LLM에서 학습(training)과 추론(inference)은 겉으로 보기엔 둘 다 “토큰을 넣고 토큰을 내보내는” 과정이지만, 내부적으로는 수행하는 연산과 데이터 흐름이 꽤 다릅니다.
0. 개념적 차이
- 학습: 모델의 가중치 자체를 바꾸는 과정입니다. 대량의 텍스트를 넣고, 정답(다음 토큰)을 맞추도록 오차를 줄이면서 파라미터를 업데이트합니다.
- 추론: 이미 학습이 끝난 모델을 사용해 가중치는 고정한 채 입력 프롬프트에 대한 출력을 생성하는 과정입니다.
같은 네트워크 구조(Transformer)를 쓰지만, 학습은 “모델을 만드는 과정”, 추론은 “만들어진 모델을 실행하는 과정”이라고 보면 됩니다

1. 공통 부분: 순전파(forward pass)
두 과정 모두 공통적으로 하는 일은 다음과 같습니다.
- 토크나이저가 텍스트를 정수 시퀀스로 변환.
- 임베딩 레이어에서 각 토큰을 고차원 벡터로 매핑.
- 여러 층의 self-attention과 MLP를 거치며, 행렬 곱과 비선형 함수를 반복 수행.
- 마지막에 vocabulary 크기의 로짓(logit)을 만들고 softmax로 “다음 토큰 확률 분포”를 계산.
즉, 거대한 행렬 곱과 벡터 연산이라는 점에서는 학습과 추론 모두 동일한 순전파 연산을 사용합니다.

2. 핵심 차이
2.1: 역전파와 가중치 업데이트 유무
- 학습 시:
- 순전파 후, 예측 분포와 정답 토큰 사이의 손실(loss)을 계산 (예: cross entropy).
- 손실에 대해 각 가중치의 기울기(gradient)를 구하기 위해 **역전파(backpropagation)**를 수행합니다.
- SGD, AdamW 등의 옵티마이저로 가중치를 갱신합니다. 이때 거대한 파라미터 텐서들에 대해 대규모 쓰기 연산이 발생합니다.
- 추론 시:
- 순전파만 수행하고, 그 결과 확률 분포에서 샘플링/argmax로 다음 토큰을 선택합니다.
- 손실 계산, 역전파, 가중치 업데이트가 전혀 없습니다. 가중치 텐서는 read-only로 사용됩니다.
연산 관점에서 보면, 학습은 “forward + backward + optimizer step” 전체 파이프라인이고, 추론은 “forward만 반복”입니다.
2.2: 토큰 처리 방식과 캐시
- 학습:
- 보통 긴 시퀀스를 한 번에 또는 큰 배치로 넣어 병렬 처리합니다 (예: 2K~8K 토큰).
- 미래 토큰까지 포함한 전체 시퀀스에 대해 teacher forcing을 사용하므로, 같은 시퀀스를 한 번의 패스로 처리하며, attention도 “현재 토큰이 이전 토큰을 보는” 제약만 두고 전체를 계산합니다.
- 추론:
- 유저 프롬프트 + 지금까지 생성된 토큰 시퀀스를 바탕으로, 한 토큰씩(혹은 소량씩) 생성합니다.
- 매 토큰마다 전체 층을 다시 통과하면 너무 비싸므로, past key/value 캐시를 사용해 증분(incremental) attention을 수행합니다.
- 즉, 추론은 time-step마다 “현재 토큰에 대한 부분 연산”을 하고, 이전 토큰들의 중간 결과를 캐시에서 재활용합니다.
그래서 학습은 “시퀀스 방향으로 크게 병렬화”, 추론은 “시간 방향으로 점진적이며 캐시를 많이 쓰는 패턴”이 됩니다.

2.3: 연산량/메모리 구조
- 학습:
- forward + backward 때문에 FLOPs가 대략 추론의 2~3배 이상 요구됩니다(역전파가 모든 층 연산을 다시 되짚기 때문).
- 각 레이어의 중간 활성값을 backward용으로 저장해야 하므로, activation 메모리도 매우 큽니다. 그래서 데이터/텐서/파이프라인 병렬화, 체크포인팅 등 메모리 최적화가 중요합니다.
- 추론:
- forward만 하므로 FLOPs는 적지만,
- 긴 context와 캐시 때문에 KV 캐시 메모리가 주요 병목입니다.
- 지연(latency)와 처리량(throughput)을 위해 배치/토큰 병렬화를 조정하고, 양자화나 low-rank adaptation 등으로 메모리 대역폭을 줄이는 것이 핵심입니다.
요약하면, 학습은 “파라미터 갱신 중심의 compute-heavy + activation-heavy”, 추론은 “파라미터는 고정, KV 캐시 및 I/O 중심의 latency-sensitive” 워크로드입니다.

2.4. 알고리즘 관점: 목적 함수 vs 정책 실행
- 학습:
- 목적: 다음 토큰 예측 정확도를 높이거나, RLHF/추론 모델의 경우 보상 모델이 정의한 **정책(policy)**을 최적화하는 것입니다.
- 지도학습(SFT), RL 기반 최적화(PPO류), 추가적인 추론 강화 학습 등에서 손실/보상에 따라 파라미터를 조정합니다.
- 추론:
- 학습된 파라미터에 따라 이미 고정된 정책을 실행하는 단계입니다.
