패러다임 시프트와 진폭의 축소
반도체 시장을 움직이는 오랜 격언이 있습니다. "D램은 원자재(Commodity)다."
석유나 철강처럼 경기가 좋으면 가격이 폭락할 때까지 공장을 지어 경쟁하고, 불황이 오면 천문학적인 적자가 쌓여도 버텨야 하는 ‘경기 순환(Cycle) 산업’의 숙명을 표현한 말입니다. 실제로 메모리 반도체 기업들의 영업이익률은 좋을 때 50%를 찍었다가도 다운사이클에는 곧바로 적자로 곤두박질치는 롤러코스터 행보를 보여왔습니다.

그러나 최근 AI 컴퓨팅 인프라 투자 폭증과 함께 글로벌 투자은행(IB)과 반도체 애널리스트들 사이에서 근본적인 의문이 제기되고 있습니다. "과연 우리가 알던 전통적 메모리 사이클의 파괴적인 진폭이 앞으로도 재발할 것인가?"
결론부터 말씀드리면, 현재 메모리 산업은 단순한 단기 호황(Up-cycle)을 누리고 있는 것이 아닙니다. 전방 산업의 주체, 추론 중심의 워크로드 전환, 새로운 AI 디바이스의 부상, 수요의 계약 구조, 제품 포트폴리오의 스펙트럼, 공정 한계, 그리고 누적된 캐파 격차와 장비 리드타임 시차까지 모든 축이 동시에 변하는 ‘구조적 패러다임 시프트(Structural Paradigm Shift)’를 맞이하고 있습니다.
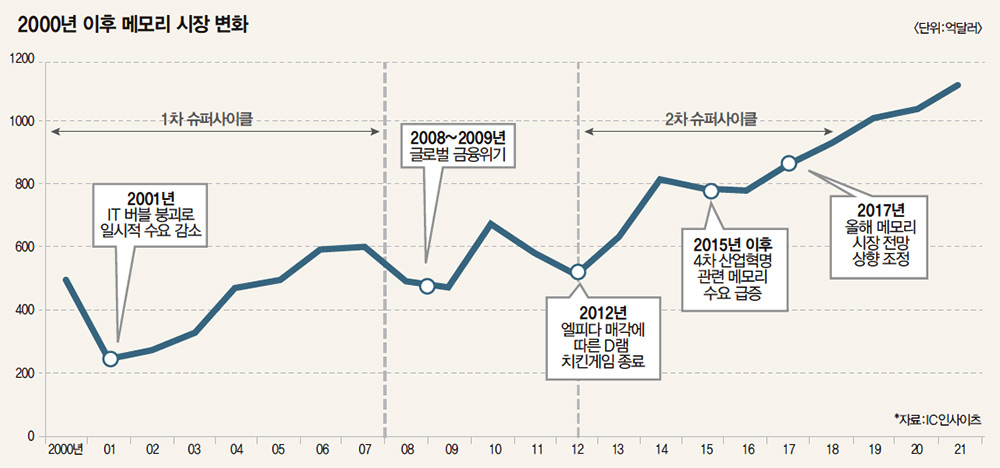
물론 거시 경제 금융 위기나 지정학적 리스크에 따른 변동성이 완전히 사라질(Death of Cycle) 수는 없겠으나, 과거와 같이 산업 전체가 적자 늪에 빠지던 극단적 롤러코스터 사이클은 구조적으로 완화(Cycle Dampening)되고 있습니다. 메모리가 ‘경기에 종속된 원자재’에서 벗어나 비메모리처럼 높은 수준의 이익률이 장기 지속되는 ‘구조적 성장주’로 진화할 수밖에 없는 7가지 요인에 대해 이야기해 보겠습니다.
1. 전방 산업의 변화 - 변덕스러운 B2C에서 계획된 B2B 데이터센터로
과거 메모리 사이클이 그토록 거칠었던 첫 번째 원인은 전방 산업의 주축이 PC, 스마트폰 같은 B2C(개인 소비자) 시장이었기 때문입니다. B2C 수요는 거시 경제의 미세한 변화, 인플레이션, 소비자 심리에 따라 극심하게 요동칩니다. 전 세계 수억 명의 대중이 지갑을 닫으면 완제품 업체들은 순식간에 부품 주문을 취소했고, 이는 고스란히 메모리 시장의 재고 폭발과 가격 폭락으로 이어졌습니다.
