1. AI 반도체 적용 확대 → 비메모리 반도체 Q 증가
AI 반도체 적용처가 증가하고 있다. 차량용 반도체의 경우 비전 이외에 자연어 처리 등으로 AI 적용 처리도 늘어날 수 밖에 없다. 또한 드론, 스마트팩토리, 의료용 및 로봇 등으로 적용처 확대도 긍정적이다. 이에 AI 시장 성장 → 비메모리 Q 증가 → OSAT 공정의 수혜로 이어질 전망이다. 다품종 소량 생산 특성상 후 공정이 중요해지고 기술적 난이도 또한 높기 때문이다. AI 반도체 세부 시장內 엣지 클라우드용 시장 규모는 CAGR(2021~2030F) 16%로 95억달러가 전망된다.

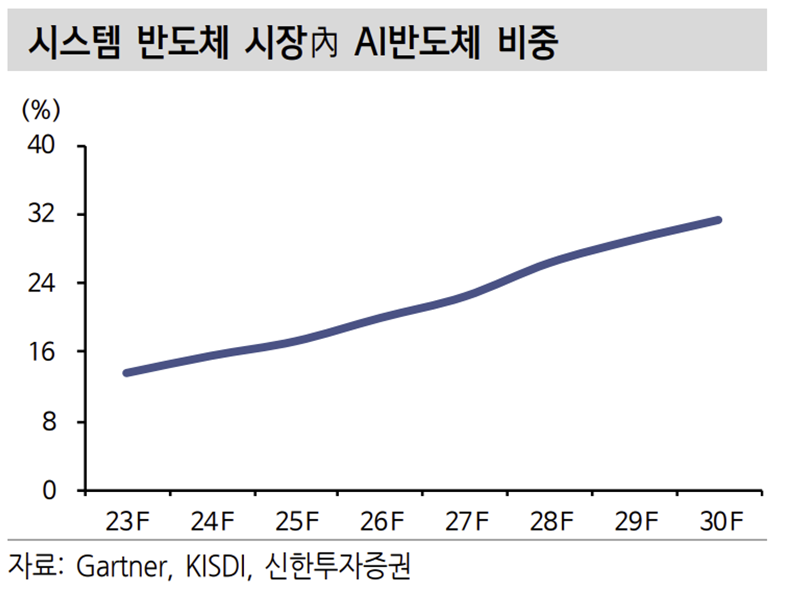
2. 고밀도, 고속의 메모리 스펙 강화
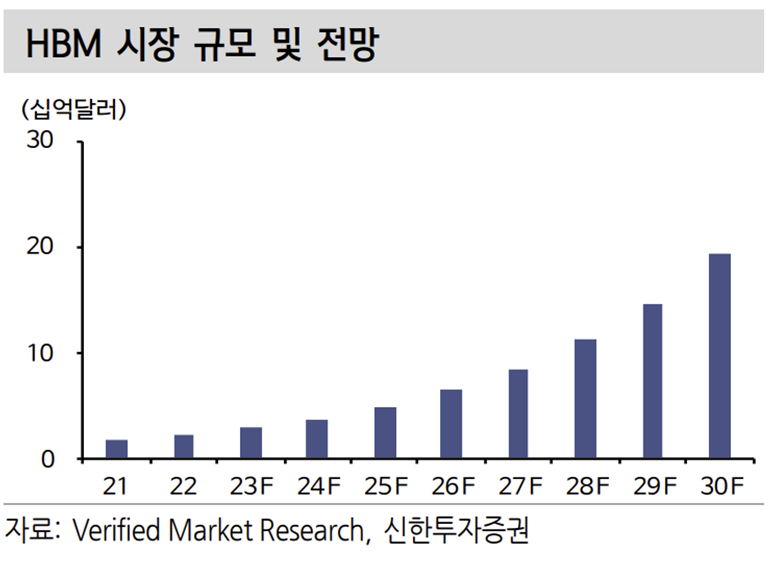
범용 GPU를 이용하여 AI를 구현하는 기존의 방식은 대규모/대용량 연산에 비효 율적이며 높은 소비전력을 요구한다. 이 한계를 해결하기 위한 HBM(High Bandwidth Memory) 수요가 확대될 전망이다. HBM은 고밀도와 고속의 메모리 기술로 높은 대역폭을 실현하여 연산 속도를 증가시킨다. AI가 확대될수록 HBM 수요도 늘어날 수밖에 없다. 고성능, 저전력, 내구성을 강화하는 기술 개발에 대 한 투자 확대를 기대하는 이유다. HBM 시장규모는 CAGR(2021-2030) 31.7% 로 2030년 193억달러을 달성할 것으로 예상된다.

