1. 서론: AI 인프라의 새로운 지평
AI 시대의 도래는 소프트웨어 개발의 비용 구조를 근본적으로 바꾸어 놓았습니다. 과거에는 개발자 인건비가 총소유비용(TCO)의 상당 부분을 차지했지만, 오늘날 AI 소프트웨어는 그 기반이 되는 하드웨어 인프라가 자본 지출(Capex)과 운영 비용(Opex)에 훨씬 더 큰 영향을 미칩니다.
이제는 개별 칩의 성능을 의미하는 마이크로아키텍처를 넘어, 수천 개의 칩을 하나의 거대한 컴퓨팅 단위로 엮어내는 시스템 아키텍처의 설계가 AI 애플리케이션의 확장성과 경제성을 결정하는 핵심 요소가 되었습니다. Google은 이러한 시스템 수준 엔지니어링의 중요성을 일찍이 간파하고, 2017년 TPU v2부터 랙 규모의 상호 연결 기술을 개척하며 AI 인프라의 혁신을 주도해 왔습니다.
현재 AI 시장은 Nvidia의 강력한 지배력이 지속되는 가운데, Google의 TPU가 Anthropic과 같은 선도적인 AI 연구소의 대규모 채택에 힘입어 가장 위협적인 대안으로 급부상하고 있습니다.
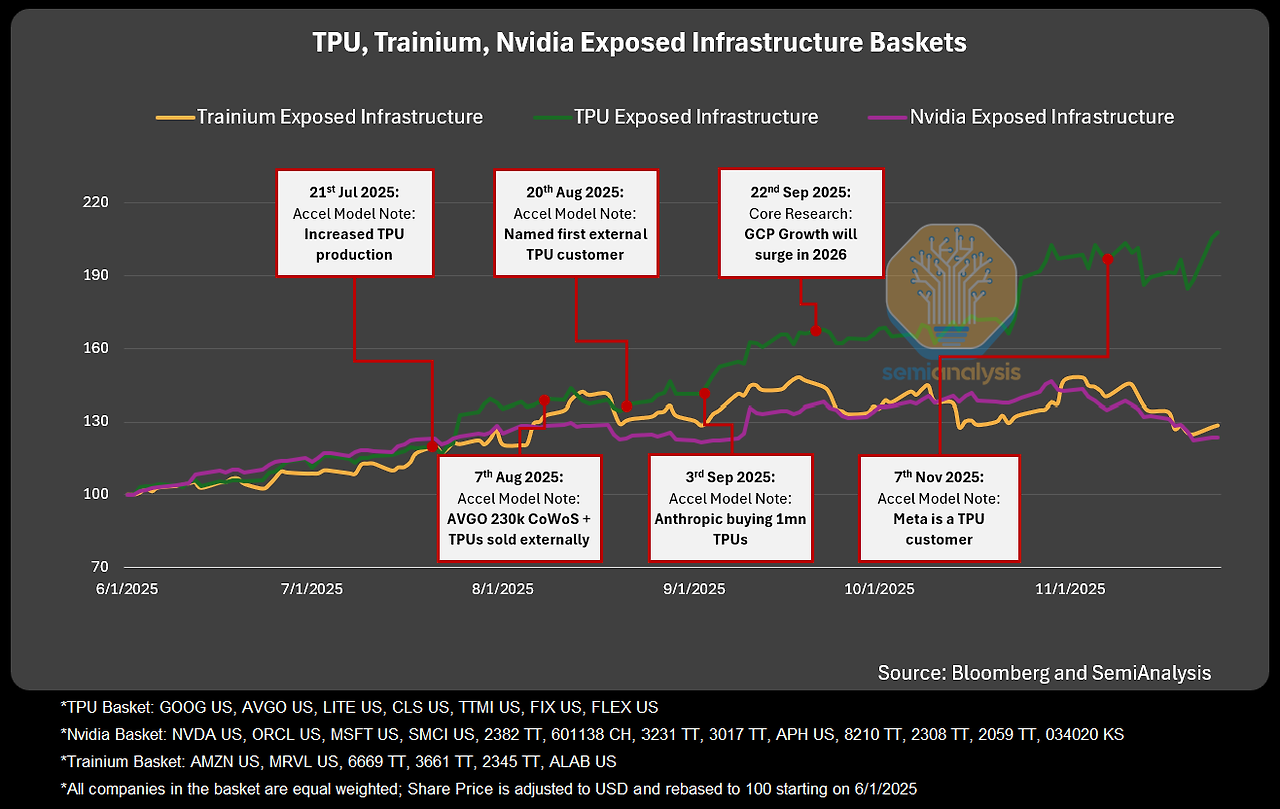
세계 최고의 모델로 꼽히는 Anthropic의 Claude 4.5 Opus와 Google 자신의 Gemini 3가 모두 TPU 인프라에서 훈련 및 추론되고 있다는 사실은 TPU 플랫폼의 기술적 역량을 명확히 증명합니다. 이는 단순한 칩 경쟁을 넘어, 시스템 전체의 효율성과 확장성을 중심으로 한 새로운 패러다임의 경쟁이 시작되었음을 시사합니다.
우리는 Google TPU v7 시스템의 핵심 경쟁력인 시스템 및 네트워킹 아키텍처를 들여다봐야 합니다. 엔지니어, 시스템 설계자, 그리고 기술 전략가들이 TPU v7이 어떻게 압도적인 확장성과 획기적인 총소유비용(TCO) 이점을 달성하는지 이해할 수 있도록, 랙 수준의 설계부터 데이터센터 규모의 네트워킹에 이르는 기술적 사항들에 대한 이해가 필요합니다.
이를 통해 우리는 AI 시대의 인프라가 나아갈 방향에 대한 깊이 있는 통찰을 얻게 될 것입니다. 이러한 거대한 시스템을 이해하기 위한 첫걸음은 가장 기본적인 구성 단위인 랙(Rack) 아키텍처입니다.
2. TPU v7 시스템의 핵심 구성 요소: Ironwood 랙 아키텍처
대규모 AI 시스템에서 랙은 단순한 서버 보관함이 아니라, 전체 슈퍼컴퓨터의 성능과 효율성을 결정하는 전략적 기본 단위입니다. Google의 TPU v7 'Ironwood' 랙은 고밀도의 컴퓨팅 유닛, 혁신적인 냉각 시스템, 그리고 정교한 네트워킹 인터페이스를 하나의 물리적 공간에 집약적으로 통합한 결과물입니다.
