AI 거인의 예상 밖의 선택
오늘날 인공지능(AI) 분야는 새로운 모델을 개발하기 위한 치열한 기술 경쟁의 장이 되었습니다. 이 경쟁의 중심에는 AI 모델을 훈련하고 운영하는 데 필요한 막대한 컴퓨팅 파워가 있으며, 대부분의 기업은 업계 표준으로 자리 잡은 Nvidia의 GPU(그래픽 처리 장치)를 당연하게 선택해왔습니다.
이러한 흐름 속에서, AI 분야의 선두 주자 중 하나인 Anthropic은 모두의 예상을 깨고 Google의 TPU(텐서 처리 장치)라는 다른 길을 선택했습니다. 이것은 단순히 특정 하드웨어를 선호하는 문제를 넘어, 심도 있는 기술적, 경제적 계산에 기반한 중대한 전략적 결정이었습니다. Anthropic은 왜 업계의 거인 Nvidia가 아닌 Google과 손을 잡았을까요?
1. 거인의 어깨: 왜 모두가 Nvidia GPU를 사용하는가?
AI 모델의 훈련 및 추론 분야에서 Nvidia GPU가 사실상의 표준이 된 데에는 명확한 이유가 있습니다. 그 핵심에는 CUDA라는 강력한 소프트웨어 생태계가 있습니다. CUDA는 개발자들이 GPU의 병렬 처리 능력을 쉽게 활용할 수 있도록 돕는 플랫폼으로, 수많은 오픈소스 라이브러리와 광범위한 사용자층을 확보하며 거대한 '해자(moat)'를 구축했습니다. 이 덕분에 개발자들은 Nvidia GPU 위에서 높은 성능을 효율적으로 구현할 수 있었습니다.
Nvidia의 접근법은 '칩' 자체의 성능을 극대화하는 데 초점을 맞춰왔습니다. 물론 GB200과 같은 최신 제품을 통해 완전한 서버와 랙 스케일 설계를 제공하는 '시스템' 회사로 거듭나고 있지만, Google이 2017년 TPU v2 시절부터 칩 간 연결 기술에 집중하며 시스템 엔지니어링에서 상당한 우위를 선점해 온 것과 비교하면 이는 최근의 변화입니다.
이처럼 강력한 Nvidia 생태계에도 불구하고 Anthropic이 다른 선택을 한 데에는 그만한 이유가 있습니다. 이제 그 대안인 Google TPU의 숨겨진 잠재력에 대해 살펴보겠습니다.
2. 보이지 않는 강자: Google TPU의 시스템적 접근
Google의 TPU는 단순히 빠른 칩 하나가 아닙니다. 그것은 처음부터 거대한 '시스템'의 일부로 설계되었습니다. Google은 이미 2017년 TPU v2 시절부터 개별 칩들을 초고속으로 연결하는 네트워킹 기술(ICI, Inter-Chip Interconnect)에 막대한 투자를 해왔습니다. 이러한 '시스템 수준 엔지니어링' 에 대한 오랜 투자는 TPU를 단순한 반도체를 넘어, 수천, 수만 개가 하나의 거대한 컴퓨터처럼 작동하는 유기적인 플랫폼으로 만들었습니다.
이 시스템의 강력함은 구체적인 성과로 입증되었습니다. Google의 최신 모델인 Gemini 3는 처음부터 끝까지 전적으로 TPU 위에서 훈련되었습니다. AI 하드웨어 분야에서 '최전선 모델(frontier model) 사전 훈련'은 가장 어렵고 자원 소모가 큰 과제로 꼽힙니다. TPU 플랫폼은 이 혹독한 시험을 성공적으로 통과하며 그 성능을 증명해 보인 것입니다.
이는 경쟁사와 뚜렷한 대조를 이룹니다. OpenAI의 최고 연구진들조차 GPT-4o 이후 새로운 최전선 모델에 대한 성공적인 전체 규모 사전 훈련을 완료하여 널리 배포하지 못했는데, 이는 Google의 TPU 클러스터가 극복해낸 기술적 장벽이 얼마나 높은지를 잘 보여줍니다.