결론적으로 인공 지능(AI) 기술은 대량의 데이터를 처리하고 분석할 수 밖에 없 다. 이후 패턴 파악을 통한 예측 방식이다. 이에 AI 고도화 및 수요가 증대될수 록 고성능 반도체는 필수적이다. AI 반도체의 세부 시장은 데이터센터용과 엣지 디바이스용으로 구분된다. AI 반도체 시장은 CAGR(2022~2030F) 14%가 예상된 다. 2030년 시스템 반도체 시장의 약 31.3%를 점유하며 1,186억달러의 규모로 성장할 전망이다. AI 반도체 시장 고성장으로 관련 밸류체인의 수혜가 예상된다.

3. AI 반도체 적용 확대 기대
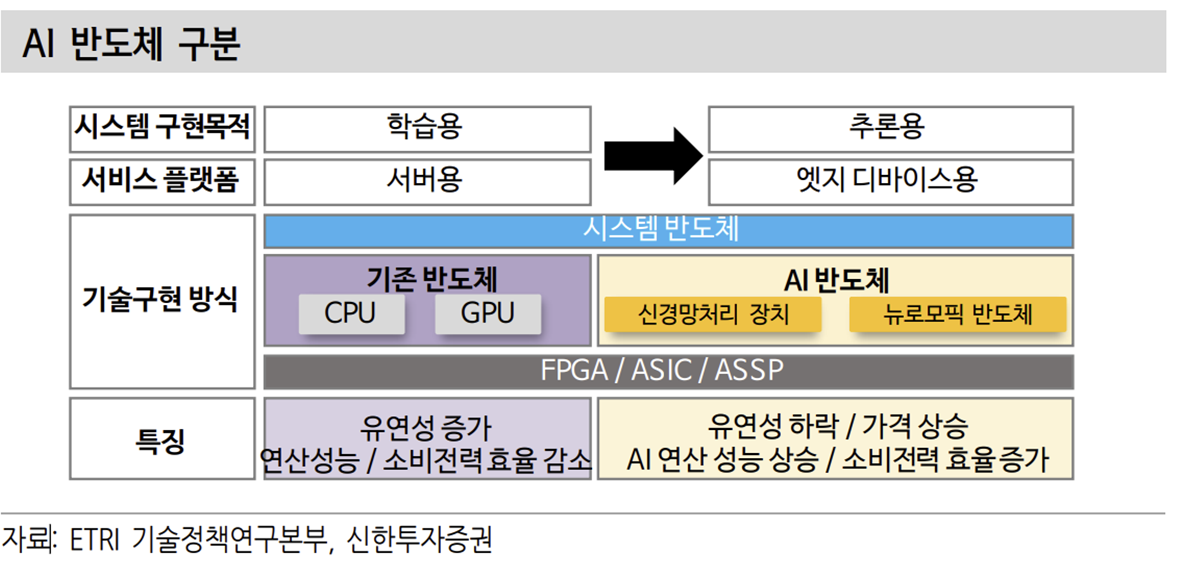
검색엔진, 자율주행 바이오테크 등의 성장 본격화로 AI 반도체의 적용 확대가 기 대된다. AI 반도체는 크게 서버와 엣지디바이스에서 활용될 것으로 전망된다. 서버에서는 TPU, AI Accelerator와 같은 형태로 AI Model의 학습을 위해 활용된다. 엣지디바이스에서는 AI Model의 추론 능력을 활용할 것으로 예상되며 SoC 내의 NPU 형태로 활용될 가능성이 높다.

AI Model은 데이터를 학습하는 학습 구간과 완성된 Model이 엣지디바이스에서 활용되는 추론 구간이 있다. AI Model은 행렬의 곱셈 형태를 띈다. 빅데이터를 넣어 학습시킬 때 행렬의 형태로 들어온 데이터를 통해 원하는 결과물을 만들어 줄 수 있는 Weight를 찾아가는 과정이 학습 과정이다. 학습 과정은 데이터센터 등에서 GPU와 같은 제품을 활용해 수 많은 데이터를 통해 진행된다.
적절한 모델이 완성된 후 엣지디바이스(스마트폰, PC, 자동차) 등에서 활용되는 과정을 거치게된다. 이미 정해진 Weight 모델에 인풋 데이터를 곱해서 결과만 추론해내게 되는 장치이다. 이런 곱셈에 특화되게 만든 것이 SoC 내의 NPU 부분이다. 상대적인 난이도나 데이터 처리량을 고려하면 서버용 AI 반도체 > NPU 의 구조가 될 것으로 전망된다.