- “다음 토큰 분포 → 샘플링/beam search → 응답 생성”을 반복하며, 추가적인 학습 목적은 없습니다.
예를 들어 reasoning LLM에서는, 학습 단계에서 CoT를 잘 생성하도록 보상 기반으로 튜닝하고, 추론 단계에서는 그 정책을 그대로 실행해 “먼저 생각한 뒤 답하는” 출력 시퀀스를 만듭니다.
따라서, 같은 Transformer 구조와 행렬 곱을 쓰더라도,
- 학습은 손실 기반의 역전파·가중치 갱신을 포함한 최적화 문제,
- 추론은 고정된 가중치로 순전파와 샘플링만 수행하는 정책 실행 문제,
로 보면 되고, 연산 패턴·메모리 사용·시스템 설계 포인트가 크게 달라집니다
2.5. 자원 관점: 한 번 쏟아붓는 학습, 끝없이 나가는 추론
LLM 비용 구조를 단순화하면 이렇게 볼 수 있습니다.
- 학습(Training)
- 특성: 몇 주~몇 달 동안 집중적으로 GPU를 태우는 one-off 또는 소수 회 이벤트.
- 예: 수천 개의 H100/H800급 GPU를 수십 일간 사용.
- 비용 구성: GPU 시간 단가(온프레/클라우드), 전기료, 데이터 파이프라인, 인프라 엔지니어 인건비 등.
- 추론(Inference)
- 특성: 서비스가 살아 있는 동안 계속 발생하는 반복 비용
- 사용자 수, 요청량, 컨텍스트 길이, 응답 길이에 따라 매일 GPU 시간이 쌓입니다.
- 대규모 서비스 기준으로는 “장기적으로 학습비용보다 추론비용이 더 크다”는 분석이 지배적입니다 (총 비용의 80~90%가 inference라는 추정도 있음).
정리하면, 학습은 CapEx/대규모 프로젝트 느낌, 추론은 Opex/지속적인 운영비에 가깝습니다.

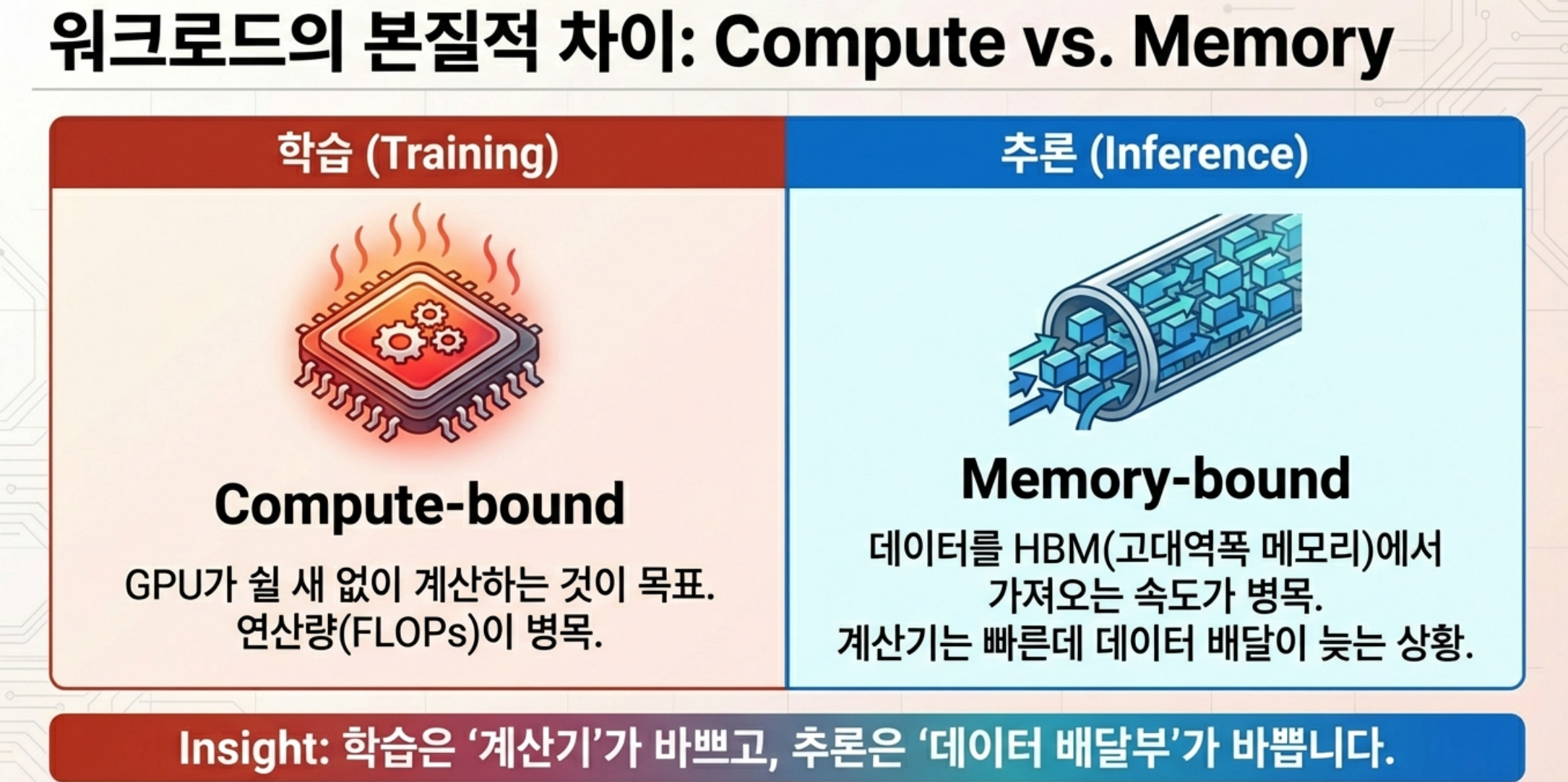
2.6. 워크로드 측면: 학습은 FLOPs에 모든 걸 맞추는 세계, 추론은 메모리·지연·규모의 게임
학습은 대형 LLM 학습은 “어떻게든 GPU를 100% 가까이 태우는 것”이 목표이기 때문에 전형적인 compute-bound 워크로드인 반면, 추론은 반면 추론은 같은 Transformer라도 워크로드 특성이 다르며, memory/latency-bound에 가깝습니다.