TPU가 강력한 시스템이라는 점을 이해했다면, 이제 Anthropic이 이 시스템을 선택한 구체적인 이유를 기술적, 경제적 관점에서 깊이 알아볼 차례입니다.

3. 결정적 요인: Anthropic이 TPU에 베팅한 세 가지 이유
3.1. 성능의 진실: 이론적 수치(FLOPs)를 넘어선 실제 성능(MFU)
하드웨어의 성능을 이야기할 때 흔히 '이론적 최고 성능(Theoretical FLOPs)'을 기준으로 삼습니다. 하지만 이는 '자동차의 최고 속도' 와 같습니다. 실제 도로에서는 교통 상황, 도로 상태 등 여러 요인으로 인해 최고 속도를 계속 유지할 수 없는 것처럼, AI 칩 역시 실제 워크로드에서는 이론적 최고 성능에 도달하기 어렵습니다.
Nvidia GPU가 마케팅하는 높은 FLOPs 수치는 실제 워크로드에서 지속하기 어려운 '순간 최고치'에 가깝습니다. 주된 제한 요인은 전력 공급입니다. Nvidia는 동적 전압 및 주파수 스케일링(DVFS) 기술을 사용하는데, 이는 광고된 클럭 속도가 실제 작업에서 안정적으로 유지되는 속도가 아니라 간헐적으로 도달 가능한 최고점임을 의미합니다. 현실에서는 통신 오버헤드, 메모리 병목 현상 등으로 인해 이 수치의 일부만을 활용할 수 있습니다.
TPU의 소프트웨어 스택은 일반적인 소규모 사용자나 최적화에 소극적인 사용자가 '즉시' 사용하기에는 Nvidia보다 다소 복잡할 수 있습니다. 그러나 Anthropic은 이러한 사용자와는 거리가 멉니다. 그들은 전 Google 컴파일러 전문가를 포함한 강력한 엔지니어링 팀을 보유하고 있어, TPU 하드웨어의 잠재력을 극한까지 끌어낼 소프트웨어 최적화 역량을 갖추고 있었습니다.
Anthropic의 진정한 무기는 하드웨어를 다루는 소프트웨어 역량입니다. 이들은 TPU의 '모델 FLOP 활용률(Model FLOP Utilization, MFU)' 을 40%라는 높은 수준까지 끌어올릴 수 있다고 판단했습니다. 즉, TPU라는 자동차 엔진의 잠재력을 경쟁사보다 훨씬 더 잘 활용하여 실제 도로에서 더 빠른 평균 속도를 낼 수 있다는 자신감이 있었습니다.