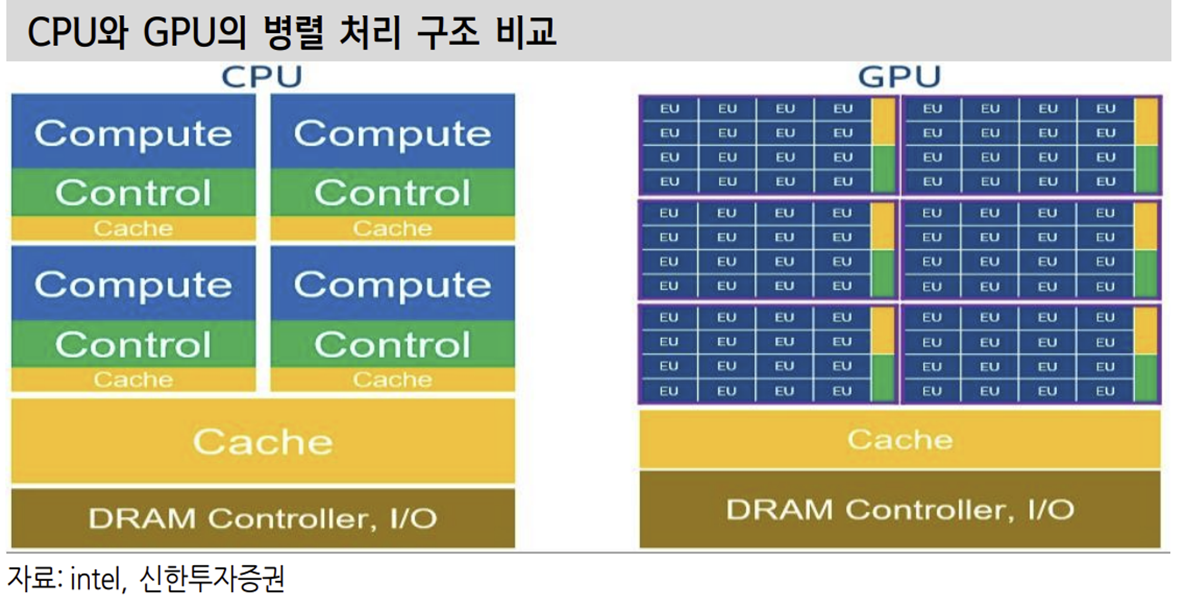
기존 AI Model 학습에는 병렬 계산을 처리하는 GPU가 활용됐다. GPU는 CPU 가 직렬 계산을 수행하며 생기는 속도 문제를 해결하기 위해 고안된 제품이다. GPU는 CPU가 처리하기에 오래 걸리는 그래픽 데이터를 처리하는 데 특화되어 있다. 병렬 처리를 통해 데이터 당 처리 속도는 느리지만 한번에 많은 데이터를 처리할 수 있다는 장점을 가지고 있다. 다만 AI 데이터 처리에 특화되어있지 않다는 게 단점이다.
그래픽 데이터 처리를 위해서 다양한 형태의 계산이 이뤄져야 하지만 AI는 무한한 곱셈의 형태를 가장 많이 띈다. 과거에는 마땅한 대안이 없 어 GPU를 활용해 AI를 발전시켰다.
Google이 2015년 TPU(Tensor Processor Unit)라는 제품을 공개했다. AI model에 특화된 반도체였다. 그 뒤 애플이 SoC에 NPU를 적용하기 시작했고 Nvidia, AMD 같은 업체들은 AI Accelerator를 시장에 공개했다. 그리고 다수의 서버업체들은 자체 칩 개발에 힘 쓰고있다.

AI 반도체는 ASIC(Application Specific Integrate Circuit)으로 특정 작업에 특화 된 반도체다. AI 반도체가 GPU 대비 가지는 강점은 효율성이다. 데이터센터 입장에서 가장 중요한 것은 데이터 처리의 효율성과 전력, 열의 관리다. 제품의 가격은 후순위다.
데이터센터는 세트업체와 달리 반도체를 비용이 아닌 CapEx(투자)로 인식한다. 가격이 비싸더라도 효율성이 좋다면 수요가 확실하다. AI 반도체 는 GPU 대비 우수한 반도체라기보다는 AI 관련 작업에서만큼 효율성이 확실한 제품이다. 속도도 빠르고 전성비도 우수한 모습을 보여준다.
