Amazon의 최신 AI반도체 '트리니움'(Trainium)은 업계와 전문가들로부터 매우 긍정적인 평가를 받고 있다.
다양한 사용자, 기술 분석가, 고객사의 의견을 종합하면 트리니움은 특히 가격 대비 성능, 대규모 AI 모델 학습 용이성, 그리고 AWS와의 연동 효율성에서 두각을 나타내고 있는 제품으로 보인다.

성능 및 기술적 특징
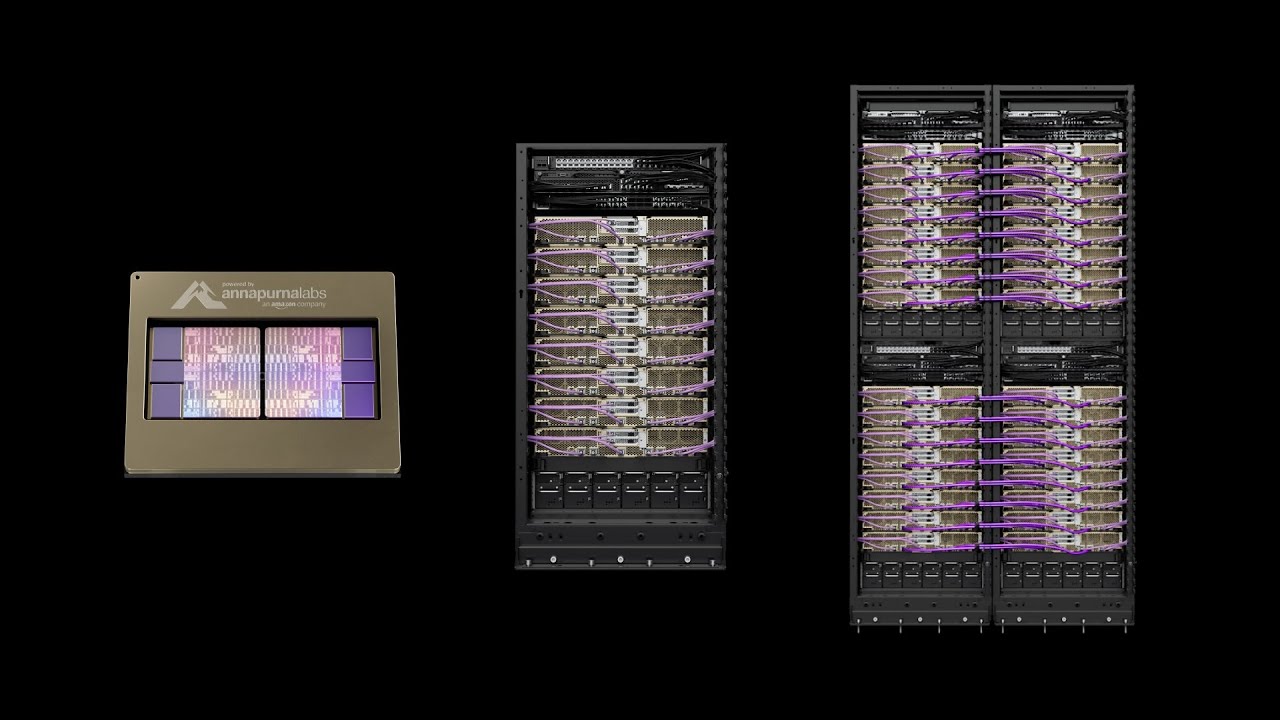
- 트리니움2는 기존 1세대 대비 최대 4배 빠른 학습 성능과 3배 많은 HBM 메모리(최대 96GB), 2배 높은 에너지 효율을 제공
- AWS EC2 Trn2 인스턴스에 16개의 트리니움2 칩이 초고속 NeuronLink로 연결되어 단일 인스턴스에서 최대 20.8 PFLOPS 연산 성능을 구현함
- UltraServer 옵션은 64개 트리니움2 칩을 연결해 현재 업계 최고 수준 집적도를 가지며, 최대 83.2 PFLOPS FP8 연산능력과 6TB HBM3, 초고속 네트워킹 기능을 지원함
- 실제 AI 대기업(앤트로픽, 데이터브릭스 등)이 대형 모델 학습에 채택하고 있음