그러나 AI 시대의 전방 산업은 NVIDIA를 필두로, Microsoft, Alphabet, Meta, AWS 등 4대 하이퍼스케일러 중심의 굳건한 B2B 시장으로 완전히 재편되었습니다. 이들 4대 빅테크 기업의 연간 총 자본 지출(CapEx) 규모는 과거 스마트폰 전성기 시절 연간 800억 달러 안팎의 무려 3배에 달하는 2,300억 달러(약 310조 원)에 육박하고 있으며, 이 중 약 65%가 서버 랙 및 컴퓨팅 반도체 인프라에 집중됩니다.

이러한 전방 시장의 구조 변동은 전체 D램 시장의 수요 지형도마저 영구적으로 바꾸어 놓았습니다. 글로벌 D램의 전체 비트(Bit) 소비량 내에서 '서버 및 데이터센터' 제품군이 차지하는 비중은 과거 20%대 수준에서 최근 48%를 돌파하며 독보적인 주축으로 올라섰습니다. 반면 과거 시장을 지배하던 모바일은 29%, PC는 11% 수준으로 내려앉았습니다. 빅테크의 데이터센터 투자는 개인의 충동적 소비가 아닌 중장기적 '생존 전략'에 의해 장기적이고 계획적으로 집행되므로, 소수 우량 기업 중심의 수요 구조는 시장 전체의 급격한 수요 급감 리스크를 차단하는 굳건한 방파제가 되어 줍니다.
2. 워크로드의 전환 - '추론(Inference)' 시대의 도래와 KV 캐시가 촉발한 메모리 영토 확장
AI 인프라 시장은 최근 매우 중요한 변곡점(Inflection Point)을 통과했습니다. 전방 시장의 무게중심이 대규모 가속기를 동원한 '학습(Training)'에서, 전 세계 사용자를 대상으로 서비스를 제공하는 '추론(Inference)' 워크로드로 완전히 이동한 것입니다. 실제로 전 세계 데이터센터 내 AI 가속기 연산 처리량 중 추론이 차지하는 비중은 이미 64%를 넘겼으며, 향후 서비스 상용화 가속에 따라 80% 이상으로 치솟을 전망입니다.
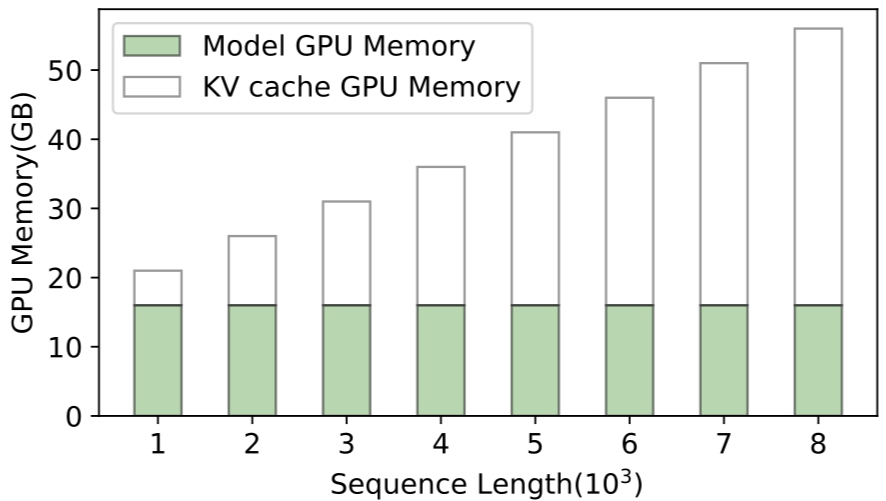
학습 단계에서는 연산(Compute) 능력과 가속기 간의 대역폭이 핵심이었다면, 대규모 실시간 서비스를 구동하는 추론 단계에서는 '메모리 용량'이 성능의 치명적인 병목으로 작용합니다. 거대언어모델(LLM)이 답변을 생성할 때 이전 대화 맥락을 기억해 두는 KV 캐시(Key-Value Cache) 영역이 필수적이기 때문입니다. LLM의 입력 및 출력 문맥(Context Window) 길이가 8K 토큰에서 128K 토큰으로 확장될 때, 시스템 전체에서 KV 캐시가 요구하는 메모리 가용량은 선형적 수준을 넘어 기하급수적으로 증가하여 최대 4~8배까지 폭증하게 됩니다.