- 학습(Training)
- 동일한 모델을 수십~수백 epoch가 아니라, 거한 토큰 수에 대해 한 바퀴 도는 구조 (scaling laws 상의 token budget)
- Forward + Backward + Optimizer까지 모두 포함한 막대한 FLOPs를 처리
- 배치 사이즈를 키우고, 여러 샘플/토큰을 병렬 처리해서 메모리 대역폭보다 연산량이 병목이 되도록 설계
- 학습 인프라 설계에서는 고성능 GPU (FP8/FP16 Tensor Core 성능, H100/H200, B100 등), 빠른 GPU 간 통신 (NVLink, InfiniBand)로 데이터/텐서/파이프라인 병렬화 구현, 대형 배치로 연산 효율 최적화가 핵심임
- 추론(Inference)
- Forward만 수행하므로, 이론상 FLOPs 요구량은 학습에서 요구량의 부분적인 크기에 불과함
- 그러나, 긴 컨텍스트와 KV 캐시 때문에 GPU HBM 메모리가 주 병목이며, 각 요청이 짧은 시퀀스로 들어와 GPU가 idle 되는 시간이 생기기 쉬움. 또한, 사용자-facing 서비스이기 때문에 지연(latency) 제약이 강함
2.6. 비용을 좌우하는 요소: KV 캐시가 비용 구조를 바꾼다
- 학습(Training)
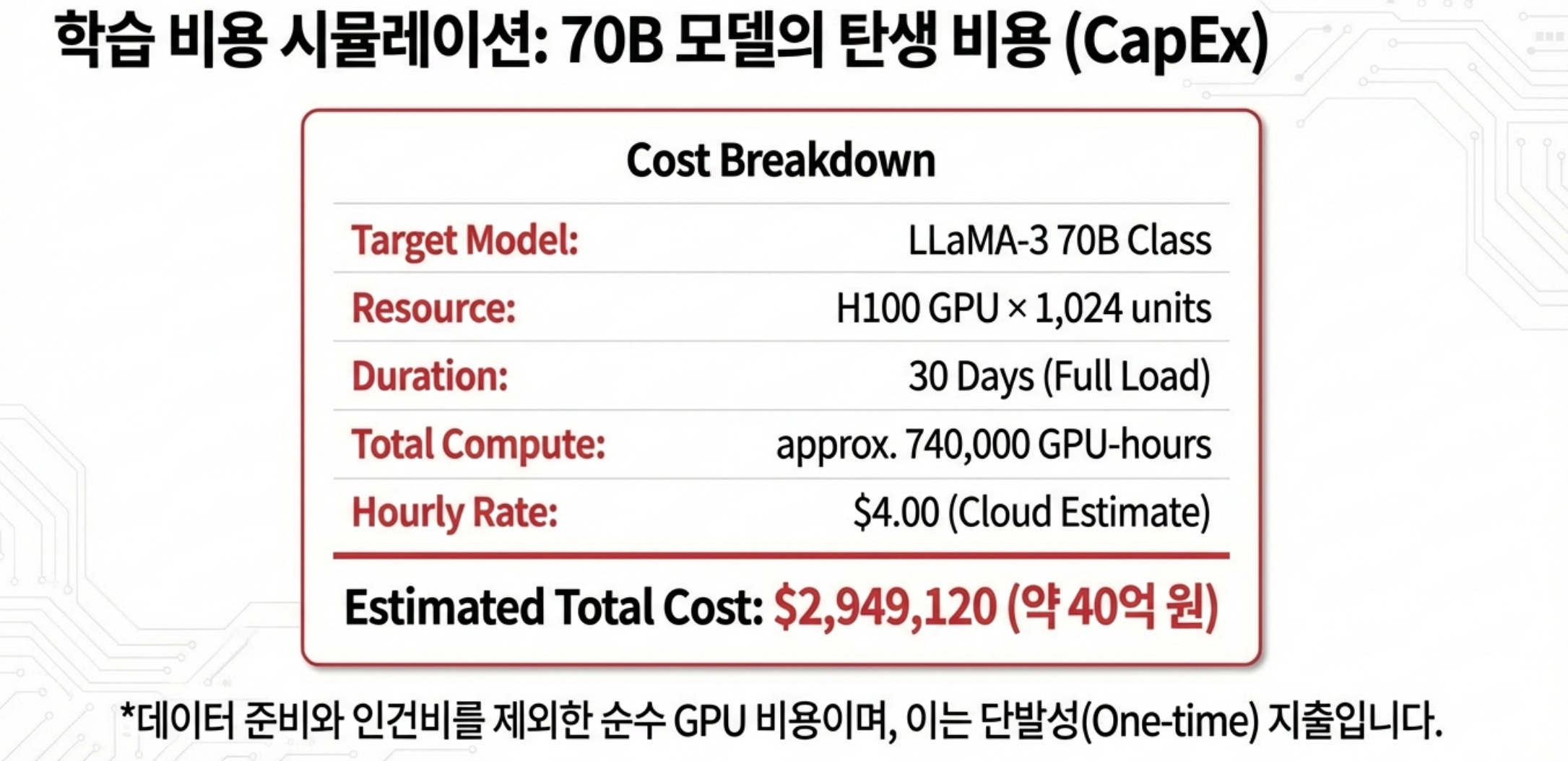
- 학습의 총 비용은 대략 다음의 곱으로 이해할 수 있습니다: 필요한 총 FLOPs (모델 파라미터 수 × 학습 토큰 수 × 상수 계수) X 누릴 수 있는 하드웨어 효율 (GPU 종류, mixed precision, 커널 최적화) X GPU 1시간당 비용 (클라우드 vs 코로케이션 vs 자체 구축) X 실패/재시도 회수 혹은 실험 반복 횟수(= 보고되는 수치보다 실제 비용이 훨씬 커지는 원인)
- 예를 들어 GPT-4나 LLaMA 3.1 70B 같은 모델은 수천 개 GPU를 수주간 돌려 수천만~수억 달러 수준의 compute를 사용한 것으로 추정됩니다
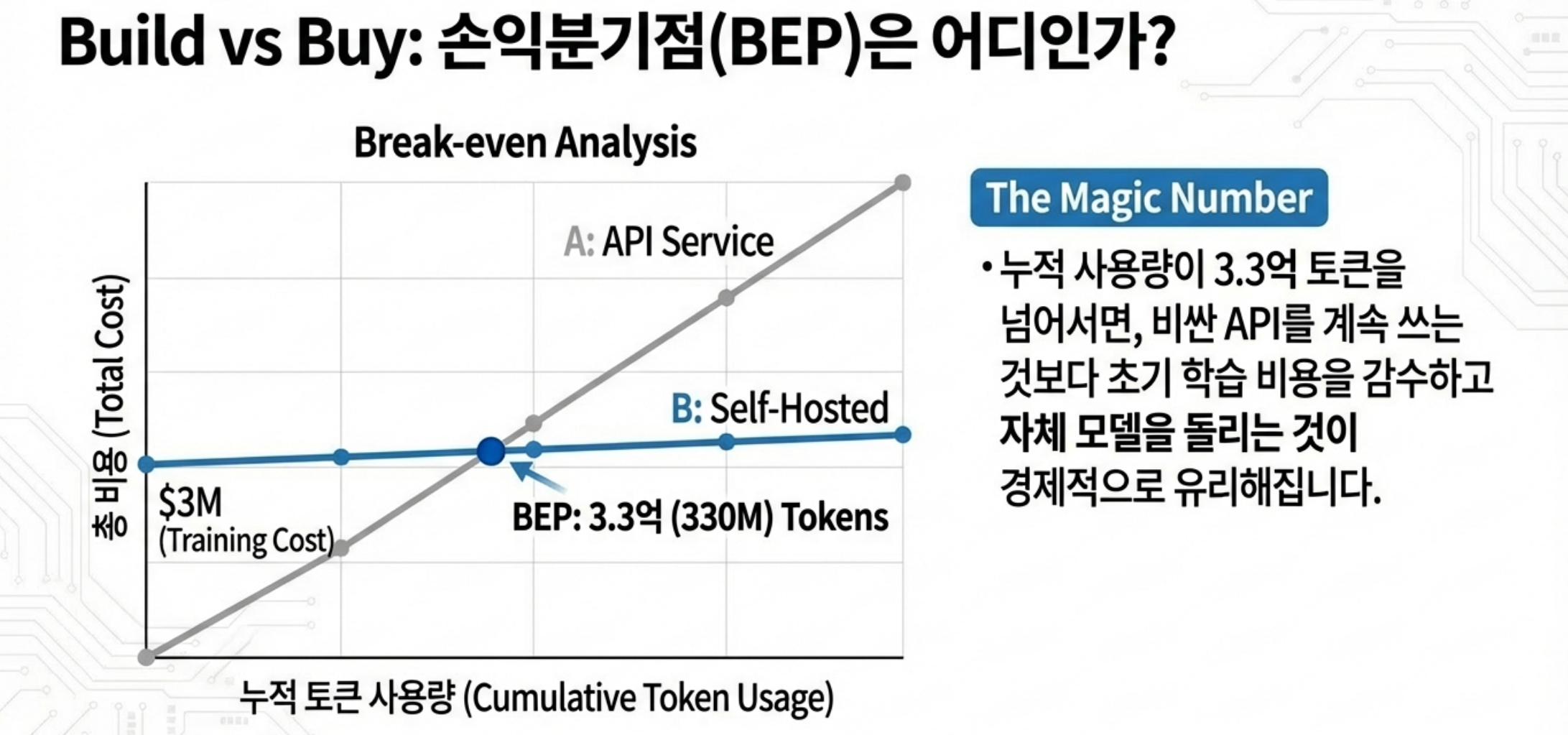
- 하지만 중요한 포인트는 이 비용은 “한 번(또는 소수 번)” 발생하는 이벤트라는 점이며, 모델이 성공적으로 서비스에 안착하면, 이 학습 비용은 트래픽에 나눠져 amortize된다는 점입니다.