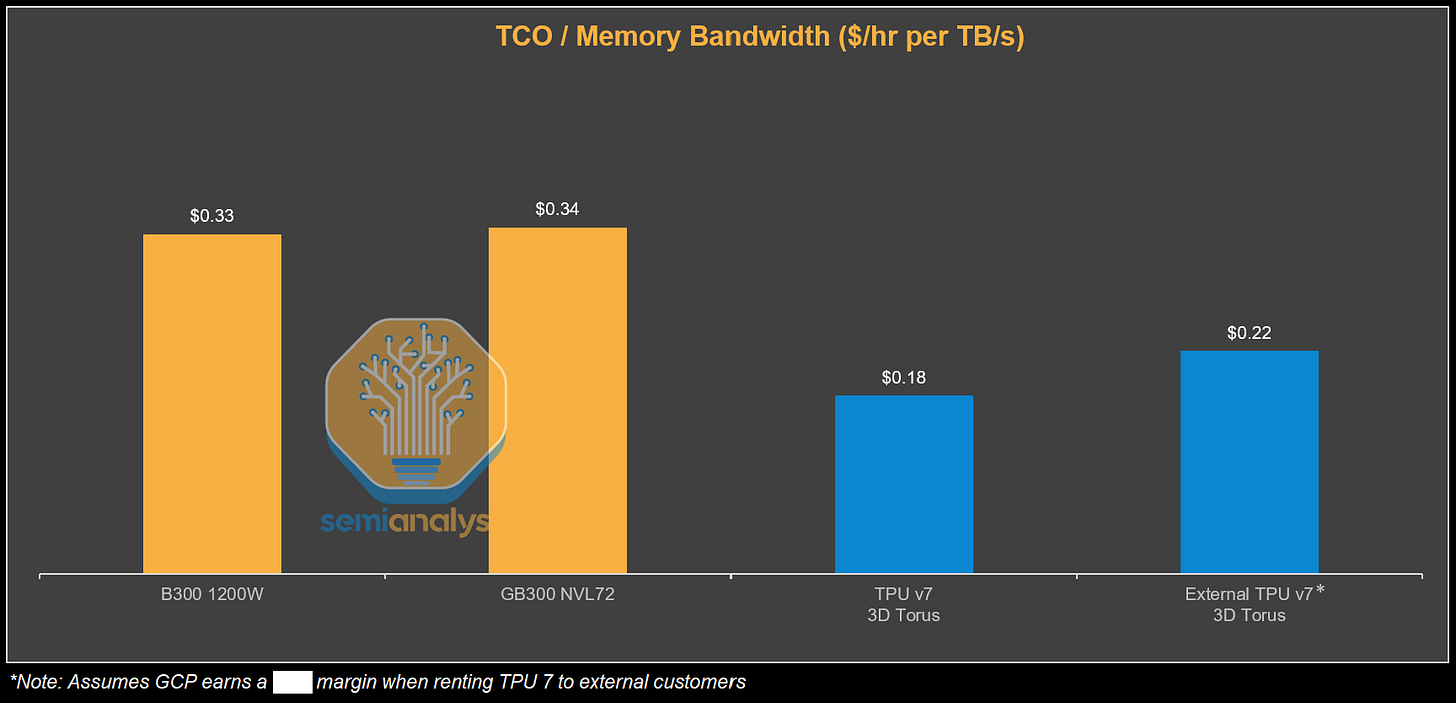
3.2. 경제성의 승리: 총 소유 비용(TCO) 관점에서의 압도적 우위
앞서 설명한 높은 MFU는 곧바로 비용 효율성, 즉 총 소유 비용(Total Cost of Ownership, TCO) 의 우위로 이어집니다. 동일한 '유효 성능'을 더 저렴한 비용으로 얻을 수 있기 때문입니다.
다음 표는 Anthropic의 입장에서 TPU와 Nvidia의 최신 GPU(GB300)의 유효 성능 당 비용을 명확하게 비교합니다.
| 하드웨어 (가정된 MFU) | 유효 PFLOP 당 비용 ($/hr) | GB300 NVL72 대비 TCO |
| Nvidia GB300 NVL72 (30%) | $1.82 | 기준 |
| External TPU v7 (19%) | ~$1.82 | 손익분기점 |
| External TPU v7 (40%) | $0.87 | ~52% 저렴 |
이 표가 의미하는 바는 명확합니다: "Anthropic은 자체 엔지니어링 역량을 통해 TPU의 MFU를 40%까지 끌어올려, Nvidia의 최신 GPU 대비 절반에 가까운 비용으로 동일한 유효 성능을 얻을 수 있습니다."
또한, AI 추론에 중요한 메모리 대역폭 측면에서도 TPU는 비용 효율성이 뛰어납니다. 시간당 TB/s 당 TCO를 비교하면 GB300은 $0.34인 반면, External TPU v7은 $0.22로 더 저렴합니다.

3.3. 시너지 효과: 기술적 선택이 비즈니스 성과로 이어지다
TPU를 통한 비용 효율성은 Anthropic의 비즈니스 경쟁력으로 직접 연결되었습니다.
- 파격적인 가격 인하: Anthropic은 자사의 주력 모델인 Opus 4.5의 API 가격을 약 67% 대폭 인하했습니다. 이는 TPU의 효율적인 컴퓨팅 파워 덕분에 가능했던 결정으로, 시장에서 강력한 가격 경쟁력을 확보하게 했습니다.