700억 파라미터(70B)급 모델을 동시 처리할 때 단일 사용자당 수십 GB의 추가 가용 영역이 강제되므로, 최고가인 HBM만으로 이를 채우기엔 빅테크 기업들의 비용적 한계(TCO)가 너무 큽니다. 이 때문에 엔비디아의 ICMS(Inference Coherent Memory System)나 초고속 이더넷 기반의 메모리 풀링 아키텍처처럼, 프로세서 옆의 초고속 HBM과 외부의 고용량 CXL D램, 그리고 고용량 eSSD까지 하나의 유기적인 계층으로 묶는 '메모리 계층화(Memory Hierarchy Tiering)'가 추론 데이터센터의 아키텍처 표준으로 자리 잡고 있습니다.
이는 서버 랙 전체를 거대한 고용량 메모리 풀로 고도화하여 고용량 D램과 기업용 SSD 시장의 장기적인 성장을 보장하는 핵심 동력이 됩니다.
3. 신규 수요처 - 자율주행과 로봇, 디바이스의 체급이 바뀐 새로운 수요 드라이버
과거 모바일 중심의 수요 촉발이 '수억 대의 대수(Volume)'로 시장을 견인했다면, 새롭게 떠오르는 자율주행 자동차와 로봇(Robotics) 공학은 '한 대당 탑재량(Content per Box)의 극대화'를 통해 메모리 수요의 거대한 하방 지지대를 형성하고 있습니다.
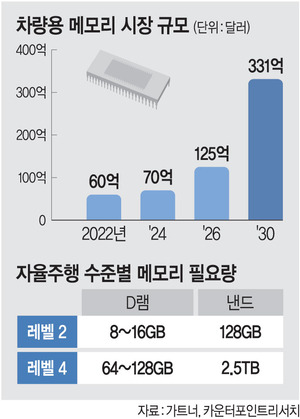
최고 사양 스마트폰의 평균 D램 탑재량이 12GB~16GB 수준에 머무는 반면, 엔비디아 드라이브 토르(Drive Thor)나 테슬라 FSD 칩셋을 탑재하는 레벨 4 이상의 완전 자율주행 차량은 최소 128GB에서 최대 512GB의 전용 고성능 D램과 2TB 이상의 차량용 가혹 조건 특화 NVMe SSD를 기본 요구합니다. 대당 탑재량 기준 모바일의 약 30~40배에 달하는 인프라급 체급입니다.

물리적 환경에서 센서 데이터를 융합해 실시간 동작 추론을 수행해야 하는 휴머노이드 로봇 시장 역시 동일합니다. 로봇 1대당 온디바이스 추론을 위해 소요되는 메모리는 최소 64GB에서 128GB 이상으로 추정됩니다. 스마트폰의 연간 판매량 수치와 단순 비교할 수는 없겠으나, 연평균 38%로 성장하는 로보틱스 시장과 바퀴 달린 데이터센터로 진화하는 모빌리티가 흡수하는 메모리 비트(Bit) 총량은 범용 IT 디바이스의 정체를 완전히 상쇄하고도 남을 만큼 강력한 우상향 하방 지지대로 작동하고 있습니다.
4. 수요 및 계약 구조 - HBM4가 가져온 초(超)커스텀화와 '시장 양극화(Bifurcation)'의 이점
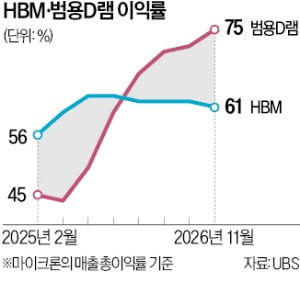
전방 산업과 연산 워크로드의 구조 변화는 메모리를 거래하는 방식의 체질 개선을 불렀습니다. 과거의 D램은 규격화된 제품을 판매하는 형태였으나, 현재 AI 데이터센터의 핵심인 HBM은 기가바이트(GB)당 가격이 약 15~18달러 선으로, 일반 범용 D램(DDR5) 대비 최소 8~10배의 ASP(평균판매단가) 프리미엄을 가집니다. 제품 자체의 영업마진율 역시 60%를 웃돌며 시장의 가치를 극대화하고 있습니다.
특히 이러한 커스터마이징(Customization)의 정점은 HBM4(6세대 HBM) 도입을 기점으로 완성되고 있습니다. HBM3e까지는 메모리 공정으로 만들었던 최하단의 '베이스 다이(Base Die)'가, HBM4부터는 파운드리의 첨단 로직 미세 공정(4~5나노 이하)을 기반으로 제작됩니다. 빅테크 고객사가 자신들의 AI 칩 구동 및 추론 효율화에 최적화된 연산 기능을 이 베이스 다이에 직접 설계해 넣기 때문입니다.