- 추론(Inference)
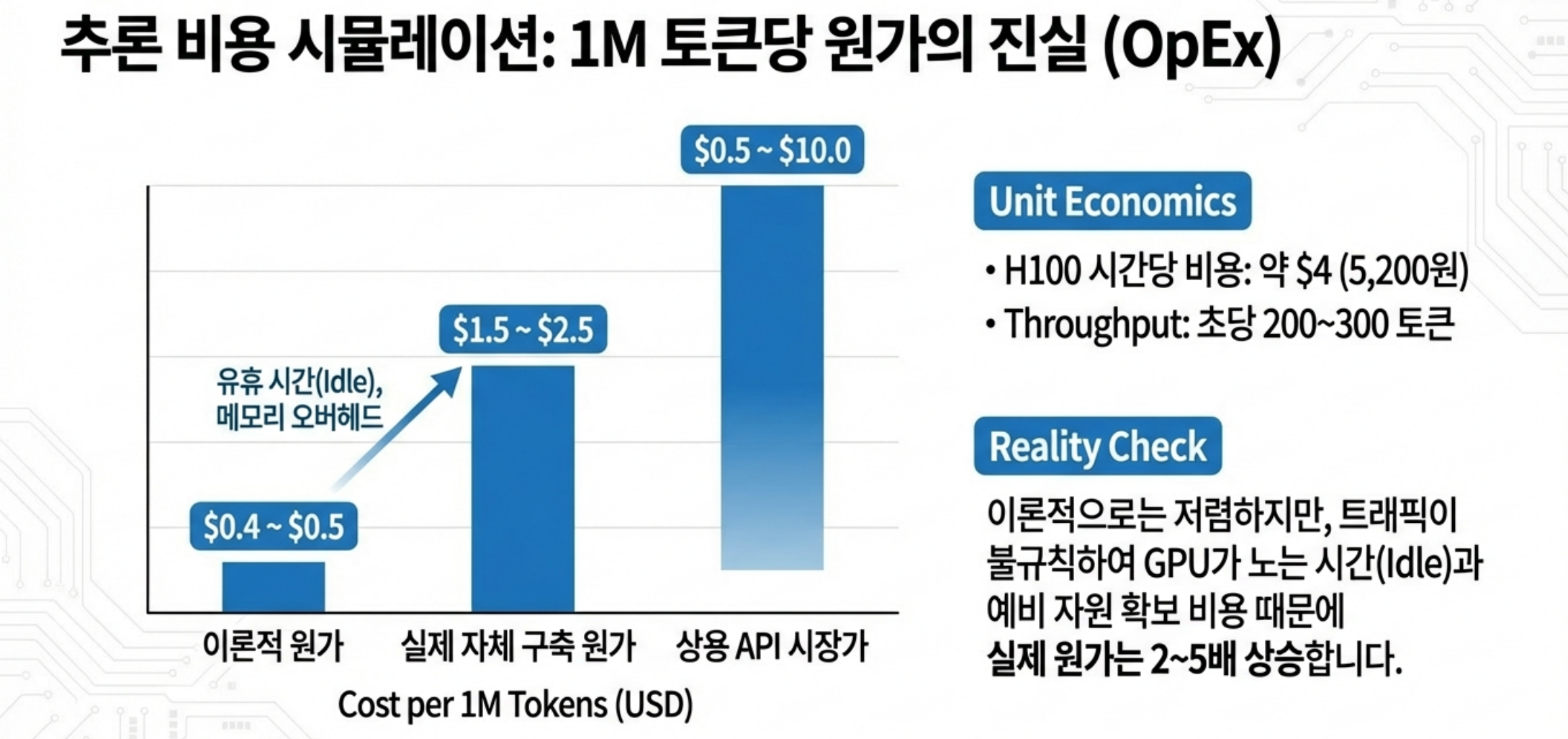
- 추론 시 self-attention을 최적화하기 위해 KV 캐시를 사용합니다.
- 각 토큰의 key/value를 GPU 메모리에 쌓아 두고, 이후 토큰은 이 캐시를 참조합니다. 시퀀스 길이에 비례해서 메모리가 늘어나는 구조라, 긴 컨텍스트/많은 동시 세션을 지원하려면 KV 캐시 메모리의 총량이 곧 capacity를 결정합니다. 이 때문에 단일 GPU에 너무 많은 세션을 올리면 KV 캐시에 메모리가 잠식된다. OOM 혹은 severe swapping이 됨. 세션 수를 줄이면 GPU는 한가해지지만, 동시 처리량이 떨어져서 비용/요청이 올라간다.
- 이를 해결하려는 접근은 KV 캐시 오프로딩/티어링이다. 자주 쓰는 캐시는 GPU HBM에, 덜 쓰는 캐시는 CPU RAM/로컬 SSD/리모트 스토리지에 두고 필요 시 불러오는 구조를 채택한다. Google GKE의 tiered KV cache, LMCache, Crusoe MemoryAlloy 같은 솔루션이 이 방향이라고 볼 수 있다.