이 랙 아키텍처는 수천, 수만 개의 TPU로 구성되는 거대한 슈퍼팟(Superpod)의 안정적인 성능 기반을 마련하는 핵심적인 역할을 수행합니다.

Ironwood 랙은 다음과 같은 주요 하위 시스템들로 정밀하게 구성되어 있습니다.
- TPU 트레이 (TPU Tray): 랙의 핵심 컴퓨팅 유닛으로, 랙당 총 16개의 트레이가 장착됩니다. 각 트레이에는 4개의 강력한 TPU v7 칩 패키지가 탑재되어 랙당 총 64개의 TPU를 구성합니다.
- CPU 호스트 트레이 (CPU Host Tray): 각 TPU 트레이와 고속 PCIe 케이블로 연결되어 데이터 로딩, 전처리 등 보조적인 연산을 수행하고 전체 시스템을 제어합니다. 냉각 방식에 따라 구성이 달라져, 액체 냉각 랙은 TPU 트레이와 1:1 비율로 16개가, 공랭식 랙은 2:1 비율로 8개가 장착됩니다.
- 전원 공급 장치 (Power Shelves & BBU): 416V AC 고전압 입력을 받아 시스템에 안정적인 전력을 공급하며, 예기치 않은 정전 상황에 대비하기 위한 배터리 백업 유닛(BBU)을 포함합니다.
- 네트워킹 장비 (ToR Switch & Optical Patch Panels): 랙 상단에는 외부 데이터센터 네트워크(DCN)와의 연결을 위한 ToR(Top-of-Rack) 스위치가 위치하며, 랙 간 광학적 상호연결(ICI)을 위한 광 패치 패널이 마련되어 있습니다.
- 냉각 시스템 (Liquid manifolds): Google은 이미 TPU v3부터 액체 냉각 방식을 도입해왔습니다. Ironwood 랙은 이 기술을 더욱 발전시켜, 각 칩의 연산 부하에 따라 밸브가 냉각수 유량을 능동적으로 조절하는 혁신적인 설계를 채택했습니다. 이를 통해 전력 효율성을 극대화하고 안정적인 시스템 운영을 보장합니다.
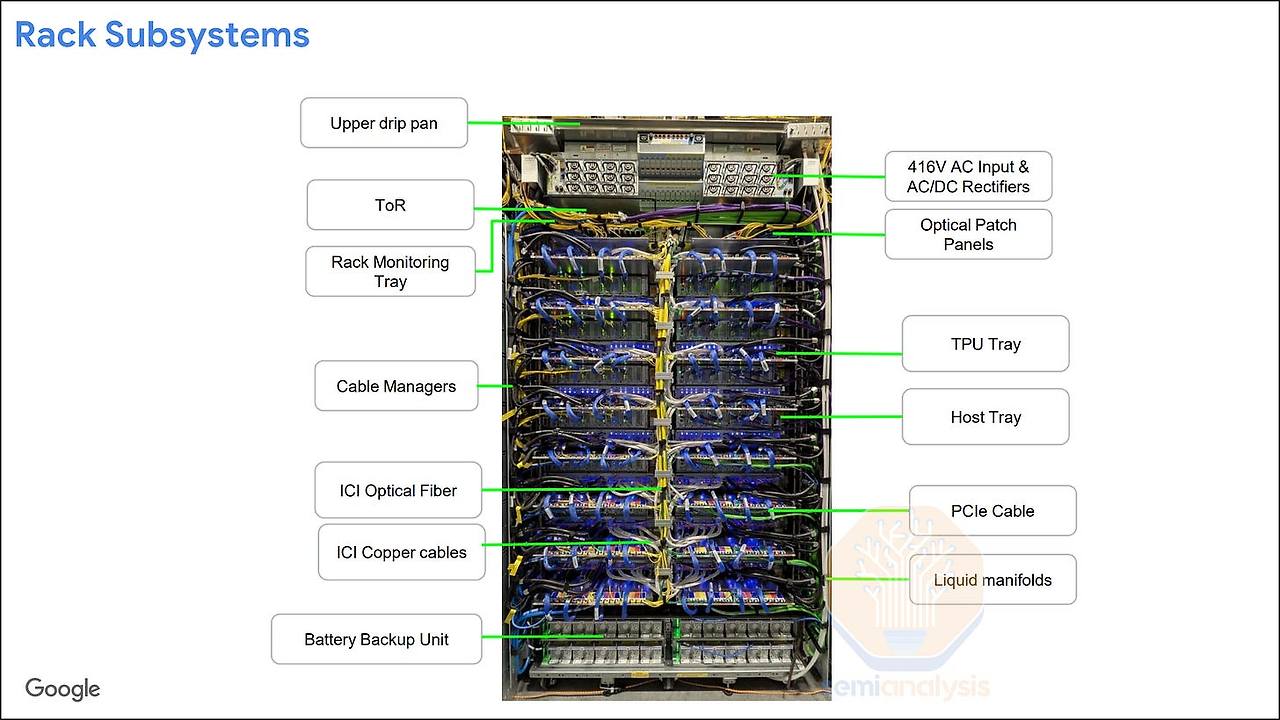
TPU 트레이는 Ironwood 시스템의 심장부라 할 수 있습니다. 각 트레이 보드에는 4개의 TPU v7 칩이 실장되어 있으며, 칩 간 상호연결(ICI) 네트워크를 구성하기 위한 16개의 OSFP(Octal Small Form-factor Pluggable) 케이지와 CPU 호스트와의 연결을 위한 4개의 CDFP PCIe 케이지가 정교하게 배치되어 있습니다.
이러한 설계는 Nvidia의 NVL72와 같은 통합 시스템 철학과 의도적으로 다른 길을 갑니다. Google의 아키텍처는 복잡하고 거대한 모놀리식 백플레인을 피하고, 표준화된 외부 케이블(구리 및 광)을 통해 랙 내부 및 랙 간 연결을 모두 구현하는 방식을 전략적으로 선택했습니다.

이 접근 방식은 모듈성, 서비스 용이성을 향상시키고 잠재적인 단일 장애점을 줄여줍니다. 이처럼 효율적으로 설계된 랙 아키텍처는 다음 섹션에서 다룰 TPU v7의 핵심 기술, 즉 3D 토러스 칩 간 상호연결(ICI) 네트워크를 구현하기 위한 물리적 토대를 제공합니다.