가격경쟁력 및 실제 효과
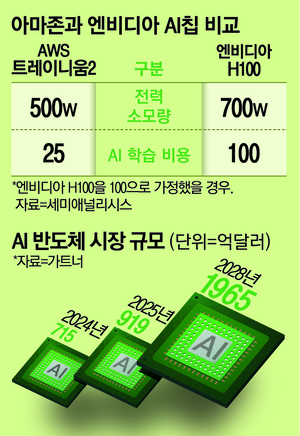
- 엔비디아의 H100 GPU와 비교해 30~40% 뛰어난 가격 대비 성능(가성비)을 제공한다는 평이 많음
- AWS 내부 테스트 및 일부 고객 사용 사례에서는 일반 GPU 대비 학습 및 추론 비용이 25~50% 절감되는 것으로 나타남
- 앤트로픽(Claude), 애플 등 주요 고객들은 대규모 모델 학습 비용 절감 효과를 직접 확인하고 있으며, 추가 도입이 지속될 전망

산업 영향 및 한계
- Amazon은 자체 AI 칩을 통해 엔비디아 의존도를 낮추고 클라우드 인프라의 전략적 차별화를 꾀하고 있음
- 급증하는 AI 연산 수요에 대응해 수십만 개 트리니움 칩이 실제 데이터센터에 배치되고 있음
- AWS 트리니움2의 성공 조건으로 소프트웨어-프레임워크 최적화와 업계 내 보다 폭넓은 도입이 필요함
- 일부 전문가는 현재는 LLM 학습/추론용 인프라에서 트리니움의 효과가 두드러지나, 생태계 확장과 범용 AI 작업에 대한 입증이 추가적으로 필요하다고 평가함

사용자 평가 및 주요 반응
- 에너지 효율, 비용, 학습 속도, 네이티브 AWS 연동성이 우수하다는 반응
- PyTorch, JAX 등 주요 머신러닝 프레임워크와의 호환성, 모델 병렬화 지원이 강화되어 사용자 편의성이 높아졌음
- 트리니움3까지의 로드맵과 차별화 전략이 시장에서 주목받고 있으며, AWS 내부 및 주요 기업(앤트로픽 등)이 대규모 도입을 추진중
1. 트레이니움의 개발 역사
아마존의 트레이니움(Trainium) AI 반도체 개발 역사는 2015년 Annapurna Labs 인수를 기반으로 시작된 아마존의 자체 반도체 개발 전략에서 비롯되었다. 아래는 트레이니움 개발 과정의 주요 이정표와 흐름이다.
2015~2019: 배경과 준비
아마존은 2015년 이스라엘의 반도체 스타트업 Annapurna Labs를 인수하여 AWS 내부 고성능 칩 개발 역량을 확보했다. 이후 Graviton 시리즈(서버용 ARM CPU), Inferentia(추론용 AI 칩)를 개발하며 클라우드 공급망의 핵심 기술 내재화에 집중했다.
2020~2022: 트레이니움 1세대 개발 및 상용화
트레이니움 1세대(Trainium 1)는 2020~2021년 첫 공개되었으며, 대규모 AI 모델 학습(workload) 전용으로 설계된 최초의 AWS 자사 AI 칩이었다. 2022년부터 EC2 Trn1 인스턴스에 탑재되어 기업 실사용이 시작됐다. 가격 경쟁력(최대 50% 학습 비용 절감)과 Native PyTorch/JAX 연동을 주요 강점으로 내세웠다.

2023~2025: 트레이니움 2세대 및 대규모 확장
트레이니움2(Trainium2)는 2023~2024년 개발 완료 후, 대용량 HBM3(최대 96GB), 동급 대비 4배 빠른 연산 속도, 2배 에너지 효율을 갖춘 차세대 칩으로 업그레이드됐다. EC2 Trn2 인스턴스/UltraServer(최대 64칩 집적) 실서비스에 적용되어 Anthropic·Databricks 등 글로벌 고객이 LLM 학습에 사용하고 있다.
2025년 Project Rainier(세계 최대규모 트레이니움 서버팜) 완공, Anthropic을 비롯한 파트너사가 100만 개 이상 칩을 동시 운영하는 슈퍼컴퓨터 구축에 성공하였다.