4. AI 반도체 시장 확장 → 메모리 성능 향상 필요 → HBM?
현재의 폰-노이만 구조에서는 계산을 담당하는 비메모리와 이를 서포팅하는 메모리는 서로 필수적이다. 반도체의 성능을 개선하기 위해서는 비메모리의 계산 속도 개선과 이를 도와주는 메모리의 성능 개선이 필요하다. 반도체 성능 개선의 한계는 메모리 병목현상에서 주로 기인한다. 반도체 성능 개선을 위해 HBM의 적용 확대를 기대하는 이유다.
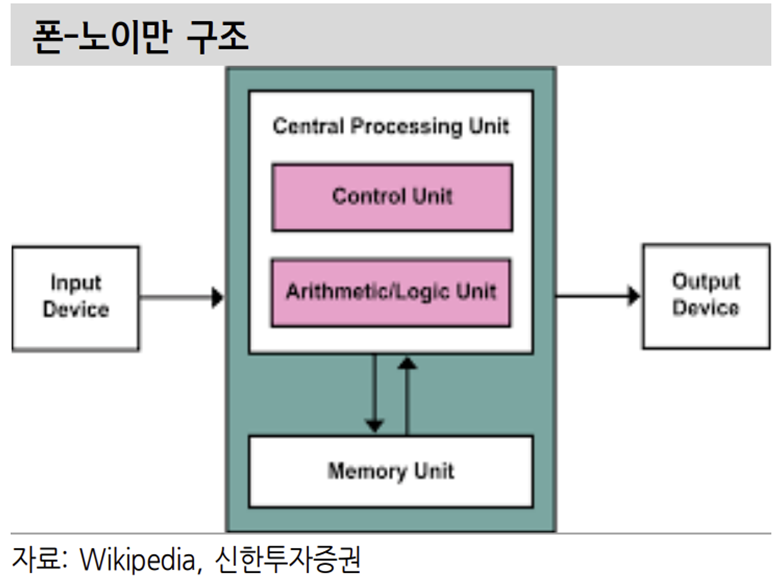
메모리는 계층 구조를 가지고 비메모리의 계산을 보조한다. Register – Cache – DRAM – Storage의 계층 구조를 가지고 있다. 위로 갈수록 속도는 빨라지지만 용량은 작아진다. 최근 DRAM의 속도 개선폭이 제한되며 병목현상을 만들어내 고 있다. 앞단 비메모리 속도를 DRAM이 쫓아가지 못하는 상황이다. 그렇다고 오버클럭해서 속도를 높이면 신뢰성과 발열이 문제가 된다.
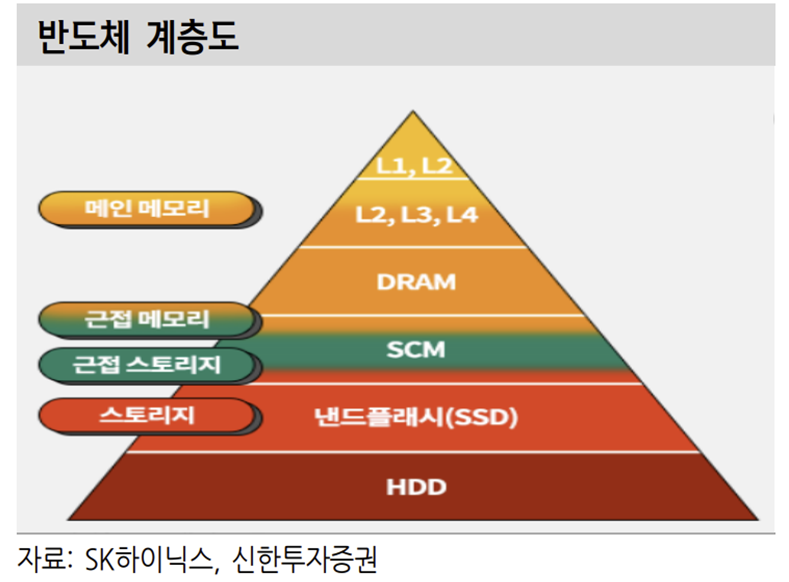
최근 반도체에서는 전공정 개선을 통해 해결하기 어려운 문제를 후공정에서 해 결하려는 모습이 보인다.
비메모리 제품은 다양한 칩을 한 군데에 만드는 SoC 같은 제품을 통해 공간을 절약하고 다양한 칩들을 실장해 특화된 작업을 진행해 속도를 개선한다. 칩 간 전송 속도의 한계를 이종 칩 간 거리를 좁히면서 해결했다. CPU의 병목을 해소하기 위해 GPU, NPU와 같은 특정 기능에 특화된 제품을 추가해 전반적인 프로세싱 파워를 높였다.