3. 칩 간 상호연결(ICI): 3D 토러스 네트워크의 구현
AI 모델의 규모가 기하급수적으로 커짐에 따라, 수천 개의 가속기를 마치 하나의 거대한 칩처럼 유기적으로 작동하게 만드는 칩 간 상호연결(ICI, Inter-Chip Interconnect) 네트워크의 중요성이 그 어느 때보다 부각되고 있습니다. TPU v7은 3D 토러스(3D Torus) 라는 정교한 네트워크 토폴로지를 채택하여, 칩 간 통신 지연 시간을 최소화하고 대규모 병렬 처리에 필요한 총 대역폭을 극대화하는 전략을 구사합니다.
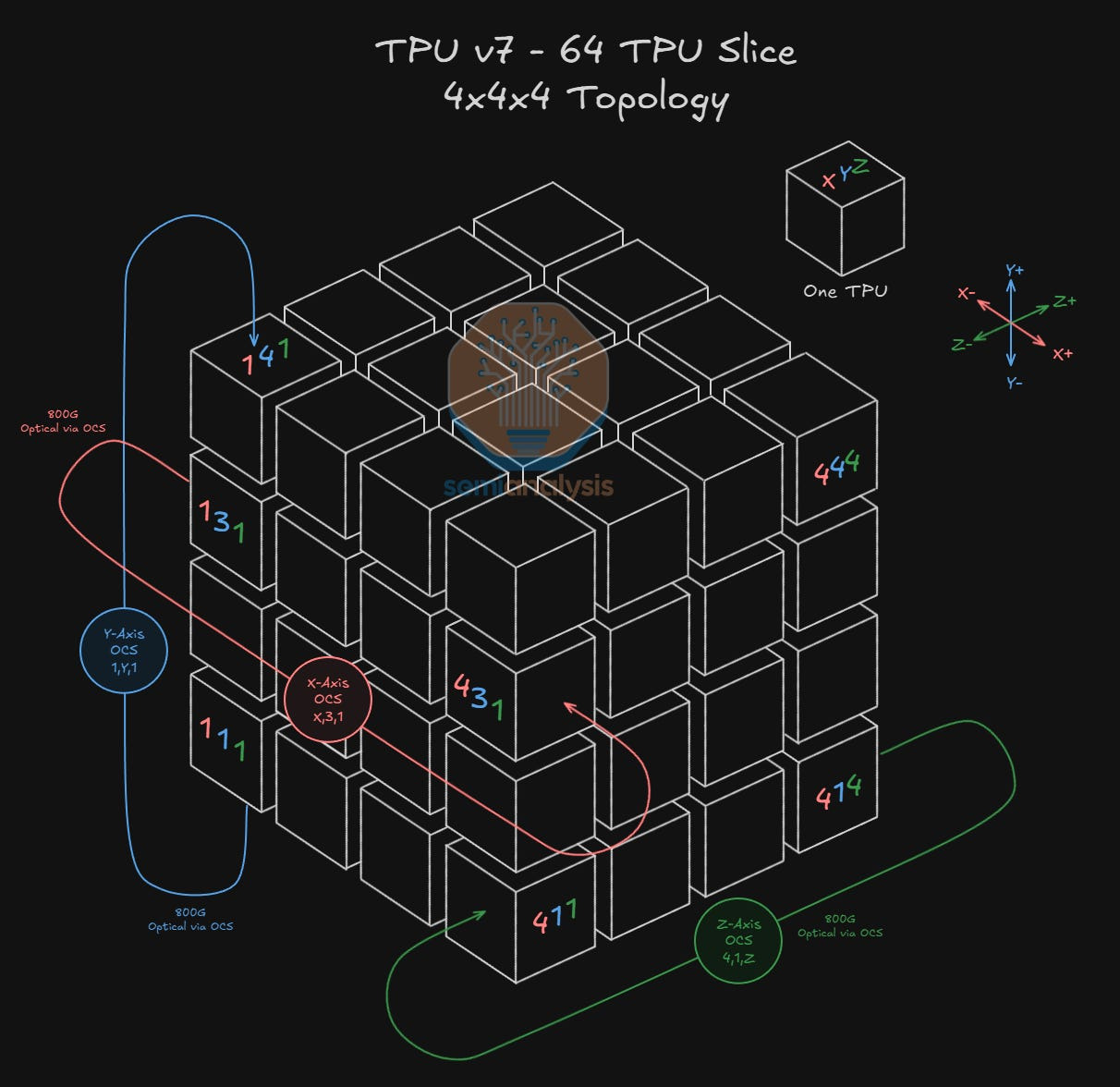
TPU v7 ICI 네트워크의 가장 기본적인 논리적 구성 단위는 '4x4x4 큐브(Cube)' 입니다. 이는 64개의 TPU가 X, Y, Z 세 축으로 배열된 정육면체 형태의 논리적 구조를 의미하며, 이 큐브 하나가 물리적으로 앞서 설명한 Ironwood 랙 하나에 정확히 매핑됩니다. 이 큐브는 랙 내부의 전기적 연결과 랙 외부의 광학적 연결을 통해 더 큰 시스템으로 확장되는 기반이 됩니다.