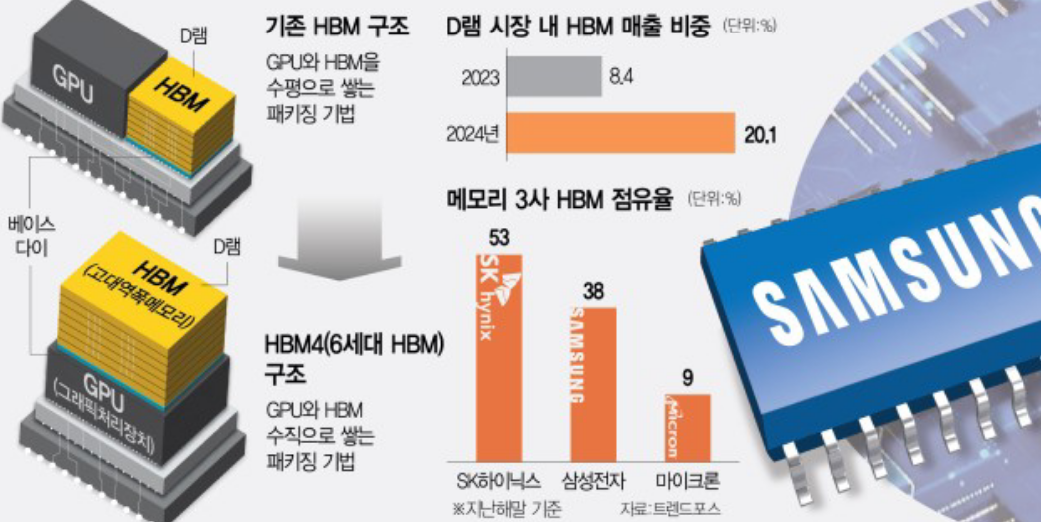
이로 인해 HBM4는 특정 고객사 외에는 그 누구에게도 판매할 수 없는 '완벽한 독점적 맞춤 부품'이 되며, 빅테크-파운드리-메모리사가 단단한 에코시스템으로 묶이게 됩니다. 현재 주요 메모리 3사의 향후 1~2년 치 HBM 캐파(Capacity) 계약률은 이미 100% 완판된 상태입니다.
물론 여기서 한 가지 짚고 넘어가야 할 점은 '시장 양극화(Bifurcation)' 현상입니다. 중국의 추격이 거센 일부 레거시(Low-end) D램 시장은 여전히 전통적인 수급 사이클에 노출될 수 있습니다.

그러나 중요한 것은 전체 메모리 매출의 30~50% 이상, 영업 이익의 절대다수를 이 고부가 맞춤형 하이엔드 세그먼트가 통제하기 시작했다는 점입니다. 확고한 장기 공급 계약(LTA)을 통해서만 가동되는 파운드리형 ‘선(先)수주 후(後)생산’ 모델이 전체 포트폴리오의 실적을 견인하면서, 레거시 제품군의 일시적인 변동성이 오더라도 산업 전체의 이익률이 급락하는 것을 막아주는 '강력한 하방 경직성'을 확보하게 되었습니다.
5. 제품 포트폴리오 - CXL과 LPCAMM2(SOCAMM2의 정확한 이름)가 가져올 '수요 및 교체 주기 분산 효과'
과거 메모리 시장은 단 하나의 규격(DRAM)으로 온 세상의 컴퓨팅 수요를 감당해야 했기에 리스크가 집중되었습니다. 그러나 차세대 고부가 메모리 기술 표준의 본격적인 개화는 포트폴리오를 다변화하여 경기 변동성을 분산시키는 완충 장치 역할을 수행하고 있습니다.

- 서버 교체 사이클을 완화하는 CXL (Compute Express Link): PCIe 인터페이스를 통해 메모리를 유연하게 공유(Pooling)하는 CXL 기술 덕분에, 빅테크 기업들은 대대적인 서버 교체 없이도 메모리 용량만을 계획적으로 확장할 수 있게 되었습니다. Yole Group에 따르면 글로벌 CXL 시장 규모는 연평균 45%의 성장률을 기록하며 162억 달러(약 22조 원) 규모로 대폭 팽창할 전망이며, 이 중 D램 확장 모듈이 78%를 흡수하며 서버 교체 주기에 따른 수요 충격을 완화해 줍니다.