메모리도 마찬가지로 점점 비메모리와 가까운 위치로 움직이면서 병목을 해소하려고 했다. 패키징부터 기존의 와이어 방식에서 볼 방식으로 변경됐고 최대한 CPU 가까이 위치되며 속도 개선에 힘썼 다. 하지만 여전히 한계가 있었던 것으로 보인다.
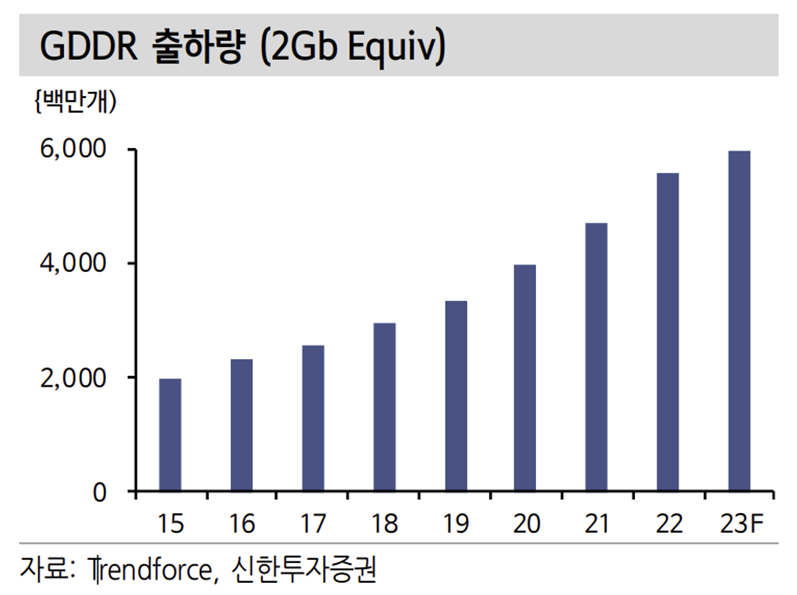
HBM이 이런 문제를 해결하기 위한 대안으로 떠올랐다. JEDEC이 정하는 여러 가지 규격에는 DDR, LPDDR, GDDR, HBM 등이 있다. PC, 서버에 주로 사용하는 제품이 DDR이다. 대기 시 저전력의 강점을 가진 LPDDR 제품은 모바일 기 기에 주로 채용된다. GDDR은 GPU를 서포팅하는 용도로 사용된다. HBM은 High Bandwidth Memory의 약자로 현재는 주로 GPU에 사용된다. GDDR과 직접적인 경쟁 상황에 있는 제품이다.
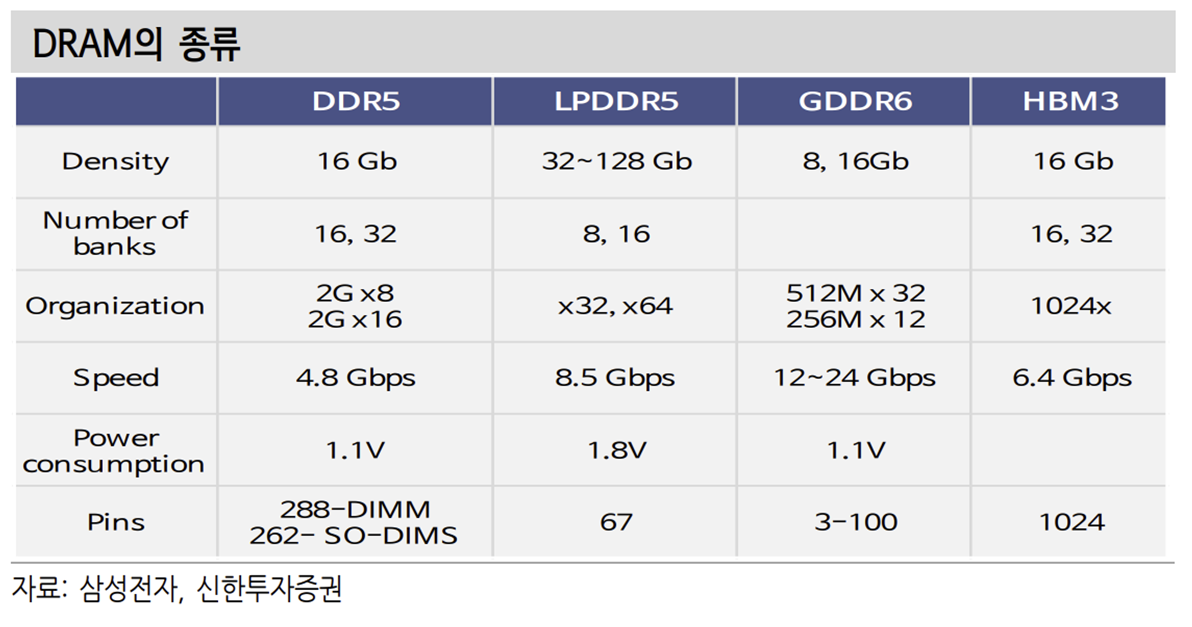
메모리 병목 현상을 해결하기위한 방법으로 GDDR 대신 HBM이 떠올랐다. 주 된 차이점은 I/O(Pin 개수)가 많아진다는 점이다. GDDR 제품은 I/O가 3개에서 100개로 HBM의 1024개와 차이가 크다. 주로 I/O는 차선에 비교하는 데 차선 이 많아질 수록 한번에 많은 차들이 체증없이 다닐 수 있고 발열과 신뢰성 모두 개선된다.
