1. 서론: LLM 시대의 임계점과 '메모리 벽(Memory Wall)'의 재정의
현재 대규모 언어 모델(LLM) 추론 환경에서 GPU의 자본 효율성을 저해하는 가장 치명적인 병목은 연산 속도가 아닌 'KV 캐시(Key-Value Cache)의 점유' 문제입니다. 자기회귀(Autoregressive) 디코딩의 특성상 문맥 유지에 필요한 데이터는 선형적으로 증가하며, 이는 하드웨어 리소스의 심각한 불균형을 초래하고 있습니다.
기술적 수치로 분석할 때, 70B 파라미터 모델이 1M 토큰의 컨텍스트를 처리할 경우 VRAM(GDDR or HBM)의 80~90%가 오직 KV 캐시 저장에만 소모됩니다. 구체적으로는 임시 메모리 저장에만 40GB 이상의 VRAM 비용이 발생하며, 이는 단순한 용량 부족을 넘어 아키텍처적 임계점에 도달했음을 의미합니다.
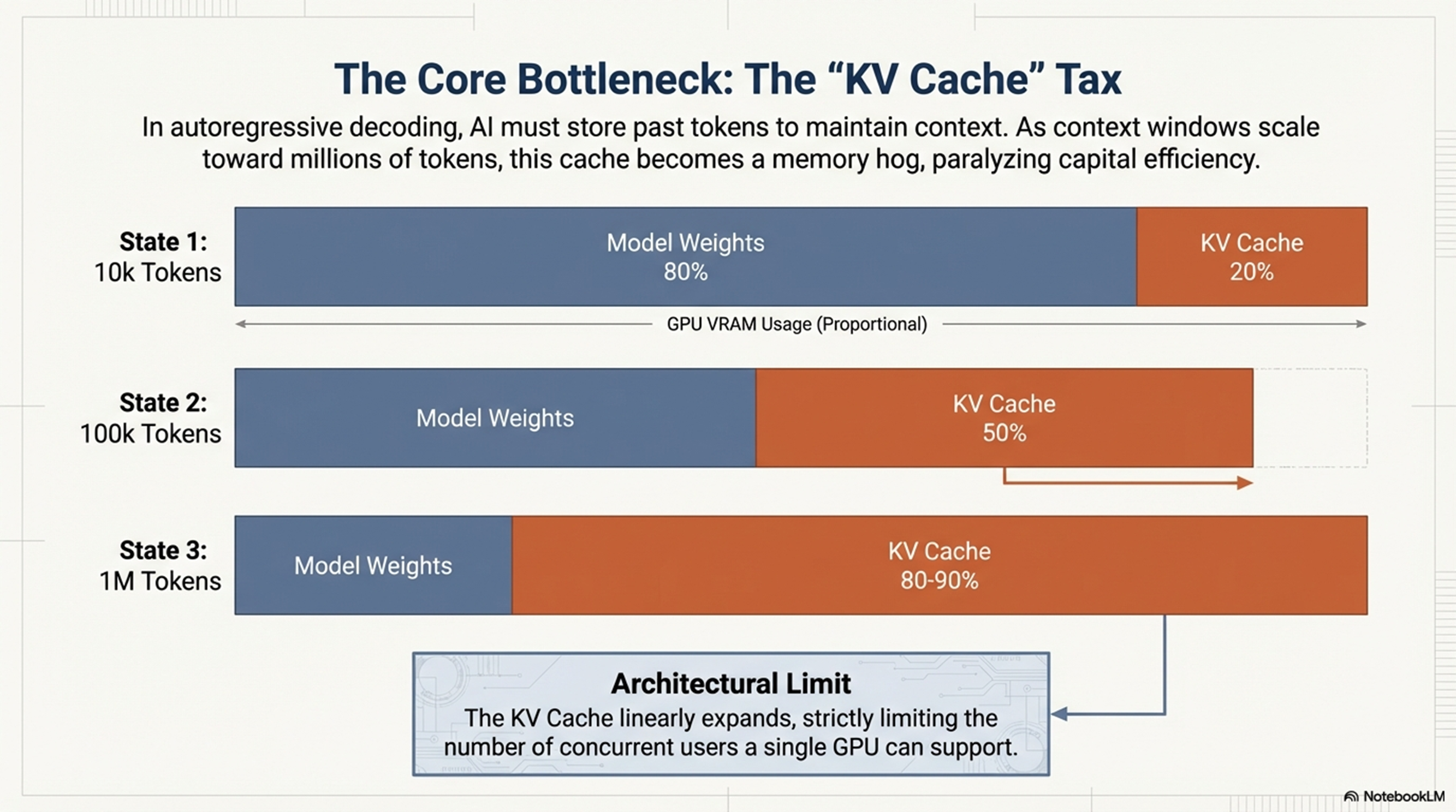
결과적으로 연산 코어는 HBM에서 SRAM으로의 데이터 로드를 기다리며 유휴(Idle) 상태에 머물게 되고, 토큰당 생성 비용(Cost per Token)은 기하급수적으로 상승합니다. 이러한 물리적 한계를 돌파하기 위한 근본적 해결책으로 Google의 TurboQuant가 제시하는 새로운 양자화 패러다임을 검토해야 합니다.