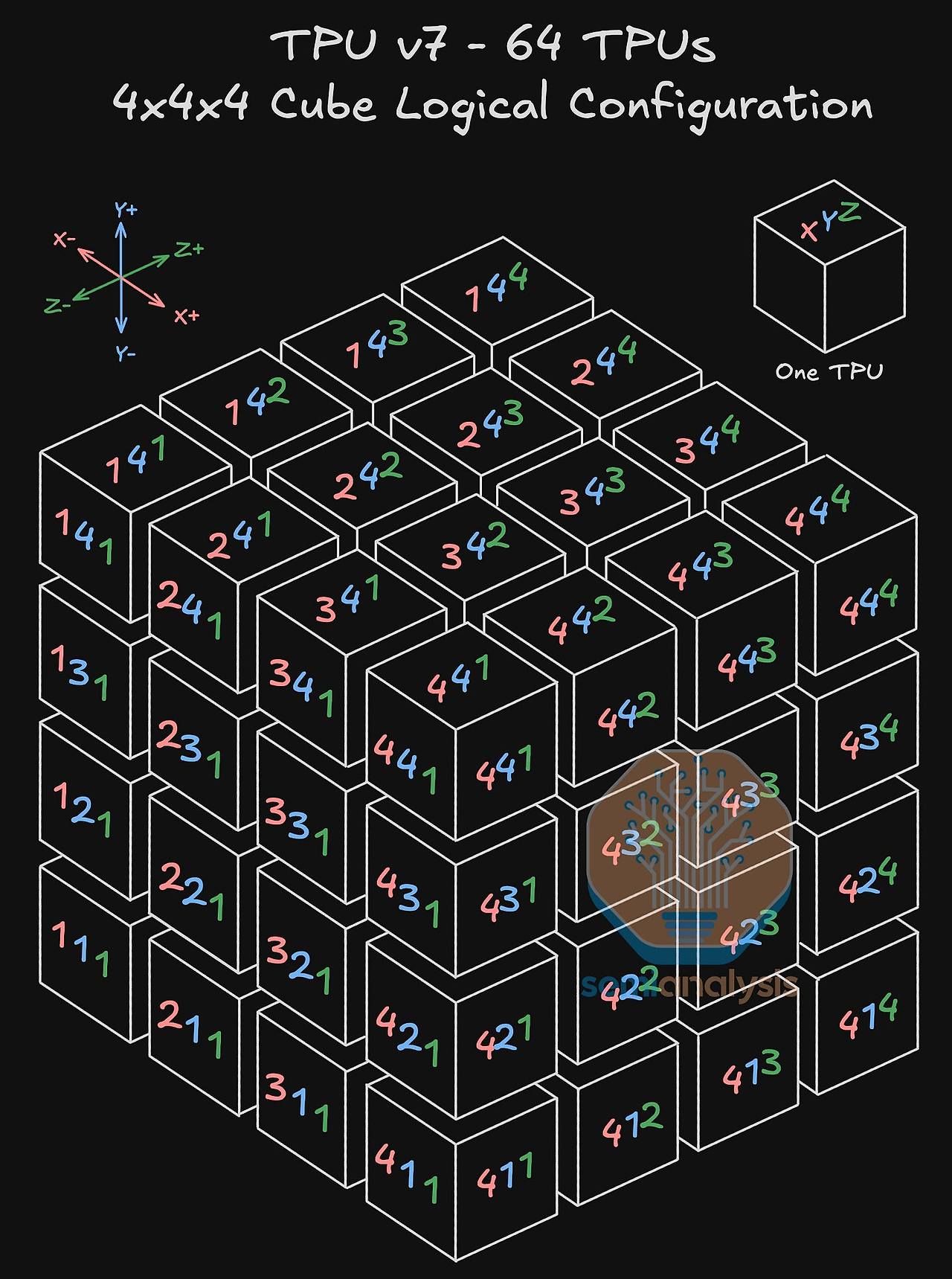
3D 토러스 토폴로지의 작동 원리는 각 TPU가 자신의 3차원 좌표를 기준으로 6개의 이웃과 직접 연결된다는 개념에 기반합니다. 구체적으로, 모든 TPU는 X, Y, Z의 세 축 각각에 대해 양방향으로 2개씩, 총 6개의 논리적으로 인접한 (logically adjacent) TPU와 직접 통신 경로를 가집니다. 이는 마치 3차원 격자 공간의 각 점이 상하, 좌우, 앞뒤의 이웃 점들과 모두 연결된 것과 같습니다. 이 구조는 칩 간 데이터 전송 거리를 예측 가능하게 하고 통신 병목 현상을 최소화하는 데 매우 효과적입니다.
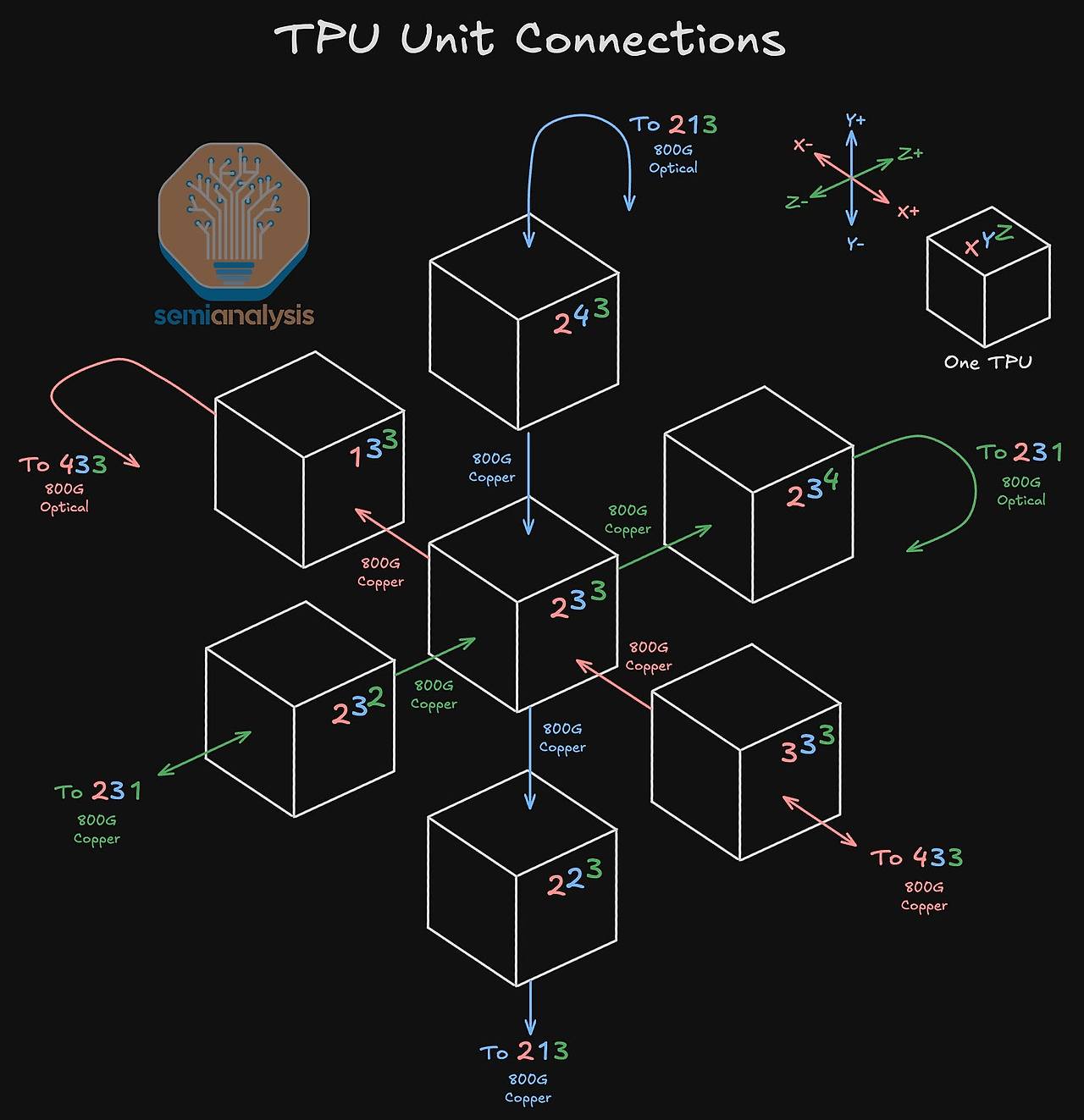
64개 TPU로 구성된 큐브 내에서 각 TPU의 위치에 따라 이 6개의 연결을 구현하는 물리적 방식은 달라집니다. 큐브의 내부에 있는지, 아니면 외부와 맞닿은 면, 모서리, 또는 꼭짓점에 위치하는지에 따라 구리 케이블과 광 트랜시버의 조합이 결정됩니다.