다만 단가가 상당히 높게 형성되기에 서버 제품 위주로 채택이 되고 있다. 위에서 언급했듯이 서버업체들의 제품 채택 최우선 요소는 효율성이다. B2C 제품과 다르게 가격이 우선 순위가 아니다. 성능 개선만 확실하다면 채용할 요소가 확실하다.
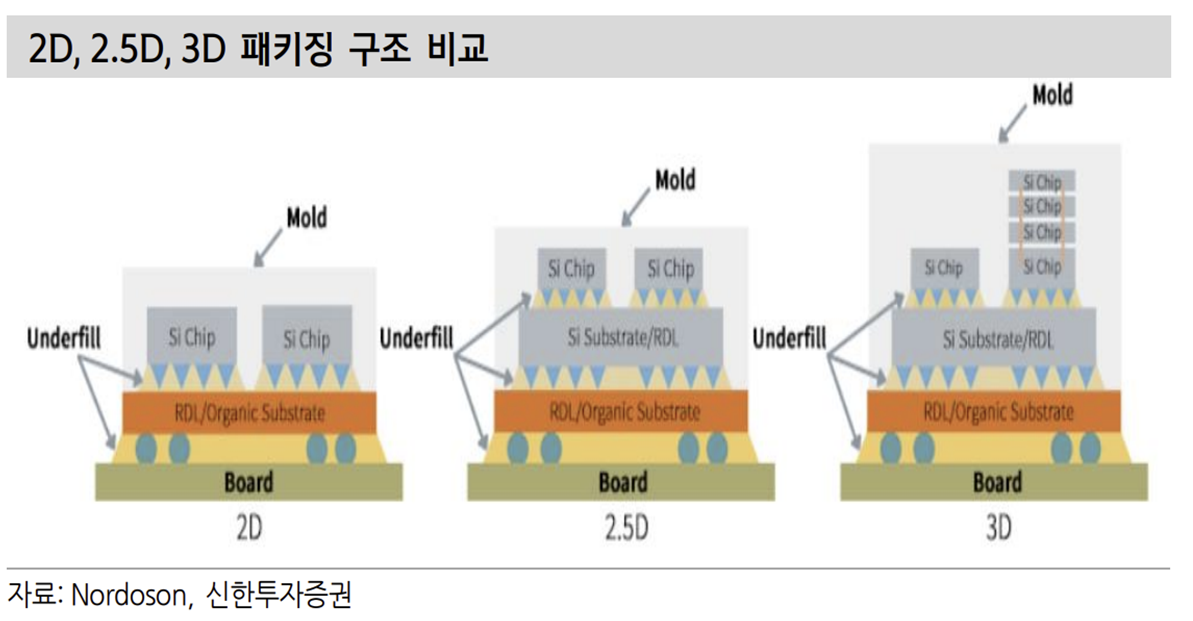
HBM이 활용되는 대표 제품은 AMD의 GPU가 있다. 그리고 여기서 2.5D 패키 징이라는 개념이 나온다. 기존의 패키징은 주로 2D 패키징이었다. 다양한 칩들 이 수평선 위에 위치해 작동하는 형태다. 다음 형태의 패키징이 3D 방식이다. 칩 들을 위아래로 수직적인 위치에 배열해 속도 개선 및 공간 절약을 동시에 가져 가는 형태다. 2.5D 패키징은 실리콘 인터포저를 사용한다. 보통 2D나 3D 패키징은 패키징 기판과 범프를 이용해 연결한다.