2. TurboQuant의 핵심 메커니즘: 데이터 무관(Data-oblivious) 아키텍처로의 전환
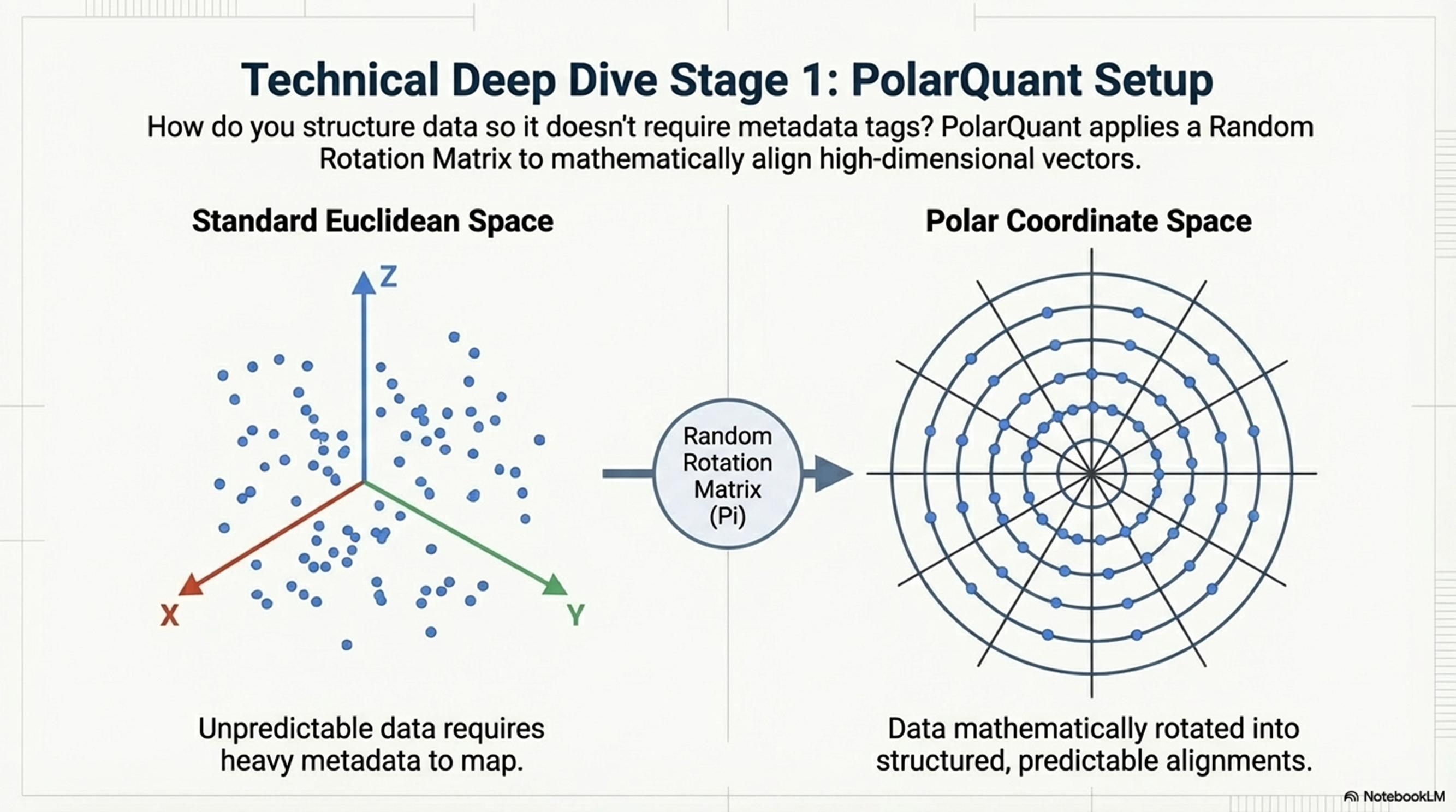
기존의 표준 벡터 양자화 방식은 압축 데이터를 복원하기 위해 정규화 상수(Scale Factors)나 제로 포인트(Zero-points)와 같은 고정밀 메타데이터를 필수적으로 동반해야 했습니다. 이를 **'메타데이터 세금(Metadata Tax)'**이라 부르며, 4비트 이하 초저비트 환경에서는 이 오버헤드가 숫자당 1~2비트에 달해 압축 효율을 사실상 무력화합니다.