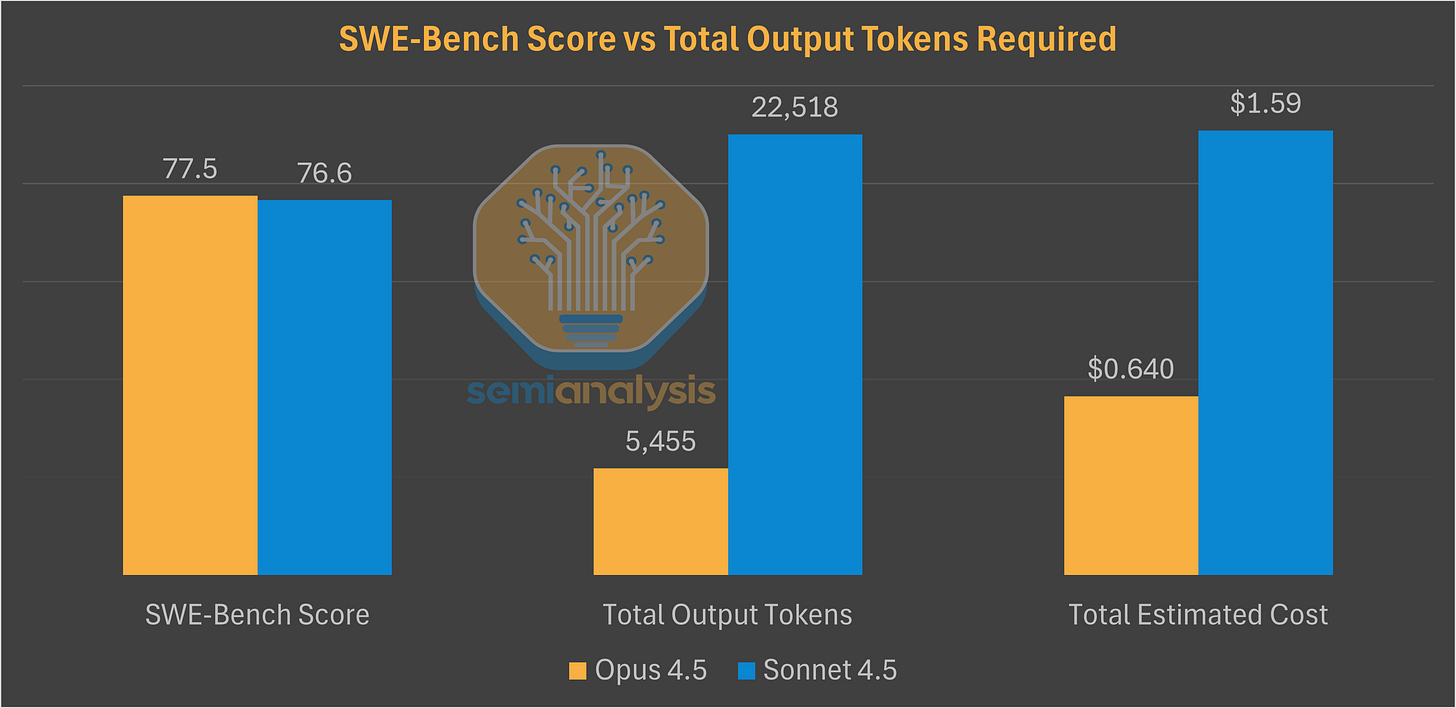
- 높아진 토큰 효율성: 소스 분석에 따르면, Opus 4.5는 Sonnet 4.5와 비슷한 수준의 SWE-Bench 점수를 달성하면서도 필요한 결과물 토큰의 양은 76%나 적었습니다. 이처럼 극적인 토큰 효율성 향상은 사용자가 훨씬 저렴한 비용으로 동일한 품질의 결과를 얻을 수 있음을 의미하며, Anthropic의 인프라 우위가 어떻게 사용자 가치로 직접 전환되는지를 보여주는 대표적인 사례입니다.
이처럼 Anthropic의 선택은 스스로에게 큰 이점을 가져다주었습니다. 그렇다면 이 거래의 다른 당사자인 Google에게는 어떤 의미가 있었을까요?

4. 더 큰 그림: Anthropic, Google, 그리고 AI 생태계의 '윈-윈-윈'
Anthropic과 Google의 파트너십은 어느 한쪽에만 이익이 되는 거래가 아니었습니다. 양측은 물론, AI 생태계 전체에 긍정적인 영향을 미치는 '윈-윈-윈' 구조였습니다.
- Anthropic의 이익 (Win): 앞서 살펴본 것처럼, 압도적인 TCO 절감을 통해 가격 경쟁력을 확보하고 비즈니스 성장을 가속화할 수 있었습니다.
