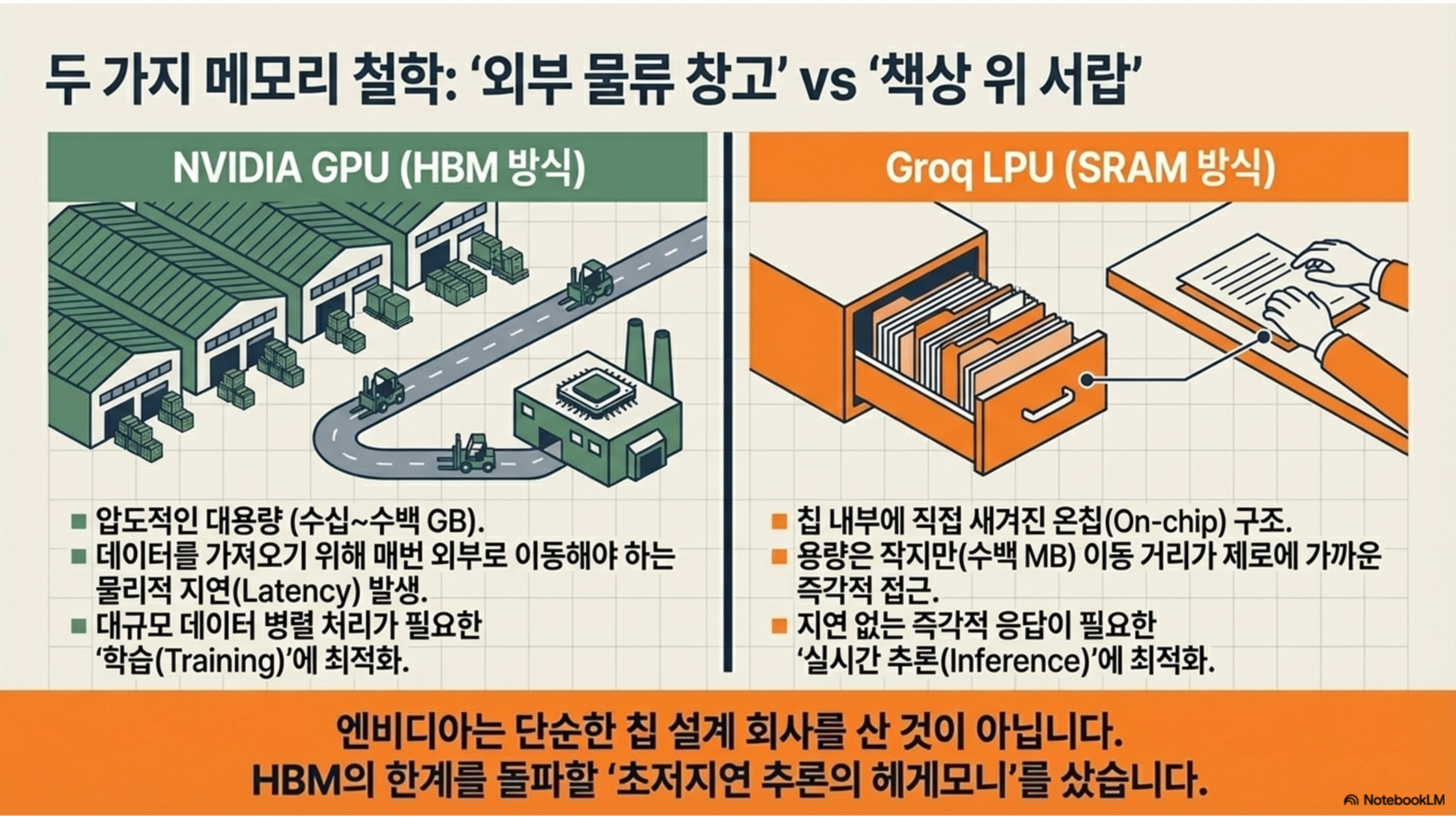
AI 모델의 방대한 데이터(가중치)를 처리하는 방식은 저장 위치와 접근 방식에 따라 두 가지로 나뉩니다.
- HBM (외부 창고): 엔비디아 GPU가 전통적으로 채택해 온 방식입니다. 엄청난 양의 데이터를 저장할 수 있는 거대한 창고와 같습니다.
- 물리적 구조: 데이터를 저장하는 메모리(HBM)가 연산 장치(Core) 외부에서 배선으로 연결되어 있습니다.
- 지연 시간과 에너지: 데이터를 쓰려면 매번 칩 외부 창고까지 나갔다 와야 하므로 이동 시간이 발생합니다. 소스 데이터에 따르면, HBM에서 데이터를 이동시키는 데 드는 에너지는 칩 내부에서 처리할 때보다 무려 20배나 더 많습니다.
- SRAM (책상 위 서랍): 그록(Groq)의 LPU(Language Processing Unit)가 개척한 방식입니다. 연산 장치 바로 옆에 붙어 있는 즉각적인 서랍과 같습니다.
- 물리적 구조: 연산 회로와 메모리를 하나의 실리콘 다이 위에 함께 새기는 '온칩(On-chip) SRAM' 구조입니다.
- 결정론적(Deterministic) 속도: SRAM은 DRAM과 달리 데이터를 유지하기 위해 전기를 재충전(Refresh)할 필요가 없는 '정적' 구조입니다. 덕분에 지연 없이 매 클록 사이클마다 정확한 속도를 보장합니다. 또한, 그록의 '정적 스케줄링(Static Scheduling)' 기술은 컴파일러가 모든 데이터 이동을 미리 계획하여 연산 낭비를 없앱니다.
이러한 구조적 차이는 실제 수치상으로 얼마나 큰 성능 격차를 만들어낼까요?
3. 기술적 심층 비교: 엔비디아 GPU(HBM) vs 그록 LPU(SRAM)
엔비디아는 HBM의 물리적 지연 시간을 숨기기 위해 여러 사용자의 요청을 모아 한꺼번에 처리하는 '배치(Batch)' 방식을 사용합니다. 이로 인해 단일 사용자는 "Chatbot Paused..."와 같은 일시적인 멈춤 현상을 겪게 됩니다. 반면, SRAM 기반의 LPU는 요청 즉시 처리가 가능합니다.