2025~2027: 트레이니움 3·4세대와 장기 전략
트레이니움3는 2025년말~2026년초 대량 생산 예정이며, TSMC 3nm 공정 기반, PCIe 6 지원, 신형 인터커넥트(NeuronLinkv3)로 시스템 확장/검증 단계에 진입했다.
트레이니움4는 미국 Marvell 주도 tape-out 및 네트워킹 기능 대폭 강화, 2026년 샘플, 2027년 양산 목표로 개발 중이다. 주요 기술 개발 영역은 대규모 분산 학습·추론을 위한 네트워킹·서버 아키텍처와 클라우드 고객의 다양한 AI workload 소화 능력 강화에 집중되어 있다.
2. 트레이니움의 세대별 주요 기술 혁신 및 차이점
트리니움(Trainium) 시리즈는 세대별로 아키텍처, 성능, 메모리, 네트워킹, AI 작업 최적화 등 다양한 영역에서 기술 혁신을 이뤘다. 주요 특징과 차이점은 다음과 같다:
1세대 (Trainium 1)
- 2021년 상용화, AI 학습용 목적 전용칩으로 EC2 Trn1 인스턴스에 최초 적용
- 16GB HBM2 메모리, FP32/FP16/BF16/INT8 지원, 최신 클라우드 대형 모델 학습 효율화
- 주요 혁신: XLA(Accelerated Linear Algebra) 기반 최적화, AWS Neuron SDK를 통한 PyTorch/JAX 네이티브 지원
- 엔비디아 GPU(당시 A100/H100 대비) 대비 40%~50% 수준까지 AI 트레이닝 비용 절감
트리니움 2세대 (Trainium 2)
- 2024~2025년 출하, EC2 Trn2 인스턴스 및 UltraServer로 대규모 서비스
- 96GB HBM3, 메모리 대역폭 1.25TB/s, 연산성능 최대 4배 증가(이전 세대 대비), 에너지 효율 2~2.5배 개선
- NeuronLink 초고속 칩-칩/노드-노드 인터커넥트(8Tbps), 대규모 분산 병렬학습(& 모델 병렬성) 강화
- 가격대비 성능은 최신 GPU 대비 30~40% 개선, Trn2 UltraServer는 64칩 집적 및 6TB 메모리로 슈퍼컴퓨터급 확장 가능
- FP32/FP16/BF16/INT8, 4x4x4 행렬 연산 유닛 추가, 하드웨어적 스마트 전력관리 및 클라우드 최적화
- 대형 언어모델(LLM), 멀티모달 모델, 생성 AI의 실질적인 학습·추론 시간과 비용 대폭 절감

트리니움 3세대 (Trainium 3, 2025~ 예정)
- 2025년 말~2026년 상용화 예정, 3nm 첨단 공정(추정), 256GB 이상 HBM, 더욱 향상된 인공지능 연산 아키텍처 적용
- 연산성능 4배 이상(2세대 대비), 에너지 효율 추가 40~50% 이상 개선 목표
- 최첨단 NeuronLinkv3, PCIe6, 메모리/노드 스케일 확장, 펫타플롭스(10^15 FLOPS)급 분산 AI 아키텍처 지원
- 대규모 멀티모달·생성형 AI, 트릴리언(조) 파라미터급 모델 학습/추론, 복수 노드의 초저지연/고속 연동
- AWS 클라우드 네이티브 옵티마이저, PyTorch·TensorFlow 등 지원 생태계 대폭 확장
차별화 기술 혁신 요약
전 세대 공통적인 측면은 고속 HBM, AI 전용 행렬연산코어, 하드웨어 레벨의 Mixed Precision, 엔드투엔드 소프트웨어 최적화(PyTorch/JAX native), NeuronLink 초고속 네트워킹, 비용/전력 절감 중심 최적화라는 점이다.
2세대 이상에서는 UltraServer·초대형 클러스터, 멀티노드 통합/분산 작업 지원, 대규모 LLM/멀티모달 AI 학습과 실시간 추론 가속에 보다 집중하고 있다.
향후 개발될 3세대에서는 차세대 공정, 메모리/성능/효율 대폭 업그레이드, 생성 AI와 복수 데이터 타입을 위계적으로 처리하는 AI 응용까지 지원할 계획이다.
3. 엔비디아의 GPU와 비교
트리니움(Trainium) 각 세대를 엔비디아의 대응 GPU와 비교하면 다음과 같다. 성능, 메모리, 비용, 에너지 효율 등에서 세대별 차이와 특징이 분명히 존재한다.