TurboQuant는 이를 수학적으로 제거하여 '태그 프리(Tag-free)' 구조를 실현했습니다.

- PolarQuant의 기하학적 회전: 기존 방식이 무질서한 데이터 배치(Cartesian Mess)를 개별적으로 맵핑했다면, TurboQuant는 무작위 직교 회전(Random Orthogonal Rotation) 기술을 적용합니다. 이 회전은 고차원 벡터를 수학적으로 보장된 **'폴라 베타 분포(Polar Beta Distribution)'**로 강제 정렬시킵니다.
- 데이터 무관(Data-oblivious)의 이점: 기하학적 형태가 수학적으로 고정됨에 따라, 시스템은 데이터셋 특이적 튜닝 없이도 고정된 'Lloyd-Max' 스칼라 양자화 그리드를 적용할 수 있습니다. 이는 복잡한 역양자화 코드북(Dequantization Codebooks)을 실리콘 단에서 참조할 필요가 없음을 의미하며, 데이터 이동 경로인 '실리콘 동맥(Silicon Arteries)'의 정체를 근본적으로 해소합니다.

3. 정밀도와 효율의 공존: QJL 기술과 비대칭 어텐션(Asymmetric Attention)
TurboQuant의 2단계 보정 기술인 **QJL(Quantized Johnson-Lindenstrauss)**은 1단계 회전 후 발생하는 미세한 잔류 오차(Residual Error)를 이론적 한계치까지 제어합니다.
- 1비트 폴리싱(1-Bit Polish): QJL은 잔류 오차를 단일 부호 비트(+1/-1)인 '1비트 바코드'로 변환하여 **'불편 추정량(Unbiased Estimator)'**을 생성합니다. 이는 이론적 샤논 한계(Shannon bound)의 2.7배 이내에서 원본의 의미를 완벽하게 보존하며, 모델의 논리적 붕괴를 차단합니다.
- 비대칭 최적화 분석: 어텐션 메커니즘에서 단일 쿼리(Query)는 고정밀도를 유지하고, 수백만 개의 키(Key)는 1비트로 공격적으로 압축하는 비대칭 구조를 채택합니다. 정밀한 쿼리가 1비트 키들과 내적(Inner Product) 계산을 수행할 때 수학적 기댓값이 보존되므로, 추론 능력의 손실 없이 극단적 효율을 달성합니다.