| 비교 항목 | 엔비디아 HBM (GPU) | 그록 SRAM (LPU) |
| 핵심 메모리 기술 | 외부 HBM (고대역폭 메모리) | 온칩 SRAM (정적 RAM) |
| 데이터 전송 속도 | 약 8TB/s (대역폭) | 약 80TB/s (10배 빠름) |
| 추론 성능(Llama 3 8B) | 약 60~70 tokens/s | 약 877 tokens/s (압도적 속도) |
| 데이터 처리 방식 | 배치 처리: 대기 후 묶음 처리 | 즉시 처리: 컴파일러 기반 정적 실행 |
| 경제적 비용/용량 | 칩당 80GB 이상 (대용량 유리) | 칩당 약 230MB (확장 비용 높음) |

SRAM이 이렇게 압도적으로 빠르다면, 왜 모든 AI 칩을 SRAM으로만 채우지 않는 걸까요? 거기에는 물리적, 경제적 이유가 있습니다.
4. SRAM의 명암: 왜 속도는 빠르지만 용량 확장이 어려울까?
SRAM은 성능 면에서 탁월하지만, 보편화하기에는 다음과 같은 치명적인 한계가 있습니다.
- 물리적 집적도의 한계: 반도체 공정이 2~3nm로 미세화되면서 SRAM의 안정성은 오히려 떨어지고 있습니다. 벨기에 반도체 연구소 IMEC에 따르면, 공정이 미세화될수록 SRAM 핀(Pin)의 높이를 높여야 하는 물리적 제약 때문에 더 이상 트랜지스터를 조밀하게 배치하기 어려운 임계점에 도달했습니다. 즉, 칩 면적 대비 용량을 늘리기가 매우 어렵습니다.
- 경제적 비용: SRAM은 동일 용량 대비 DRAM보다 수백 배 더 비쌉니다. 실제로 Llama 3 70B와 같은 대형 모델을 구동하려면 엔비디아 GPU는 소수의 장비로 가능하지만, 그록의 LPU는 약 576개의 칩을 네트워크로 연결해야만 가중치를 모두 담을 수 있습니다. 이는 하드웨어 구축 비용(CapEx)의 급격한 상승을 의미합니다.

결국 이러한 장단점의 차이는 AI가 수행하는 두 가지 핵심 작업인 '학습'과 '추론'에서 각자의 전문 영역을 가르게 됩니다.
5. 실전 적용: '학습'에 강한 HBM과 '추론'에 강한 SRAM
학습자와 기업은 자신의 목적에 맞는 하드웨어 철학을 선택해야 합니다.
- 모델 학습 (Training)
- 핵심 요구 사항: 수조 개의 파라미터를 한꺼번에 저장하고 갱신할 수 있는 방대한 용량.
- 추천 메모리: HBM 기반 GPU. 지연 시간이 있더라도 거대한 데이터를 한 번에 소화하는 '외부 창고'가 필수적입니다.
- 모델 추론 (Inference)
- 핵심 요구 사항: 실시간 응답성(UX). 사용자가 타이핑하는 속도보다 빠른 결과 생성.
- 추천 메모리: SRAM 기반 LPU. 실시간 음성 에이전트, 개발자의 코드 자동 완성, 복잡한 '생각의 사슬(CoT)' 추론 등에서 10배 이상의 이득을 제공합니다.