| TPU 위치 | 큐브 내 개수 | 구리 케이블 연결 수 | PCB 트레이스 연결 수 | 광 트랜시버 수 |
| 내부 (Interior) | 8개 | 4개 | 2개 | 0개 |
| 면 (Face) | 24개 | 3개 | 2개 | 1개 |
| 모서리 (Edge) | 24개 | 2개 | 2개 | 2개 |
| 꼭짓점 (Corner) | 8개 | 1개 | 2개 | 3개 |
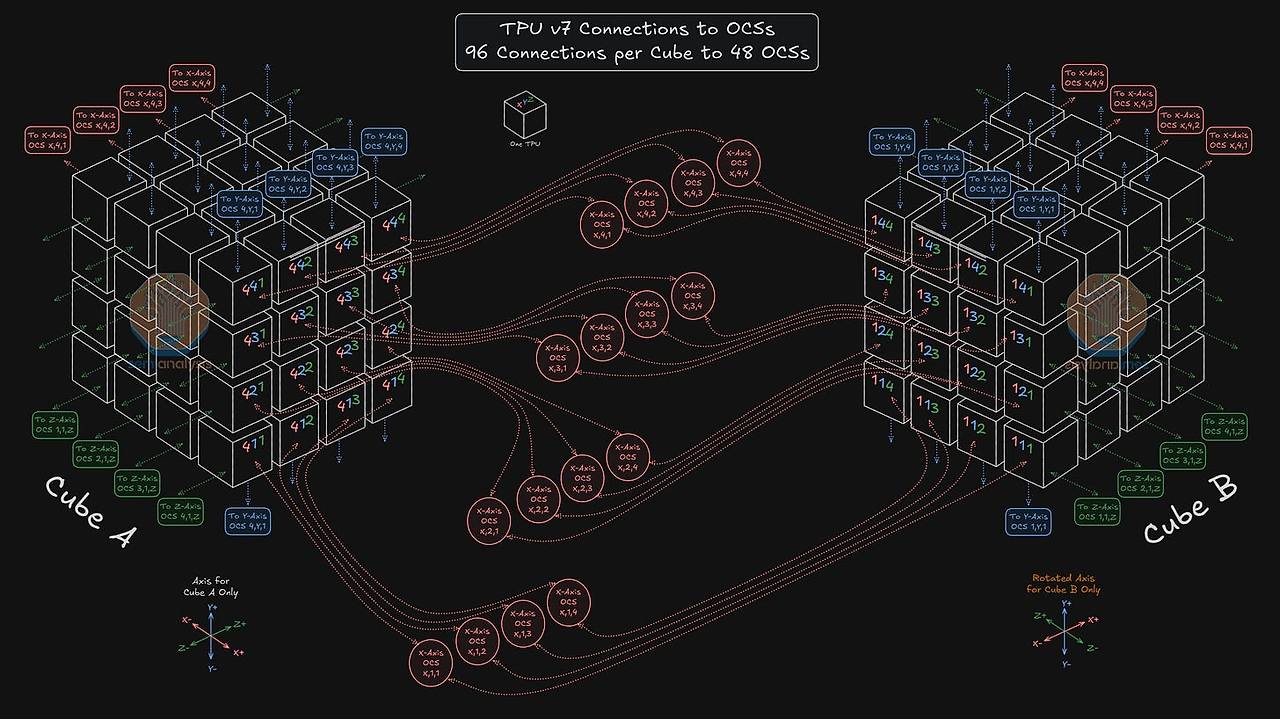
위 표에서 알 수 있듯이, 큐브 내부의 TPU는 모든 연결이 비용 효율적인 구리 케이블과 PCB 트레이스로 이루어지는 반면, 큐브 외곽으로 갈수록 더 먼 거리의 연결(다른 면으로의 래핑 또는 다른 큐브와의 연결)을 위해 광 트랜시버가 사용됩니다. 이 구성을 종합하면, 64개의 TPU로 구성된 단일 랙(큐브)은 총 96개의 광 트랜시버를 사용하며, 이는 TPU 칩당 평균 1.5개의 비율입니다.

이러한 광 연결은 단일 랙의 경계를 넘어 수십, 수백 개의 큐브를 하나로 묶는 확장성의 핵심입니다. 그리고 이 광 신호들의 경로를 소프트웨어로 제어하여 동적으로 네트워크를 재구성하는 역할을 수행하는 것이 바로 다음 섹션에서 다룰 광 회로 스위치(OCS)입니다.
4. 광 회로 스위치(OCS)의 역할: 동적 재구성과 확장성의 열쇠
수천 개의 노드로 구성된 대규모 클러스터에서 네트워크 토폴로지를 동적으로 재구성하는 능력은 시스템의 유연성, 가용성, 그리고 자원 활용률을 극대화하는 데 결정적인 역할을 합니다.