- 혹은 KV 캐시 효율 중심의 새로운 아키텍처/커널 (PagedAttention 등)을 설계하기도 합니다.
- 즉, 추론 인프라 설계는 “KV 캐시를 어디에, 어떻게 저장·이동시키느냐”가 핵심 기술 포인트입니다.
3. 왜 “추론 비용 > 학습 비용”이 되는가
실제 비즈니스 관점에서, 많은 LLM 서비스는 학습보다 추론에 더 많은 돈을 씁니다.

3.1. 사용량이 모든 것을 압도한다
- 학습: 한 번에 수백만~수억 GPU-초를 쓰고 종료
- 추론:
- 예를 들어 일일 수천만~수억 토큰을 생성하는 서비스라면,
- 몇 달~몇 년 누적 시 추론에 쓰인 총 GPU 시간이 학습 때 투입한 GPU 시간을 추월하는 경우가 흔합니다.
실제 분석 글에서는, 대규모로 사용되는 모델은 “동일 규모의 GPU 시간을 사용하려면 수십 일~수개월 분량의 서비스 트래픽이면 충분하다”는 사례도 제시합니다. 그리고 그 이후부터는 추론 비용이 계속 누적됩니다.
3.2. 서비스 품질 요구사항이 비용을 끌어올린다
- 낮은 latency: 토큰당 수십 ms, 전체 응답 수 초 이내를 요구하는 경우가 많음
- 높은 가용성: 피크 트래픽 대응을 위해 여유 capacity 확보 필요
- 긴 컨텍스트: 사용자들은 점점 더 긴 문서/대화 맥락을 원함 → KV 캐시 메모리 증가
- 고품질 모델: 파라미터 수가 많고 깊은 모델일수록 토큰당 GPU 시간이 증가
이 요구사항이 겹치면서, “학습 때는 compute 효율에 맞춰 모델을 설계했는데, 추론 때는 메모리·latency 제약으로 효율이 10% 수준까지 떨어진다”는 분석도 있습니다.
4. 인프라 설계 전략: 학습용 vs 추론용
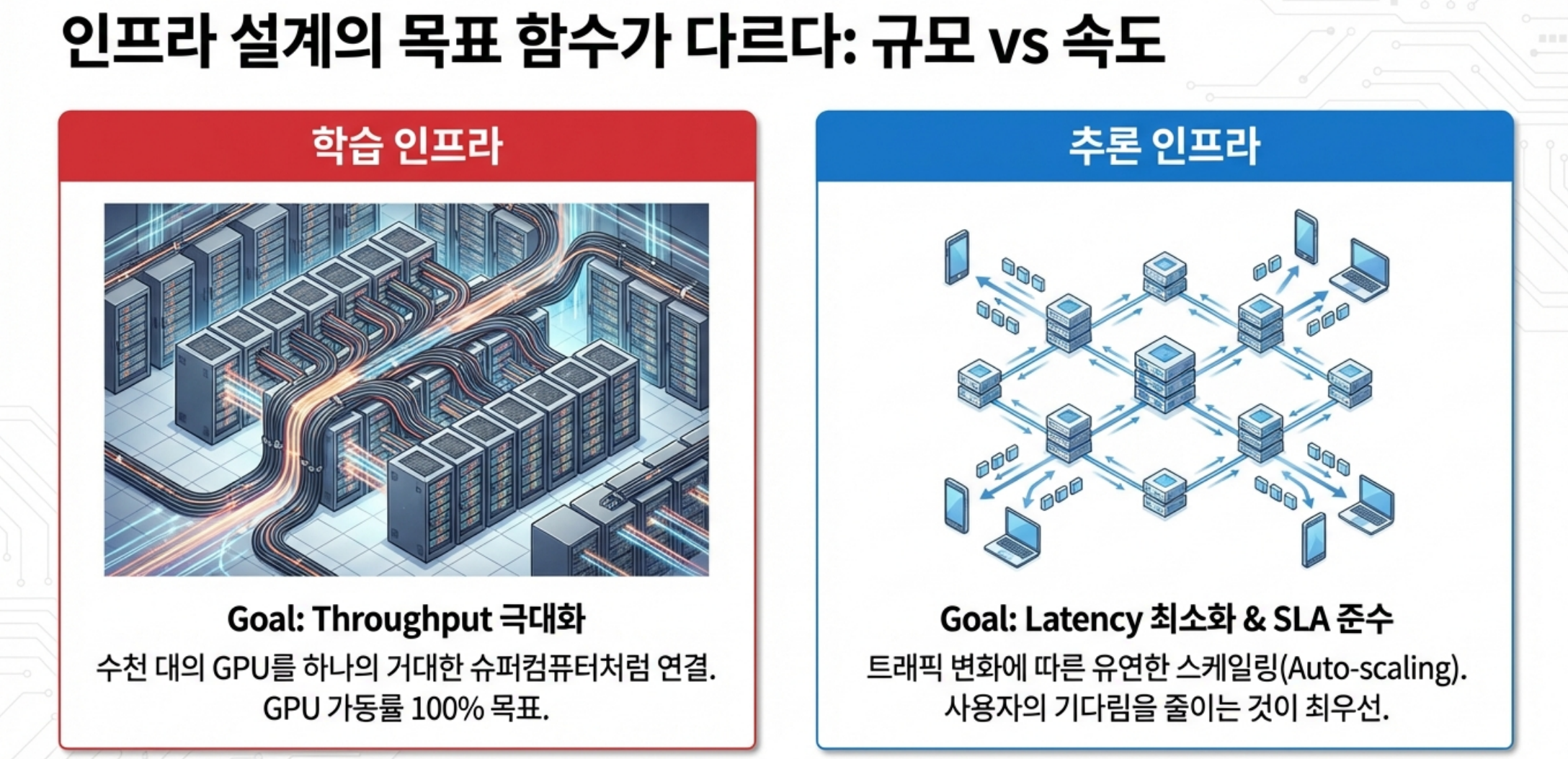
4.1. 학습 인프라: “한 덩어리를 빨리 끝내라”
학습 인프라 전략의 핵심은 총 학습 시간 단축과 안정성입니다.