하지만 위에 언급했듯이 HBM의 I/O는 1000개 가량이다. 이걸 기판을 통해 연결하는 방식은 효율적이지 않다. 때문에 웨이퍼 공정을 통해 만든 실리콘 인터포저를 통해 비메모리와 메모리를 연결하고 인터포저를 패키징 기판과 다시 연결하는 방식을 가진다.
2.5D 패키징을 활용해 GPU 성능을 개선했다. 이제 적용만 확대되면 될 것 같지만 여기도 문제점이 존재한다.
1) 2.5D 패키징을 하면 가격이 비싸진다. B2C 제품에서의 적용 확대를 기대하기는 어렵다. 단가가 기본적으로 훨씬 높기 때문이 다. 실리콘 인터포저 자체만으로도 몇십불 정도인 것으로 알려져 있다. 또한 병목 해소를 위해서 무작정 HBM을 늘릴수 없다. 칩에도 연결 부위를 따로 만들어 줘야되기 때문에 비용 증가가 어마무시하다. 칩이나 기판은 크기가 커질수록 단 가가 지수함수 형태로 증가한다. 불량률이 높아져 수율이 낮아지기 때문이다.
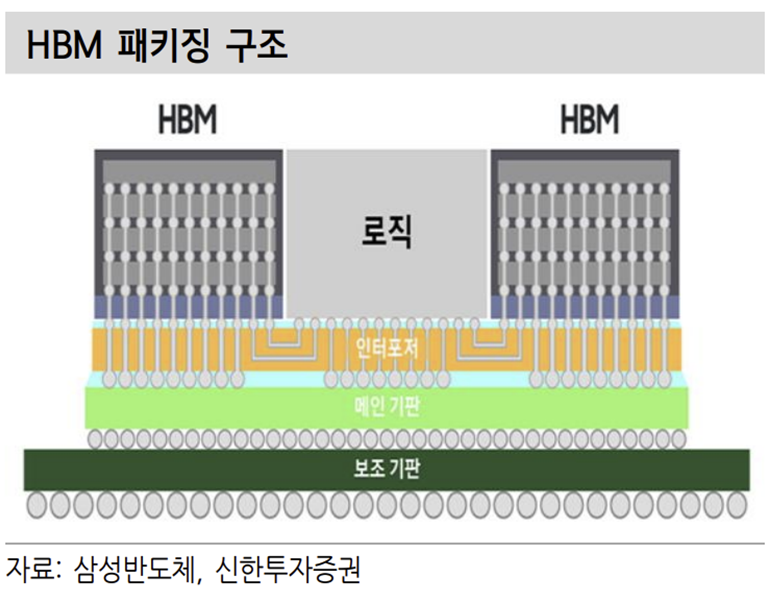
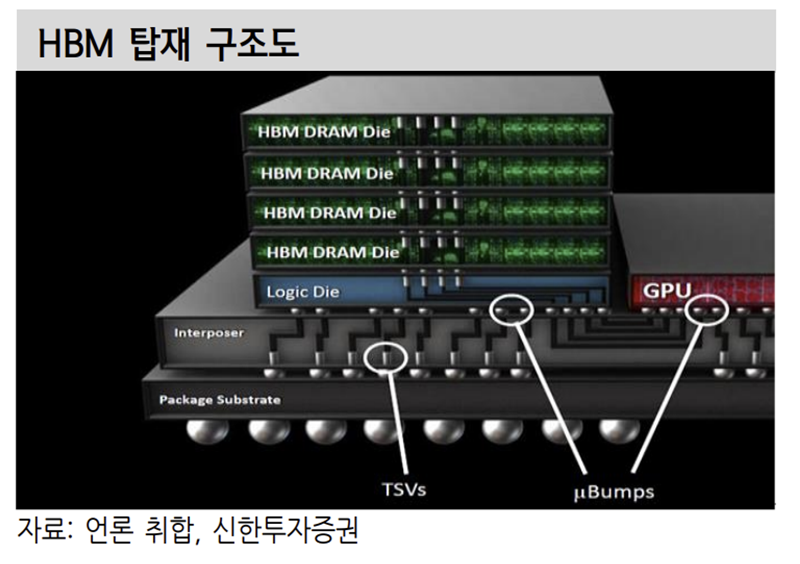
2) HBM 제품 자체도 수율이 좋지 않다. 메모리는 기존에 와이어본딩이나 플립칩 본딩의 방식을 사용했다. 다수의 칩을 패키징 기판에 와이어를 통해 연결하거나 플립칩 방식으로 디램을 1개씩 연결한 모듈을 사용한다. HBM은 다수의 디램은 TSV 공정을 통해 Peri 부분에 구멍을 뚫어 연결해 만든다.