Google의 OCS(Optical Circuit Switch)는 물리적인 케이블 재배선 작업 없이 순전히 소프트웨어 정의 방식으로 광섬유의 물리적 경로를 변경하는 혁신적인 기술입니다. 이를 통해 특정 작업에 최적화된 네트워크 토폴로지를 즉시 구성하거나, 장애가 발생한 하드웨어를 네트워크에서 분리하여 시스템 전체의 가용성을 높일 수 있습니다.

OCS의 작동 원리는 기존의 전자 패킷 스위치(EPS)와 근본적인 차이를 보입니다. EPS는 들어온 광 신호를 전기 신호로 변환하여 패킷 헤더를 읽고 라우팅 결정을 내린 뒤, 다시 광 신호로 변환하여 내보내는 과정을 거칩니다. 반면, OCS는 신호 변환 과정 없이, 수많은 미세 전자기계 시스템(MEMS) 거울 배열을 이용해 입력 포트로 들어온 빛을 물리적으로 반사시켜 출력 포트로 경로를 직접 전환합니다.

이 방식은 신호 변환에 따른 지연이 없어 더 낮은 지연 시간을 달성하며, 복잡한 전자 회로가 필요 없어 더 높은 전력 효율성을 제공합니다.
Google은 Apollo 프로젝트를 통해 OCS의 포트 활용도를 극대화하고 비용 효율성을 높이는 두 가지 핵심적인 광학 기술을 개발했습니다.
- CWDM8 (Coarse Wave Division Multiplexing): 파장 분할 다중화 기술을 사용하여, 각각 100G의 대역폭을 가진 8개의 서로 다른 파장의 빛을 하나의 광섬유 쌍에 동시에 실어 보냅니다. 이를 통해 단일 광섬유 쌍으로 총 800G의 데이터를 전송할 수 있게 되어 필요한 광섬유의 수를 획기적으로 줄였습니다.
- 광 서큘레이터 (Optical Circulator): 일반적으로 송신(Tx)과 수신(Rx)에 각각 하나씩, 총 두 가닥의 광섬유가 필요한 양방향 통신을 단 한 가닥의 광섬유로 가능하게 만드는 부품입니다. 서큘레이터는 트랜시버에서 나가는 송신 신호와 외부에서 들어오는 수신 신호를 분리하여, 단일 광섬유 가닥으로 양방향 통신을 구현합니다.
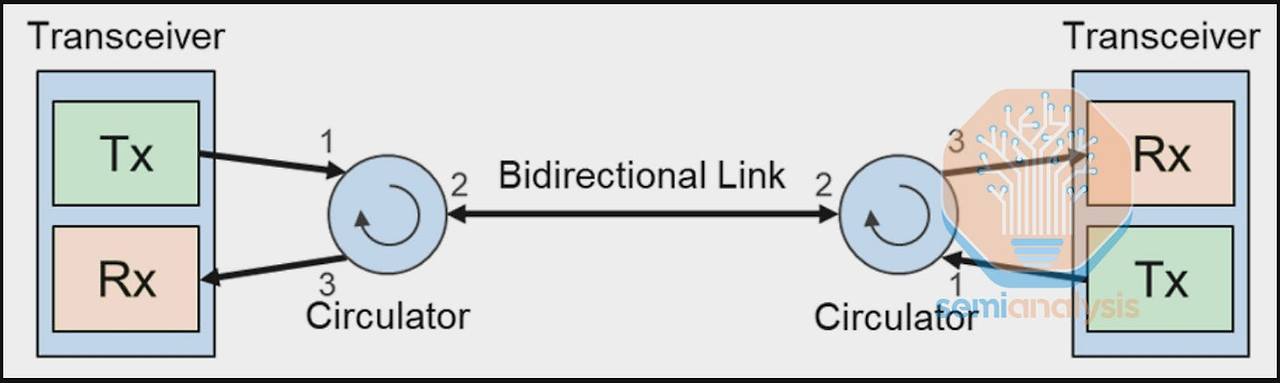
이 두 기술의 조합으로, 800G의 양방향 데이터 전송이 단 한 가닥의 광섬유로 가능해졌고, 이는 OCS의 각 포트가 처리할 수 있는 대역폭과 효율성을 극대화합니다. OCS와 이러한 첨단 광학 기술의 결합은 수많은 64-TPU 큐브들을 마치 레고 블록처럼 유연하게 연결하여, 사용자가 원하는 어떤 형태의 거대한 단일 클러스터라도 동적으로 구성할 수 있는 강력한 기반을 제공합니다.
5. 대규모 클러스터 구축: OCS를 활용한 슬라이스 확장
최신 AI 모델을 훈련시키기 위해서는 작업의 특성에 맞춰 다양한 크기와 형태의 가속기 그룹, 즉 '슬라이스(slice)'를 효율적으로 구성하고 관리하는 능력이 필수적입니다.
OCS는 물리적 랙의 위치에 구애받지 않고 논리적으로 인접해야 할 TPU 큐브들을 광케이블로 직접 연결해 주는 역할을 합니다. 이를 통해 결함이 있는 하드웨어를 즉시 우회하거나, 사용자의 특정 병렬 처리 전략에 완벽하게 부합하는 맞춤형 토폴로지(예: 4x4x8, 8x8x16 등)를 동적으로 생성할 수 있어 시스템의 활용성과 가용성을 극대화합니다.
OCS를 사용하여 여러 개의 4x4x4 큐브를 연결해 더 큰 3D 토러스 슬라이스를 만드는 과정은 매우 유연합니다. 예를 들어, 128개의 TPU로 구성된 '4x4x8' 토폴로지를 만든다고 가정해 봅시다. 시스템은 물리적으로 데이터센터 내 어디에 있든 상관없이 정상 상태인 두 개의 큐브(Cube A, Cube B)를 선택합니다.
그리고 OCS를 통해 Cube A의 Z+ 방향 면에 위치한 16개 TPU의 광 연결을 Cube B의 Z- 방향 면에 위치한 16개 TPU에 직접 연결하도록 경로를 설정합니다. 동시에 Cube B의 Z+ 면은 Cube A의 Z- 면과 래핑(wrapping) 연결을 구성하여 완벽한 4x4x8 형태의 3D 토러스를 완성합니다.