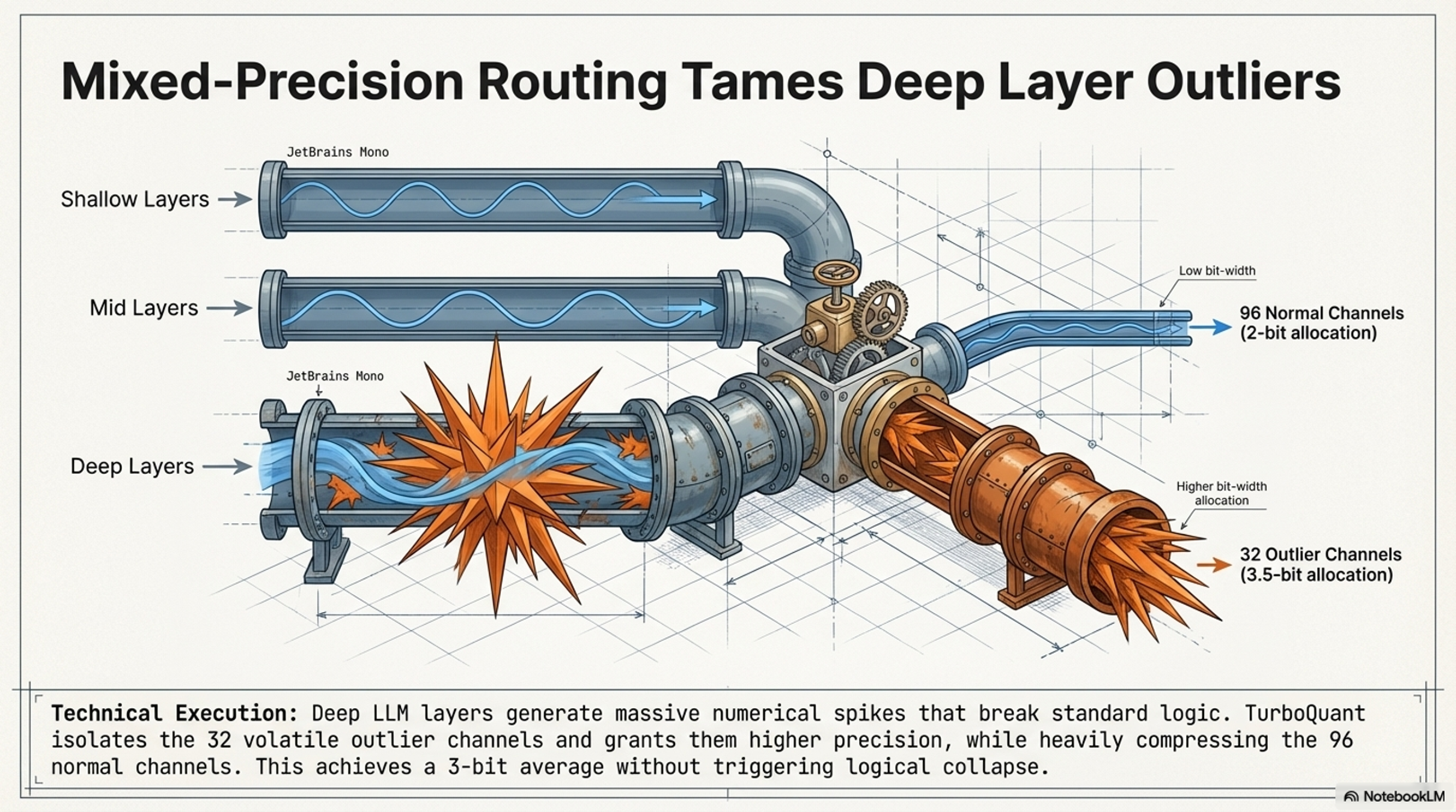
- 혼합 정밀도 라우팅: 깊은 레이어의 수치적 스파이크(Outliers)를 관리하기 위해 32개의 휘발성 아웃라이어 채널에는 3.5비트 고정밀도를, 나머지 96개 일반 채널에는 2비트를 할당하여 평균 3비트(Effective 3-bit) 수준에서 100%의 리콜(Needle-in-a-Haystack 벤치마크 기준) 성능을 확보했습니다.

4. 하드웨어 공생(Hardware Symbiosis): 커널 퓨전과 아키텍처적 가속
TurboQuant는 단순 알고리즘을 넘어 실리콘 단에서 연산 강도(Arithmetic Intensity)를 극대화하도록 설계되었습니다.
- 커널 퓨전(Kernel Fusion) 및 가속: 무작위 회전 연산과 메모리 접근 로직을 단일 Triton/JAX 커널 루프로 통합했습니다. 역양자화 코드북이 제거됨에 따라 데이터는 HBM에서 SRAM으로 즉각 이동하며, 연산 코어의 대기 시간을 제거합니다.