- GPU 선택: 높은 FLOPs/W, 대규모 NVLink/InfiniBand가 붙은 고급 GPU 클러스터
- 네트워크: GPU 간 통신 지연을 최소화해 data/model parallel 효율 극대화
- 스케줄링: 장시간 대형 job이 중단 없이 돌 수 있는 예약/복구/체크포인트 전략
- 소프트웨어:mixed precision, fused kernel, ZeRO, pipeline parallel 등으로 메모리/연산 최적화
여기서 중요한 건 “한 번의 큰 job을 얼마나 효율 좋게 끝낼 수 있는가”이기 때문에, 평균 GPU 활용률을 아주 높게 끌어올리는 것이 목표입니다.
4.2. 추론 인프라: “QoS를 유지하며 GPU당 매출 극대화”
추론 인프라는 완전히 다른 목표 함수를 가집니다.
- 목표:
- SLA(지연·가용성)를 지키면서, GPU 1장당 처리하는 요청/토큰 수를 최대화.
- 고려 요소:
- 동시 접속자 수, 요청 패턴(피크/비피크), 요청당 토큰 수 분포
- 모델 크기, 컨텍스트 길이 제한, 샘플링 전략
- KV 캐시 정책 (offload, eviction, sharing)
이에 따라 등장하는 설계 패턴은 아래와 같습니다:
- Continuous batching: 여러 요청의 토큰들을 한 번의 large batch로 합쳐서 처리, GPU idle 시간을 줄임
- Paged/KV cache offloading: GPU HBM은 hot cache에 집중, 나머지는 CPU/SSD로 tiering
- 모델 다단계 구성:
- 작은 SLM/라우터 모델로 쉬운 요청을 처리하고, 어려운 요청만 대형 LLM으로 라우팅해 평균 비용 절감
- 양자화/압축:
- int8/int4, sparsity, MoE 등으로 파라미터·KV 캐시 크기를 줄여 HBM 요구량과 대역폭 소모 감소
이쪽은 “GPU를 꽉 채워 태우는 것”보다, “서비스 품질을 깨지 않으면서 GPU를 최대한 험하게 굴리는 것”이 핵심입니다.
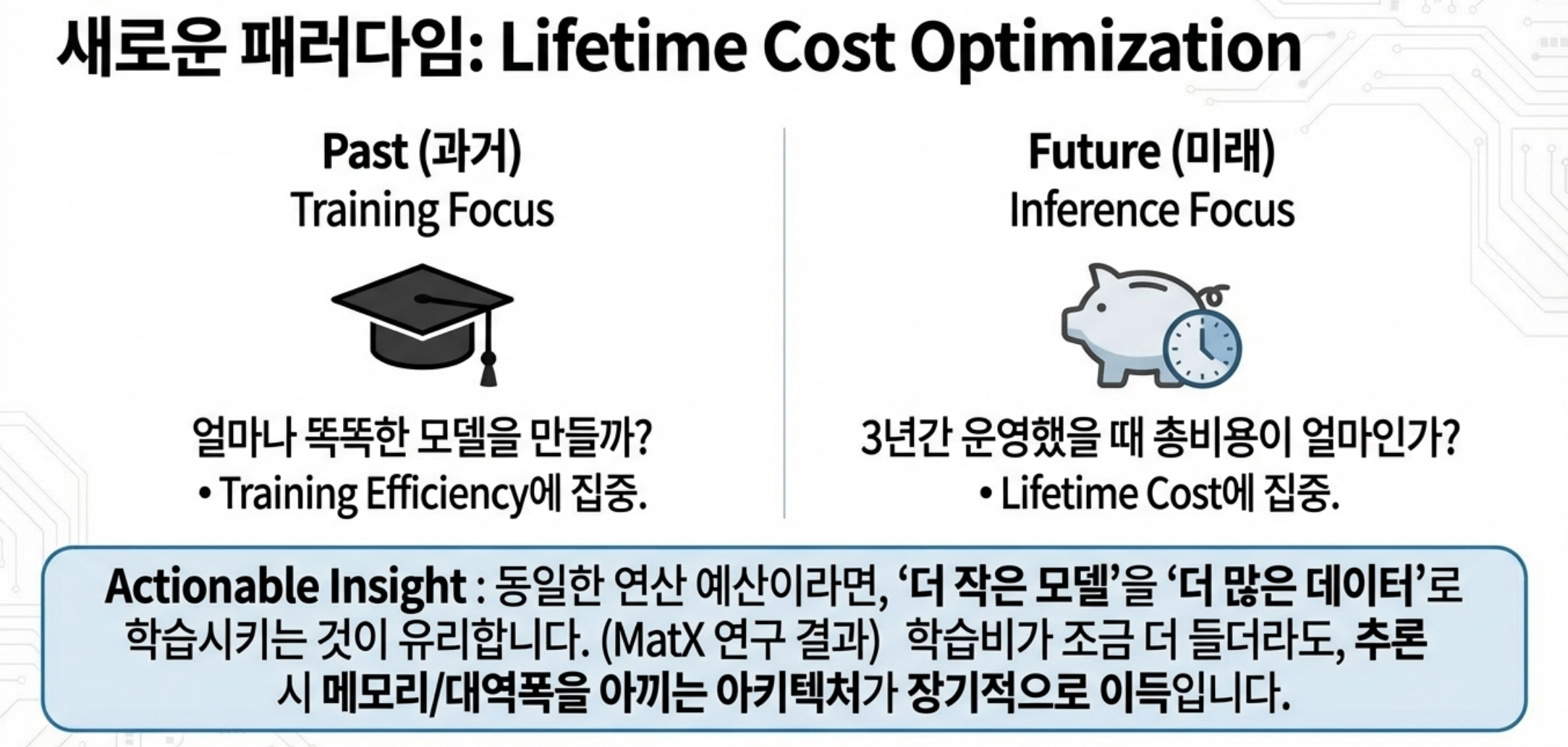
5. 모델 설계 시점부터 “수명 주기 비용”을 봐야 한다
최근에는 아예 모델 설계 단계에서부터 inference cost를 포함한 ‘lifetime cost’를 최적화해야 한다는 논의가 활발합니다.
- 기존 scaling law (Kaplan, Chinchilla 등)는 주로 training FLOPs 관점에서 “모델 크기 vs 데이터 토큰 수”의 최적점을 제시
- 하지만 MatX 등에서는 “inference 비용까지 포함하면 최적 설계가 달라진다”고 지적:
- 같은 compute 예산이면 더 작은 모델을 더 많은 데이터로 학습하는 쪽이 수명 주기 비용 대비 효율이 좋을 수 있음
- 특히 attention/KV 부분이 inference에서 병목이 되므로, “training 효율이 약간 떨어지더라도 inference에서 KV 메모리/대역폭을 아끼는 아키텍처”가 장기적으로 더 이득일 수 있음
즉, 앞으로는:
- “얼마나 큰 모델을 만들 수 있나?”보다
- “학습+추론을 합친 3년치 비용으로, 어느 지점의 모델이 비즈니스적으로 최적인가?”
를 먼저 묻는 설계가 중요해집니다