- 엣지 수요를 분산시키는 LPCAMM2: 고성능 저전력 특성을 극대화한 탈착식 모듈 폼팩터인 LPCAMM2는 기존 범용 LPDDR 시장의 단순 단가 경쟁을 가치 중심의 비즈니스로 바꿉니다. 차세대 JEDEC 표준 기반의 LPCAMM2는 레거시 SO-DIMM 대비 부피를 60% 절감하면서도 전력 효율은 70% 향상시켜 향후 AI 노트북 표준 설계의 40% 이상을 잠식할 것으로 예상됩니다.
결과적으로 메모리 산업은 HBM(AI 서버), CXL(메모리 계층화), LPCAMM2(온디바이스 AI)라는 독립적인 3대 고부가 포트폴리오를 갖추게 되었으며, 각각의 전방 시장이 서로 다른 교체 주기와 수요 곡선을 그리기 때문에 수급 밸런스가 한꺼번에 무너질 확률이 현저히 낮아졌습니다.
6. 공정의 제약 - ‘다이 페널티(Die Penalty)’가 초래하는 유효 공급 capa의 축소
전방 수요가 아무리 강력하더라도 공급사들이 과거처럼 설비 경쟁을 벌이며 물량을 쏟아내면 사이클은 재발할 수 있습니다. 하지만 현재 메모리 산업은 생산 라인을 최대로 가동해도 시장에 풀리는 '유효 공급량'이 빠르게 늘지 않는 물리적 한계, 즉 ‘다이 페널티(Die Penalty)’ 국면에 진입했습니다.
동일한 저장 용량(Bit)을 기준으로 할 때, HBM은 일반 범용 D램(DDR5 등)에 비해 약 3배에 달하는 웨이퍼 면적을 소모합니다. 초고속 데이터 통로를 위한 제어 회로 면적이 훨씬 넓은 데다, 칩을 수직으로 쌓아 올리는 적층 구조적 특성 때문입니다. TrendForce의 집계에 따르면 동일 용량 기준 HBM의 웨이퍼 소모량은 범용 제품 대비 2.8배에서 3.1배에 달합니다.
따라서 동일한 미세 공정 웨이퍼를 공장에 대거 투입하더라도 실제 비트(Bit) 기준 생산량은 3분의 1 수준으로 급감하게 됩니다. AI 수요 증가에 맞춰 기존 D램 라인을 HBM으로 전환할수록 범용 D램 시장이 공급 누락으로 빡빡해지는 병목 현상이 발생합니다. 2010년대 공정 미세화 수혜로 매년 35~40%를 기록하던 전 세계 D램 자연 공급 증가율(Bit Growth)이 최근 14~16% 수준으로 반 토막이 난 기술적 배경이 바로 여기에 있습니다.
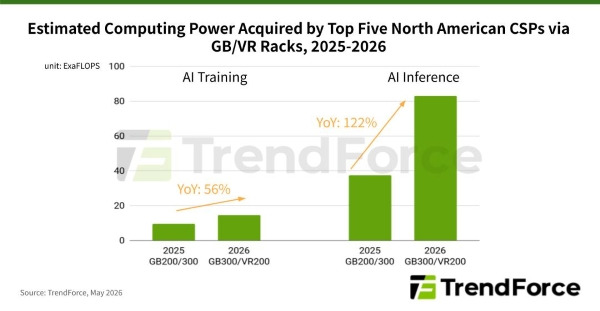
7. 수급 격차의 계량화 - 투자 급증과 생산 지연의 모순이 만든 '장기 수급 갭(Gap)' 전망
수요의 양적 팽창과 공급의 물리적 제약이 맞물리면서, 향후 메모리 반도체 시장의 수급 격차(Gap)는 전례 없는 장기화 국면으로 진입하고 있습니다. 최근 글로벌 메모리 산업의 전체 자본 지출(CapEx) 규모는 사상 최고치인 무려 1,440억 달러(약 195조 원) 수준까지 급등했습니다. 하지만 여기서 매우 심각한 ‘구조적 모순’이 발생합니다. 공급사들이 수십조 원의 돈을 쏟아부으며 공장 라인을 증설하고 있음에도 불구하고, 실제 시장에 유통되는 유효 공급 증가율은 여전히 13%~15% 수준에 묶여 있기 때문입니다.