6. 시장 전략 분석: '학습-추론' 양발 전략과 ASIC 전환의 선제적 차단
엔비디아는 이번 인수를 통해 '학습용 GPU'와 '추론용 LPU'를 상호 보완적으로 배치하는 통합 아키텍처를 구축했습니다.
- ASIC 피벗(Pivot)의 선제적 차단: 구글, 아마존 등 경쟁사들이 HBM 병목에 갇힌 ASIC을 개발할 때, 엔비디아는 SRAM이라는 대안적 메모리 패러다임을 선점했습니다. 이는 경쟁사들의 하드웨어 차별화 시도를 무력화하는 효과를 가집니다.
- CUDA 생태계 고착화(Lock-in): 개발자가 CUDA 환경에서 모델을 학습시킨 후, 동일한 스택 내에서 LPU 기반의 초저지연 추론으로 즉각 전환할 수 있게 함으로써 타사 플랫폼으로의 이탈 가능성을 원천 봉쇄했습니다. 엔비디아는 이를 통해 학습부터 추론까지 이어지는 'AI 전주기 독점 해자'를 구축했습니다.

7. M&A 구조의 혁신: '해크퀴지션(Hackquisition)'을 통한 규제 우회
엔비디아는 반독점 규제의 칼날을 피하고자 법인 전체 인수가 아닌 **'자산 인수 및 라이선스 + 주요 인력 영입(Acquihire)'**이라는 영리한 구조를 선택했습니다.
- 규제 회피의 새로운 표준: 마이크로소프트와 인플렉션 AI(Inflection AI) 사례를 벤치마킹한 이 방식은, 그록이라는 법인을 '기술적으로 생존'시켜 시장 경쟁이 유지되는 것처럼 보이게 하면서 실질적으로는 IP와 핵심 엔지니어를 모두 흡수하는 '해크퀴지션' 전략입니다.
- 실질적 지배력 확보: 조너선 로스를 포함한 핵심 인력 전원을 엔비디아 내부로 이전시킴으로써, 그록의 혁신 동력을 엔비디아의 'AI 팩토리' 로드맵에 완전히 통합했습니다. 이는 향후 빅테크 기업들이 기술적 독점 비판을 피하면서 유망 스타트업의 자산을 탈취하는 새로운 M&A 표준(Standard)이 될 것입니다.

6. 결론: 나에게 맞는 AI 인프라를 선택하는 안목
이제 우리는 AI 칩의 성능이 단순히 숫자가 아니라 아키텍처의 철학에서 나온다는 것을 이해하게 되었습니다. 엔비디아가 그록을 인수한 것은 학습 시장의 지배력을 유지하면서, 동시에 SRAM을 활용한 초저지연 추론 시장까지 장악하겠다는 전략적 포석입니다.

미래의 AI는 거대 모델 하나가 모든 것을 처리하는 방식에서, 특정 영역에 특화된 작은 모델(SLM)들이 협력하는 **'도메인 특화 초지능(DSS: Domain-Specific Superintelligence)'**의 사회로 진화할 것입니다. 이 '전문가 사회'에서 SRAM 기반 기술은 각 전문가가 즉각적으로 답을 내놓게 만드는 핵심 신경망 역할을 하게 될 것입니다.

기억해야 할 3가지 핵심 요약
- [x] 메모리 병목의 실체: AI 속도는 데이터 이동(20배의 에너지 소모 차이)에서 결정된다.
- [x] SRAM의 가치: 온칩 구조와 정적 스케줄링을 통해 배치 처리 없는 즉각 응답을 실현한다.
- [x] 미래 전략: 엔비디아의 인수 합병은 HBM(대용량 학습)과 SRAM(초고속 추론)의 '양발 전략'을 의미한다.
https://www.youtube.com/watch?v=0Z7YE287x7s
출처: NVIDIA GTC 2026
뜨리스땅
'반도체, 소.부.장.' 카테고리의 다른 글
| TurboQuant 알고리즘 혁신에 따른 AI 반도체 산업의 영향 (0) | 2026.03.28 |
|---|---|
| AI 반도체 대기근: 왜 글로벌 빅테크는 돈을 싸 들고도 칩을 구하지 못할까? (0) | 2026.03.15 |
| Vera Rubin: NVIDIA가 “랙 전체”를 하나의 칩처럼 설계하기 시작했다 (0) | 2026.02.27 |
| Microsoft의 새로운 AI chip: Maia 200 (0) | 2026.02.22 |
| AI 주도 메모리 슈퍼사이클의 구조적 변화와 공급 제약 요인 (0) | 2026.02.08 |




댓글