- Google의 이익 (Win): Google Cloud(GCP)는 Anthropic과의 대규모 계약을 통해 다른 GPU 기반 클라우드 계약보다 훨씬 높은 44.0%의 이익률(EBIT Margin)을 기록했습니다. 이는 TPU 스택이 GCP를 단순한 하드웨어 임대 사업자가 아닌, 대체 불가능한 기술을 제공하는 '차별화된 클라우드 제공업체(CSP)' 로 만들어준다는 것을 의미합니다. 반면 자체 ASIC 프로그램에 어려움을 겪는 Microsoft Azure와 같은 경쟁사는 상용 하드웨어를 임대하는 평범한 사업에 머물며 더 낮은 수익을 얻는 데 그칩니다.
- AI 생태계의 이익 (Win): 이 사례는 Nvidia의 독주 체제에 건강한 경쟁 구도를 만들었습니다. AI 기업들에게 GPU 외에도 강력하고 경제적인 대안이 존재함을 보여주었고, 이는 기술 선택의 폭을 넓혀 생태계 전체의 혁신을 촉진하는 계기가 되었습니다.
지금까지 Anthropic의 전략적 선택을 다각도로 분석해보았습니다. 이러한 내용이 우리에게 주는 핵심 교훈들은 무엇일까요?
결론: AI 입문자를 위한 세 가지 핵심적인 시사점
Anthropic의 사례는 AI 분야에 입문하는 학습자들에게 다음과 같은 세 가지 중요한 시사점을 줍니다.
- 시사점 1: 유효 성능(MFU)이 이론적 성능(FLOPs)을 압도한다. 하드웨어의 '스펙 시트' 상의 성능보다 실제 워크로드에서의 '유효 성능(MFU)'이 더 중요합니다. 이는 기업의 소프트웨어 최적화와 엔지니어링 역량이 겉보기에 더 약한 하드웨어에서 더 강력한 실제 성능을 끌어낼 수 있음을 의미합니다.
- 시사점 2: 총 소유 비용(TCO)이 기술 선택의 핵심 척도이다. 최첨단 AI 기술 경쟁의 이면에는 '총 소유 비용(TCO)'이라는 냉정한 경제적 계산이 깔려 있습니다. 기술적 선택은 단순히 최고의 기술을 고르는 것이 아니라, 가장 비용 효율적으로 목표를 달성하는 것이며, 이는 비즈니스 모델과 가격 경쟁력에 직접적인 영향을 미칩니다.
- 시사점 3: 개별 칩을 넘어 '시스템' 단위로 사고하라. 개별 칩(마이크로아키텍처)의 성능을 넘어, 칩, 네트워크, 소프트웨어가 결합된 '시스템 전체의 효율성'을 이해하는 것이 미래 AI 인프라의 핵심 경쟁력이 될 것입니다. Google이 TPU를 통해 보여준 것처럼, 시스템 수준의 접근은 장기적으로 더 강력한 경쟁 우위를 창출할 수 있습니다.
결론적으로, 이 사례는 AI 기업의 성공이 단지 최고의 칩을 구매하는 것에서 그치지 않고, 자신들의 목표와 역량에 맞는 최적의 기술 스택을 '전략적으로 선택'하고 '최대한 활용'하는 능력에 달려있음을 명확히 보여줍니다.
출처: Semianalysis, Google, Anthropic
뜨리스땅
'반도체, 소.부.장.' 카테고리의 다른 글
| LLM 모델은 학습과 추론 시, 반도체에서 어떻게 다르게 동작하는가? (1) | 2026.01.25 |
|---|---|
| NVIDIA가 Groq을 인수한 이유와 의미는 무엇인가? (1) | 2025.12.27 |
| Google TPU vs. NVIDIA GPU: AI 인프라 우수성은 Chip이 아니라 시스템 (0) | 2025.12.04 |
| Google의 TPU v7 성능의 핵심 요소: 시스템 아키텍처와 네트워킹 기술 (5) | 2025.11.29 |
| AI 데이터센터 붐이 한국 배터리 산업의 촉매가 되다 (0) | 2025.11.09 |




댓글