많은 수의 홀을 정확 하게 연결해야하는데 이 공정 자체가 수율이 높지 않은 것으로 알려져있다. 수율이 높지 않다는 뜻은 단가를 단시간에 낮추기는 어렵다는 뜻이다. 수율에 문제가 있으면 메모리 업체들도 선뜻 생산을 확대하기에 망설여질 수 밖에 없다.
AI 시대의 개막 및 GPU의 필요성 증가로 HBM 수요는 서버 위주로 증가할 전망이다. 아직까지는 적용 비율이 많지 않은 것으로 추정된다. GDDR 제품을 대체하며 시장을 대체할 것으로 예상되나 현재 GDDR 제품의 전체 DRAM 시장 비중은 5% 수준으로 작다.
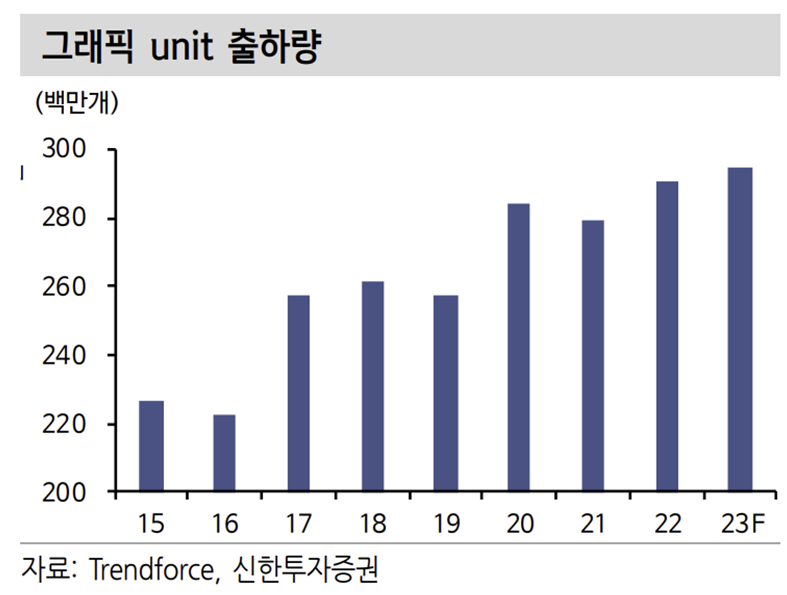
AI에 대한 수요는 꾸준히 증가할 것으로 전망되는 만큼 과거 서버 DRAM이 비중이 작았던것 처럼 결국은 중요성과 비중이 확대될 것으로 전망한다. 이 과정에서 제품 수율을 높이기 위해 후공정 장비의 필요성이 증가할 것이다. 그리고 이종 칩 간의 연결을 위해 마이크로 솔더볼 수요 증가, 패키징 기판 및 테스트 소켓의 대면적화 및 ASP 상승이 기대된다.
출처: 신한투자증권, Trendforce, 삼성반도체, SK Hynix, Verified Market Research, 심텍, SFA반도체, Nordson
뜨리스땅
https://tristanchoi.tistory.com/401
반도체 기술 탐구: ChatGPT가 유발한 반도체 메모리의 수요 - HBM
IT 업체는 보통 기존 제품군의 점진적인 성능 개선을 통해 경쟁하지만, 가끔은 진정한 파괴적 기술이 등장한다. 지금 엔터프라이즈 시장으로 막 진입하기 시작한 이러한 파괴적 기술 중 하나가
tristanchoi.tistory.com
https://www.youtube.com/watch?v=JG422qKjZN8
'반도체, 소.부.장.' 카테고리의 다른 글
| 반도체 산업 탐구: 미래의 일 - AI와 일하기 (0) | 2023.03.27 |
|---|---|
| 반도체 산업 탐구: 비 메모리의 미래 - 인공지능 AI (2) | 2023.03.26 |
| 반도체 기술 탐구: ChatGPT가 유발한 반도체 메모리의 수요 - HBM (0) | 2023.02.15 |
| 반도체 기업 탐구: 반도체 소부장, 2022 결산 & 2023 전망 - 2 (1) | 2022.12.28 |
| 반도체 기업 탐구: 반도체 소부장, 2022 결산 & 2023 전망 - 1 (1) | 2022.12.28 |




댓글