이러한 연결 방식이 가져오는 가장 핵심적인 이점은 큐브의 완전한 대체 가능성(fungibility) 입니다. 다수의 사용자(예: 사용자 A, B, C)가 물리적으로는 데이터센터 전체에 흩어져 있는 큐브 풀에서 자원을 할당받더라도, OCS는 이들을 투명하게 연결하여 각 사용자를 위한 완벽한 프라이빗 3D 토러스 슬라이스를 논리적으로 구성합니다. 이는 특정 큐브에 장애가 발생하더라도 전체 시스템의 가용성에 미치는 영향을 최소화하고, 유휴 자원을 효율적으로 통합하여 자원 활용률을 크게 향상시킵니다.

TPU v7이 지원하는 최대 월드 사이즈(world size)인 9,216개 TPU 클러스터는 이러한 원리를 극대화한 결과입니다. 이 거대한 클러스터는 144개의 4x4x4 큐브로 구성됩니다. 각 큐브는 96개의 광 포트를 가지므로, 총 13,824개(144 x 96)의 광 연결을 관리해야 합니다. 이 엄청난 규모의 연결은 각각 144x144 포트를 가진 48개의 OCS를 통해 효율적으로 제어되고 재구성됩니다.

이처럼 OCS를 통해 구성된 대규모 ICI 클러스터(또는 'Pod')들은 그 자체로도 강력하지만, Google의 아키텍처는 여기서 멈추지 않습니다. 여러 개의 ICI 클러스터들을 다시 한번 거대한 네트워크로 연결하여 데이터센터 전체 규모로 확장하는 데이터센터 네트워크(DCN) 개념으로 이어집니다.
6. 데이터센터 네트워크(DCN): 포드를 넘어서는 확장
단일 ICI 클러스터, 즉 포드(Pod)가 수천 개의 TPU를 묶을 수 있지만, 초대규모 AI 워크로드를 처리하기 위해서는 포드의 한계를 넘어 데이터센터 전체를 하나의 거대한 컴퓨팅 패브릭으로 연결하는 네트워크 아키텍처가 필요합니다.
Google의 DCN(Datacenter Network)은 바로 이 역할을 수행하며, OCS 기술을 데이터센터 규모로 확장 적용하여 최대 147,456개의 TPU를 연결하는 경이로운 확장성을 구현합니다. 이는 AI 인프라를 개별 클러스터의 집합이 아닌, 데이터센터 전체를 아우르는 단일 시스템으로 바라보는 Google의 설계 철학을 보여줍니다.
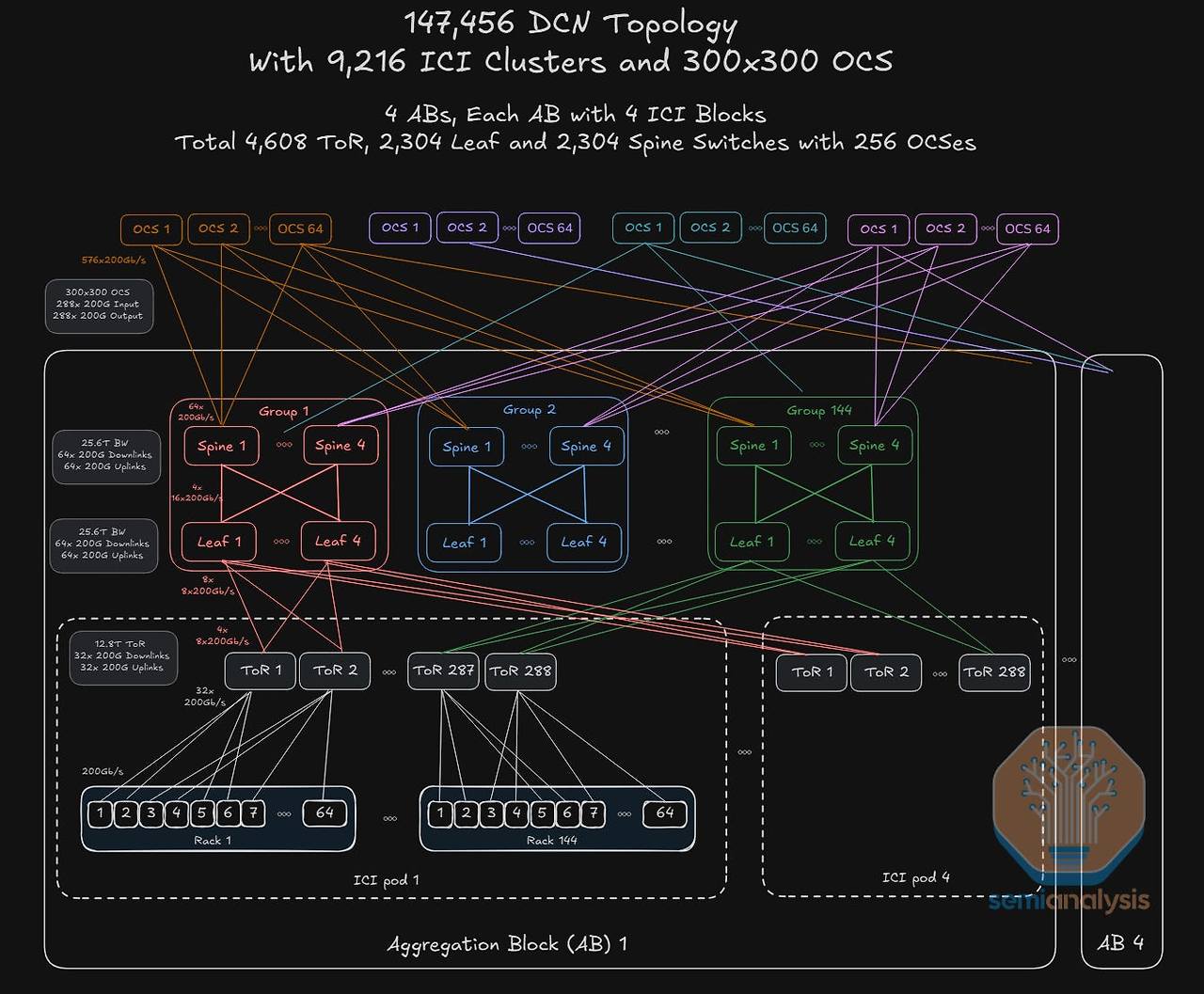
TPU v7의 DCN은 다음과 같은 계층적 구조를 가집니다.