세대별 대표 매칭 및 비교
| 세대 | 대표 제품 | 주요성능/스펙 | 매칭되는 GPU | 성능 비교 및 특성 |
| Trainium 1 | EC2 Trn1 | FP16/BF16: ~500TF | V100, A100 | V100 대비 2~5배 빠름, A100 대비 비용·성능 우위 |
| Trainium 2 | EC2 Trn2 | FP8: 1.3PF/chip HBM3 96GB 가성비 30~40% ↑ |
H100, H200 | H100 FP8=1.98PF, Trn2=1.3PF (동급, 집적 시 경쟁력), 비용·전력효율 우위, H200와 집적시 유사 |
| Trainium 3 | 예정 (2025) | FP8/FP16 등 4배↑ HBM 대폭↑ Pcle6 등 차세대 인터커넥트 |
Blackwell(B100), GB200 | B100, GB200 대비 단일칩 FLOPS는 열세, 집적/비용/에너지 효율은 경쟁력, 40%↑ 효율 목표 |
Trainium 1: 엔비디아 V100 (16GB HBM2, ~125TF FP32) 및 초기 A100(40GB HBM2, ~312TF FP16)과 비교 시, 실질적인 AI 학습 속도와 비용 면에서 2~5배 속도 우위 및 3~8배 비용 절감을 입증한 벤치마크가 많았다.
Trainium 2: 엔비디아 H100(80GB HBM3, FP8 1.98PF/chip)과 직접적 경쟁 구도. Trn2 단일칩은 FP8 1.3PF로 H100보다 낮으나, UltraServer 등의 집적 구성에서는 유사한 성능과 훨씬 높은 확장성·비용 효율(30~40% 우위)·에너지 절감 효과를 제공한다. 실제 실리콘 기준, H100/H200과 실서비스 스펙에서 맞붙는 상황.
Trainium 3: Blackwell(B100, FP8 20~24PF/chip)·GB200 등과 경쟁할 예정. 단일칩 peak FLOPS는 Blackwell/GB200이 우위이나, 트레이니움3는 집적, 네이티브 AWS 클라우드 환경, UltraCluster, 에너지 효율(40% 개선), 대규모 모델 작업에서 비용·운영 효율로 차별화를 시도하고 있다.
요약 비교
- 단일칩 연산 효율(FLOPS): 최신 엔비디아 GPU가 우위 (특히 Blackwell/GB200).
- 집적/확장, 비용, 에너지: 트레이니움2~3세대가 AWS 네이티브 인프라에서 30~40% 비용효과, 40% 에너지 효율로 강점.
- 생태계: 엔비디아 CUDA 생태계가 매우 강력, AWS는 Neuron SDK로 호환성 강화 중.
- 실제 활용 및 대규모 모델 학습/운영: 트레이니움2 UltraServer/UltraCluster(수만~수십만칩 규모)는 집적 확장성이 매우 뛰어나다는 평가.
4. 주요 고객사별 사용 현황 및 반응
Anthropic (Project Rainier)
세계적으로 주목받는 AI 스타트업 앤트로픽(Anthropic)은 ‘Claude’ 시리즈 대형 언어모델(LLM)의 학습에 트리니움2를 대규모로 도입했다. 2025년 기준, 최소 50만~100만 개에 이르는 트리니움2 칩을 사용할 계획을 밝혔으며, 이 칩들을 통해 세계 최대 AI 슈퍼컴퓨팅 클러스터를 운영할 예정이다.
연산 성능은 수백 엑사플롭스(ExaFLOPS) 단위에 이른다. 이 인프라는 AWS의 EC2 UltraServer(한 노드에 트레이니움 64개 집적)·UltraCluster 기술을 바탕으로 멀티모달, 생성형 AI 등 대규모 모델 학습 및 추론 작업을 지원한다.
앤트로픽은 트리니움2 사용으로 기존 대비 대폭 향상된 속도와 비용 효율성을 달성했다고 밝혔다.
Databricks
세계 최대 데이터 및 AI 플랫폼 기업 Databricks도 트리니움2 인스턴스를 도입해 Mosaic AI 기반 고객 모델 학습에 활용한다. 모델 학습 전체 비용(TCO)을 30%까지 낮출 수 있다고 공식 발표했으며, 글로벌 고객 대상으로 트리니움 기반 서비스를 확대하고 있다.
Stockmark Inc.
일본의 AI/언어모델 전문 기업 Stockmark는 256개의 트리니움 인스턴스로 13B 파라미터 LLM을 학습했다. 자사 서비스(Anews 및 SAT)를 위한 모델 개발·운영에 적극적으로 도입했으며, 향후 트리니움2 기반 대규모 확장도 준비 중이다.
Brave Software
7천만 명 이상의 사용자를 보유한 글로벌 웹브라우저·검색엔진 회사 Brave는 자사 LLM 기반 검색서비스, AI 요약, 개인정보 보호 기능에 트리니움2 칩을 도입했다고 밝혔다. 앞으로 증가하는 검색 트래픽 및 AI 서비스에 맞춰 AWS 트리니움 칩 사용을 더욱 확대할 계획이다.
기타 사례
AWS 공식 웹사이트에는 Databricks, Ricoh, NinjaTech AI, Arcee AI 등 복수의 고객사가 트리니움 인스턴스의 비용 및 성능효과를 입증했다고 언급되어 있다. 2025~2026년에는 추가적으로 다양한 기업(특히 데이터·AI·검색·언어모델·클라우드 서비스 분야)들이 트리니움2 도입을 발표할 것으로 전망된다.
4.1. 고객 만족도 및 평가
대부분의 고객사는 "기존 GPU 대비 20~30% 이상 비용 절감, 대규모 AI 모델 학습 시간 대폭 단축, AWS 네이티브 인프라와의 통합성, 처리 효율성"에서 높은 만족을 보임.
Anthropic, Databricks 등은 자체 연구 및 서비스 현장에서 이전 대비 "5배 이상" 확장 가능한 훈련 인프라, 실서비스 품질 및 응답 속도의 체계적 향상을 확인했다고 밝힘.
실제 사례 기반 공식 인터뷰·성명에서 "클러스터 확장, 개발 편의성, 트레이닝 최적화 도구(Neuron SDK 등)까지 빠른 기술 적응과 높은 비용 효율성을 실감한다"는 언급이 반복됨.
중소기업(Karakuri, Stockmark 등)도 신속한 LLM 개발 및 서비스화에 대해 매우 긍정적인 피드백을 남김.