막대한 투자 자금의 대부분이 웨이퍼 생산량(캐파) 자체를 늘리는 데 쓰이는 것이 아니라, HBM4 미세 공정 전환, 하이브리드 본딩 설비 구축, 1c나노 노드 전환 등 기술 난이도 극복을 위한 고가 장비 도입에 소모되기 때문입니다. 실제로 AI 인프라 고도화로 유발되는 글로벌 D램 수요 비트 그로스는 매년 평균 21%~23% 수준으로 계산되는 반면, 공급 비트 증가율은 이에 못 미쳐 매년 약 6%~8%에 달하는 공급 부족 갭(Structural Supply Shortage)이 고스란히 누적됩니다.
새로운 반도체 공장 건물을 짓고 핵심 전공정 장비를 인도받아 수율을 안정화하는 데는 최소 2~3년의 물리적 리드타임(Lead-time) 시차가 강제됩니다. 돈을 쏟아부어도 공급 과잉을 당장 만들 수 없는 시차 장벽으로 인해, 가트너(Gartner) 등은 고용량 eSSD 제품군의 가격이 누적 234%, AI 특화 서버 D램 모듈은 연평균 125% 수준의 초강세를 유지하는 강력한 '메모리 인플레이션(Memflation)' 국면이 지속될 것으로 전망합니다. 공급 병목이 완화되고 유의미한 수급 반전이 일어나는 시점은 아무리 빨라도 2028년 이후가 될 것이라는 관측이 지배적입니다.
맺음말: ‘High-Margin Plateau’ 고수익 안착, 메모리의 재정의
AI 컴퓨팅 인프라 확대로 촉발된 이번 변화는 단순한 호황과 불황을 반복하던 천수답식 경기 순환 구조의 마감을 시사합니다. 물론 글로벌 거시 매크로의 급변이나 예상치 못한 다운사이클의 가능성을 100% 소멸시킬 수는 없겠으나, 공급과 수요의 질적 동학이 바뀌면서 과거처럼 무차별적인 폭락과 적자로 이어지던 진폭은 기하급수적으로 축소(Cycle Dampening)되었습니다.
B2B 데이터센터 중심의 전방 산업, 추론 워크로드 중심의 수요 점프, 자율주행과 로보틱스라는 고체급 엣지 디바이스의 확산, HBM4 커스텀 베이스 다이가 이끄는 완전한 파운드리형 시스템 부품화, CXL과 LPCAMM2가 이끄는 수요 분산, 다이 페널티로 인한 공급 효율 저하, 그리고 Capa 증설과 공급 시차의 모순이 만든 장기적 수급 갭(Gap)까지. 이 7대 요인은 범용재 시장의 노이즈를 완벽히 상쇄하며 메모리 기업들의 수익 구조를 완전히 바꾸어 놓았습니다.
최근 선도 메모리 업체들이 달성한 40%를 상회하는 순이익률은 더 이상 일시적인 신기루가 아닙니다. 이는 과거 세계 최고 수준의 파운드리인 TSMC나 글로벌 선두 팹리스 기업들이 누리던 ‘지속 가능한 고수익 궤도(High-Margin Plateau)’에 메모리 산업 역시 당당히 진입했음을 뜻합니다. 이제 메모리 반도체는 경기에 따라 롤러코스터를 타는 변동성 자산이 아닙니다. AI 인프라 시대를 지탱하는 필수 불가결한 고부가 ‘구조재’이자, 독점적 고수익을 장기 창출하는 ‘구조적 성장 산업’으로 리레이팅(Re-rating, 재평가)되어야 할 때입니다.
뜨리스땅
출처: 트렌드포스, 가트너 등
'반도체, 소.부.장.' 카테고리의 다른 글
| AMD의 새로운 CPU에 담긴 기술적 혁신 (feat. by Dual 3D V-cache) (0) | 2026.04.30 |
|---|---|
| HBF: AI 메모리 캐즘(Chasm)을 건너는 다리 (1) | 2026.04.25 |
| TurboQuant 알고리즘 혁신에 따른 AI 반도체 산업의 영향 (0) | 2026.03.28 |
| AI 성능의 병목을 뚫는 열쇠: SRAM (2) | 2026.03.27 |
| AI 반도체 대기근: 왜 글로벌 빅테크는 돈을 싸 들고도 칩을 구하지 못할까? (0) | 2026.03.15 |




댓글