- ICI 포드 (ICI pod): 앞서 설명한 3D 토러스 네트워크로 구성된 기본 클러스터 단위입니다. TPU v7의 경우, 하나의 ICI 포드는 최대 9,216개의 TPU로 구성될 수 있습니다.
- 어그리게이션 블록 (Aggregation Block, AB): 여러 개의 ICI 포드를 하나로 묶는 중간 계층입니다. 예를 들어, 4개의 9,216-TPU ICI 포드가 스위치들을 통해 하나의 어그리게이션 블록을 형성할 수 있습니다.
- DCNI 레이어 (DCNI Layer): 전체 DCN 아키텍처의 최상위 스파인(spine) 계층으로, 여러 어그리게이션 블록들을 상호 연결하는 역할을 합니다. TPU v7 DCN의 가장 큰 특징은 이 DCNI 레이어가 전통적인 고가의 전자 패킷 스위치(EPS)가 아닌, ICI 네트워크에서 사용된 것과 동일한 OCS(광 회로 스위치) 로 구현된다는 점입니다.

DCNI 레이어에서 OCS를 사용하는 것은 시스템의 장기적인 확장성과 운영 효율성에 막대한 이점을 제공합니다. 기존의 EPS 기반 네트워크에서는 새로운 장비 블록을 추가할 때마다 대규모의 케이블 재배선 작업과 네트워크 재설계가 필요했습니다.
하지만 OCS를 사용하면, 새로운 어그리게이션 블록을 시스템에 추가한 뒤 소프트웨어 설정 변경만으로 기존 블록들과의 연결을 동적으로 '재분할(re-striped)'할 수 있습니다. 이는 값비싼 다운타임이나 물리적 작업 없이도 네트워크를 점진적으로 확장할 수 있는 점진적 확장성(incremental expansion) 과 업그레이드 용이성을 의미합니다.
지금까지 살펴본 고도로 통합된 랙, 3D 토러스 ICI, OCS 기반의 동적 재구성, 그리고 계층적 DCN에 이르는 모든 기술적 요소들은 개별적으로도 강력하지만, 이들이 결합되었을 때 비로소 Google TPU v7 시스템의 진정한 경쟁력이 발현됩니다.
7. 결론: 시스템 수준 혁신이 이끄는 AI의 미래
Google TPU v7을 구성하는 핵심 기술 요소들을 심층적으로 분석해봤습니다. 고도로 통합된 Ironwood 랙 아키텍처는 컴퓨팅, 네트워킹, 냉각을 최적화한 기본 빌딩 블록 역할을 하며, 그 위에서 3D 토러스 ICI 네트워크는 수천 개의 TPU를 낮은 지연 시간으로 직접 연결합니다. 그리고 이 모든 것을 유연하게 엮어내는 핵심 기술은 바로 OCS(광 회로 스위치) 를 활용한 재구성 가능한 광 네트워킹과 이를 데이터센터 규모로 확장한 계층적 DCN 아키텍처입니다.
이러한 시스템 수준의 아키텍처는 개별 칩의 성능 경쟁을 넘어 다음과 같은 독보적인 경쟁 우위를 제공합니다.
- 압도적인 확장성 (Massive World Size): 단일 ICI 클러스터 내에서 최대 9,216개, DCN을 통해 14만 개 이상의 TPU를 하나의 거대한 시스템으로 연결하는 능력은 현존하는 가장 큰 AI 모델도 효과적으로 훈련하고 서비스할 수 있는 기반을 제공합니다.
- 동적 재구성과 유연성 (Dynamic Reconfigurability & Flexibility): OCS를 통해 소프트웨어 명령만으로 네트워크 토폴로지를 실시간으로 변경할 수 있습니다. 이는 다양한 병렬 처리 전략(데이터, 텐서, 파이프라인)에 최적화된 슬라이스를 동적으로 생성하고, 하드웨어 장애 발생 시 즉각적으로 경로를 우회하여 시스템 전체의 가용성을 극대화합니다.
- 비용 효율성 (Lower Cost): 메시 네트워크와 OCS의 전략적 조합은 고가의 대형 스위치 수를 최소화하여, 기존 스위치 중심의 스케일업 네트워크 아키텍처 대비 총소유비용(TCO)을 획기적으로 절감합니다. 이는 대규모 AI 인프라 구축에 있어 결정적인 경제적 경쟁 우위를 제공합니다.
- 낮은 지연 시간과 데이터 지역성 (Low Latency & Better Locality): 3D 토러스 구조는 모든 칩이 자신의 논리적 이웃과 직접 연결되도록 보장하여, 다단계 스위치를 거쳐야 하는 네트워크에 비해 통신 지연 시간을 획기적으로 줄이고 데이터 지역성을 향상시킵니다.
결론적으로, Google의 접근 방식은 단순히 더 빠른 칩을 만드는 경쟁에서 벗어나, 데이터센터 전체를 하나의 거대한 컴퓨팅 단위로 설계하고 최적화하는 시스템 수준의 혁신으로 나아가고 있음을 명확히 보여줍니다.
TPU v7의 아키텍처는 AI 시대의 인프라가 마주한 확장성, 유연성, 비용 효율성이라는 핵심 과제에 대한 Google의 명쾌한 해답입니다. 이러한 시스템 수준의 혁신은 앞으로 다가올 초대규모 AI 모델의 개발과 배포를 가속화하는 데 결정적인 역할을 할 것이며, AI 인프라의 미래를 선도할 것입니다.
출처: Google, Semianalysis
뜨리스땅
'반도체, 소.부.장.' 카테고리의 다른 글
| Anthropic은 왜 Nvidia GPU 대신 Google TPU를 선택했는가? (1) | 2025.12.07 |
|---|---|
| Google TPU vs. NVIDIA GPU: AI 인프라 우수성은 Chip이 아니라 시스템 (0) | 2025.12.04 |
| AI 데이터센터 붐이 한국 배터리 산업의 촉매가 되다 (0) | 2025.11.09 |
| Amazon의 AI 반도체 Trainium(트레이니움)은 게임체인저가 될 수 있을까? (0) | 2025.11.04 |
| Google Quantum AI - 검증 가능한 양자 우위 달성 (1) | 2025.10.24 |




댓글