4.2. 향후 전망
업계 내 일부(특히 보수적인 엔터프라이즈, 레거시 GPU 중심 기업)는 CUDA 생태계 강점, 소프트웨어 포팅 부담 등으로 여전히 엔비디아 우선 사용 경향.
그러나 대규모 AI 및 대형 LLM 학습에서는 Trainium2 기반 클라우드 인프라가 점차 적극 채택되고 있으며, 제품 만족도 및 추가 대형 도입 고객 확대가 빠르게 진행되고 있음.
결론적으로, Anthropic·Databricks 등 초대형 AI/데이터 기업부터 일본 스타트업·바이오·핀테크·검색 등 다양한 분야 고객이 수십~수십만개 규모로 트레이니움을 도입했고, 대부분 빠른 확장성과 비용성능 측면에서 높은 만족도를 보이고 있어서, 향후 지속적으로 확대될 가능성이 있음
출처: Amazon, GlobalTechResearch, AI Magazine.com, Business Post, Amazon Science, AWS, 매일경제, Benzinga
뜨리스땅
'반도체, 소.부.장.' 카테고리의 다른 글
| Google의 TPU v7 성능의 핵심 요소: 시스템 아키텍처와 네트워킹 기술 (5) | 2025.11.29 |
|---|---|
| AI 데이터센터 붐이 한국 배터리 산업의 촉매가 되다 (0) | 2025.11.09 |
| Google Quantum AI - 검증 가능한 양자 우위 달성 (1) | 2025.10.24 |
| Datacenter를 위해 태어난 인텔의 새로운 서버용 CPU: Xeon 6+ (Clearwater Forest) (0) | 2025.10.19 |
| IBM의 AI 서버 신제품 - Power11: AI 서버 위한 아키텍처 진화 (0) | 2025.10.16 |




댓글