6. 마무리 관점: 투자·운영 측면에서의 체크리스트
- 우리 서비스에서 추론 트래픽 규모는 어느 정도까지 성장할 수 있는가?
- 학습은 직접 할 것인가, 파트너/오픈 모델을 활용할 것인가?
- 학습 클러스터와 추론 클러스터를 분리할 것인가, 공유할 것인가?
- KV 캐시 전략 (길이 제한, 오프로딩, tiered cache, 공유 여부)은?
- 모델 크기/아키텍처를 선택할 때, training FLOPs vs inference 비용 밸런스를 어떻게 잡을 것인가?
- SLA(응답 지연/가용성)가 어디까지 허용되는가, 그 제약 내에서 GPU utilization을 얼마나 끌어올릴 수 있는가?

뜨리스땅
출처:
1. https://www.xdnode.co.kr/guide/?idx=169628138&bmode=view
2. https://www.ibm.com/kr-ko/think/topics/large-language-models
3. https://www.redhat.com/ko/topics/ai/llm-vs-slm
4. https://velog.io/@devyulbae/LLM-추론-1편
5. https://turingpost.co.kr/p/topic-44-reasoning-models
6. https://www.ibm.com/kr-ko/think/topics/reasoning-model
7. https://clova.ai/tech-blog/생각하는-ai의-시대-패러다임의-변화-추론-모델
8. https://m.hanbit.co.kr/channel/view.html?cmscode=CMS6821227905
9. https://news.hada.io/topic?id=20002
10. https://www.helpmechatbot.com/blog/3959
11. https://www.reddit.com/r/LocalLLaMA/comments/1hretea/llms_are_not_reasoning_models/
12. https://ncsoft.github.io/ncresearch/d1d22308d4efe749b647a5ad2bc8e68bd71ccded
13. https://blog.naver.com/rainbow-brain/223820974611
14. https://brunch.co.kr/@brunchgpjz/49
15. https://www.stdy.blog/how-reasoning-models-work/
'반도체, 소.부.장.' 카테고리의 다른 글
| NVIDIA가 Groq을 인수한 이유와 의미는 무엇인가? (1) | 2025.12.27 |
|---|---|
| Anthropic은 왜 Nvidia GPU 대신 Google TPU를 선택했는가? (1) | 2025.12.07 |
| Google TPU vs. NVIDIA GPU: AI 인프라 우수성은 Chip이 아니라 시스템 (0) | 2025.12.04 |
| Google의 TPU v7 성능의 핵심 요소: 시스템 아키텍처와 네트워킹 기술 (5) | 2025.11.29 |
| AI 데이터센터 붐이 한국 배터리 산업의 촉매가 되다 (0) | 2025.11.09 |




댓글