- 압도적 성능 지표: NVIDIA H100 GPU에서 베이스라인 대비 8배 빠른 추론 속도를 달성했으며, 1536차원 벡터 검색에서 0.0013초라는 즉각적 인덱싱(Near-instant indexing) 성능을 기록했습니다. 또한, **Google TPU v5p 환경에서는 58%의 MFU(Model FLOPs Utilization)**를 달성하여 하드웨어 자원을 이론적 피크 성능에 가깝게 활용함을 입증했습니다.

5. 지능형 메모리로의 진화: PIM/PNM과 TurboQuant의 시너지
전통적인 메모리 증설 방식은 전력 효율성과 비용 측면에서 한계에 도달했습니다. TurboQuant는 메모리 자체가 연산 능력을 갖춘 PIM(Processing-In-Memory) 및 PNM(Processing-Near-Memory) 아키텍처로의 전환을 강력히 요구합니다.
- 알고리즘-하드웨어 공동 최적화: TurboQuant의 Random Rotation 및 Lloyd-Max 로직을 실리콘 레이어에서 직접 가속하는 전용 하드웨어 설계가 필수적입니다. 데이터가 메모리 경계를 넘기 전 3.5비트로 압축된 상태에서 처리된다면, 데이터 이동 거리 최소화를 통해 극적인 대역폭 이득을 얻을 수 있습니다.
- 전략적 가치: 이는 '메모리 벽'을 물리적으로 허무는 것이 아니라, 정보 이론적 우아함을 통해 아키텍처적으로 우회하는 것이며, 차세대 AI 컴퓨팅의 표준이 될 것입니다.
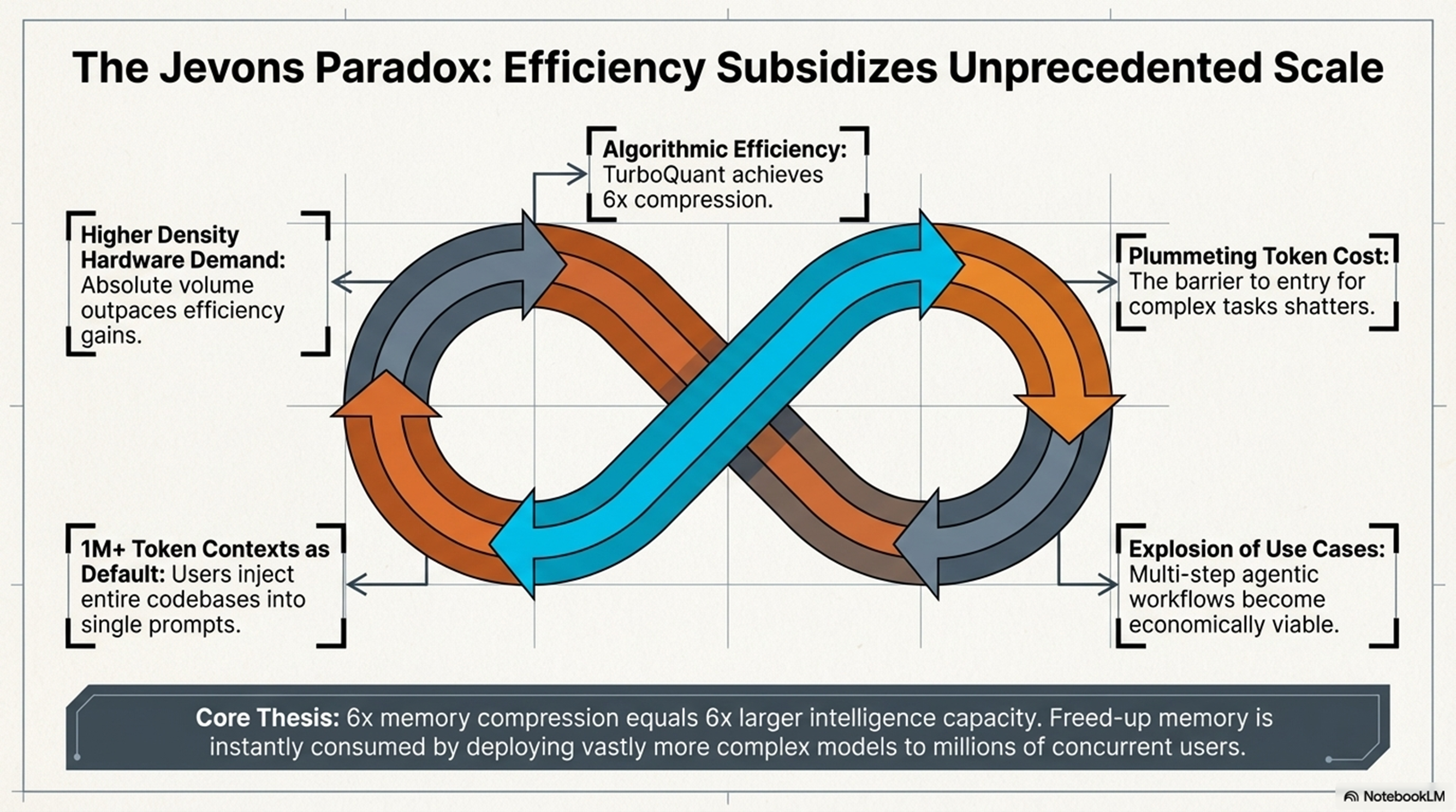
6. 시장 및 전략적 임팩트: 제번스의 역설(Jevons Paradox)과 공급망의 재편
2026년 3월 25일, TurboQuant의 효율 혁신이 하드웨어 수요를 파괴할 것이라는 오판으로 SK Hynix(-5.9%), Micron(-3.4%), Western Digital(-4.7%) 등 주요 제조사의 주가가 급락하는 '시장 패닉'이 발생했습니다. 그러나 이는 경제학의 **'제번스의 역설(Jevons Paradox)'**을 간과한 결과입니다.
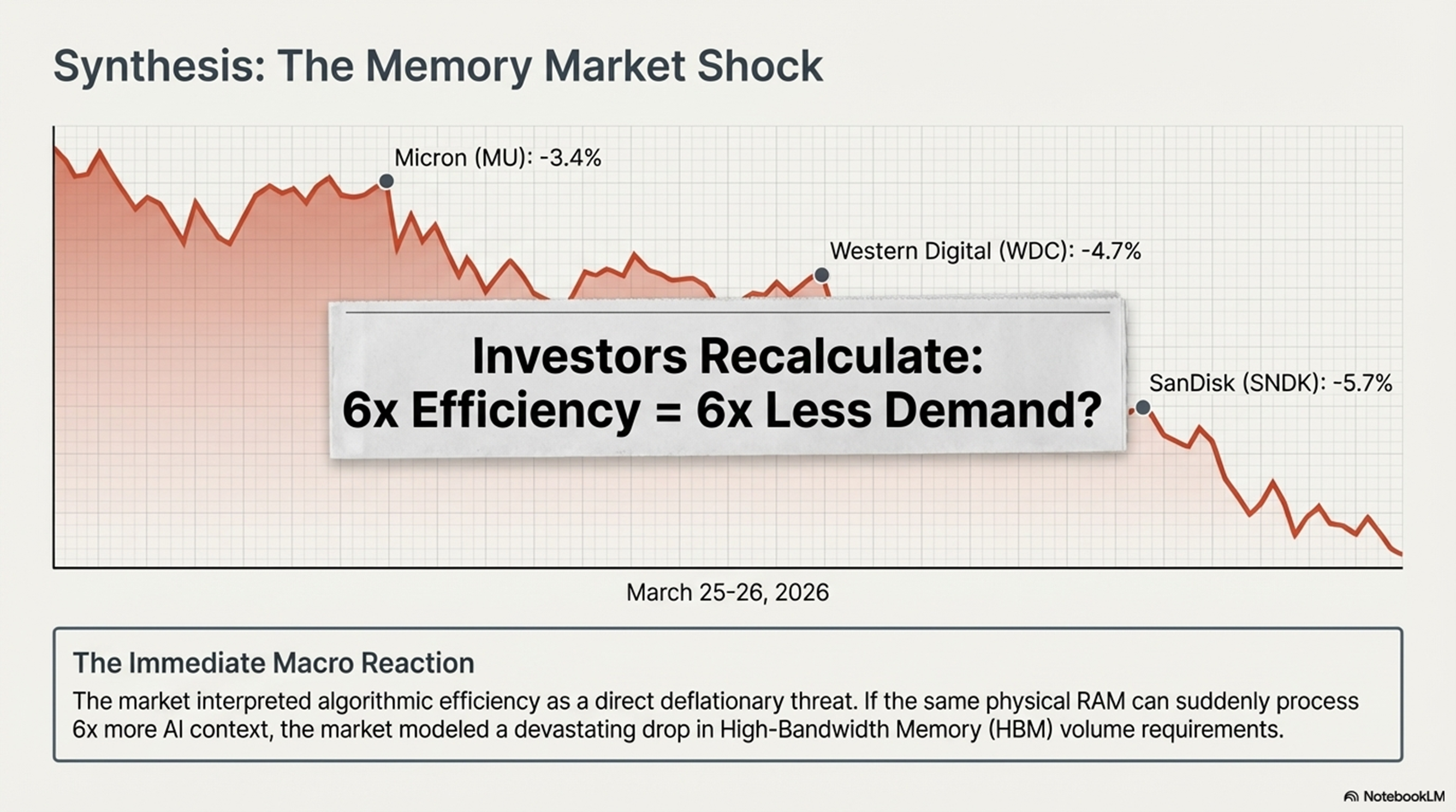
- 수요의 플라이휠(Flywheel of Demand): 토큰당 추론 비용의 하락은 이전에는 불가능했던 멀티스텝 에이전트(Agentic AI) 사용 사례를 폭발시킵니다. 사용자가 1M 이상의 토큰 컨텍스트를 기본 사양으로 요구함에 따라, 시스템 전체 워크로드는 오히려 무겁고 정교해지며 고밀도 하드웨어 수요를 견인할 것입니다.
- 공급망 전략 지침:
- 메모리 제조사: HBM4 로드맵을 유지하되, 초장기 컨텍스트 워크로드에 최적화된 고밀도 적층 기술에 집중해야 합니다.
- 하드웨어 설계자: Nvidia Vera Rubin 및 Google Ironwood와 같은 차세대 아키텍처에서 QJL 및 Polar mapping을 네이티브하게 가속하는 전용 실리콘 설계를 최우선 과제로 삼아야 합니다.
- 엣지 디바이스 제조사: 3.5비트 압축 기술을 활용하여 LPDDR5x/6 기반의 온디바이스 환경(16GB/24GB RAM)에서 클라우드 의존 없이 70B+ 모델을 구동하는 '주권 지능(Sovereign Intelligence)'을 확보해야 합니다.

7. 결론: 알고리즘 지능 시대의 새로운 반도체 패러다임
TurboQuant가 촉발한 혁신은 반도체 산업의 핵심 경쟁력이 물리적 제조 규모에서 **'수학적 우아함을 실리콘에 구현하는 능력'**으로 이동했음을 선포합니다.

6배의 메모리 압축은 단순한 비용 절감을 넘어, 동일한 물리적 공간 내에 6배 더 큰 지능의 수용이 가능해졌음을 의미합니다. 이제 하드웨어의 물리적 임계점은 더 이상 인공지능 발전의 절대적 천장이 아닙니다. 미래의 반도체 주권은 이러한 알고리즘적 상상력을 아키텍처적 현실로 가장 정교하게 통합하는 기업에게 귀속될 것입니다.
https://www.youtube.com/watch?v=BIXD7lhfcBE
출처: 구글 리서치, 안될공학 등
뜨리스땅
'반도체, 소.부.장.' 카테고리의 다른 글
| AI 성능의 병목을 뚫는 열쇠: SRAM (1) | 2026.03.27 |
|---|---|
| AI 반도체 대기근: 왜 글로벌 빅테크는 돈을 싸 들고도 칩을 구하지 못할까? (0) | 2026.03.15 |
| Vera Rubin: NVIDIA가 “랙 전체”를 하나의 칩처럼 설계하기 시작했다 (0) | 2026.02.27 |
| Microsoft의 새로운 AI chip: Maia 200 (0) | 2026.02.22 |
| AI 주도 메모리 슈퍼사이클의 구조적 변화와 공급 제약 요인 (0) | 2026.02.08 |




댓글