1. CPU와 CPU의 Core
CPU와 마찬가지로 GPU 내부에도 연산을 처리할 수 있는 Core들이 존재한다. 하지만 CPU와 GPU Core 구성에는 큰 차이가 존재한다.
CPU는 하나의 Core가 순차적으로 직렬 처리되는 프로세스를 효율적으로 처리하기 위해 만기 때문에 단일 Core 성능을 GPU와 비교한다면 월등히 뛰어나다고 할 수 있다.
하지만 GPU는 병렬 처리를 기반으로 한 아키텍쳐를 채택해 설계되었기 때문에 여러 Data들을 병렬로 효율적으로 처리할 수 있습다. 이러한 이유로 GPU를 Throughput 기반의 Architecture라고 부르기도 한다.
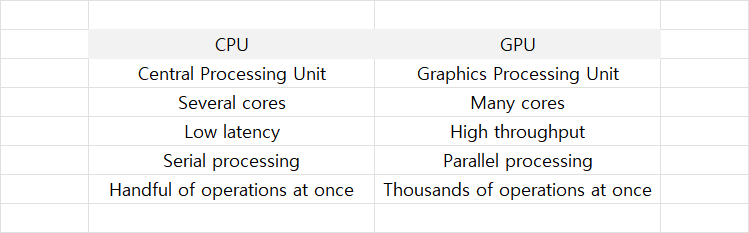
GPU는 CPU보다 더 단순한 Core들로 구성되어 있지만 CPU가 일반적으로 1에서 8개의 Core를 갖는 것에 비해 GPU는 보통 수백에서 수천 개의 Core를 갖는다. 때문에 많은 양의 Data sets를 병렬로 처리해야 하는 AI 연산에 GPU가 선호되고 있다.

GPU의 Core는 더 작은 용량의 Cache, 작은 Instruction set, 낮은 Clock rate를 갖는다. 그렇지만 CPU보다 매우 많은 Core가 밀집되어 있기 때문에 병렬 처리에 유용하다. GPU 내에서 CUDA Core의 수는 더 좋은 Computing performance를 낼 수 있다는 말과 동일하다. 하지만 GPU의 서로 다른 세대 간의 성능을 비교할 때는 단순히 Core의 수 만으로 비교할 수는 없다. GPU 안에서도 세대를 변화하며 단일 Core의 성능이 달라지기 때문이다.
최신 NVIDIA GPU 안에는 세 가지 종류의 Core가 존재하며, 각 core 들은 서로 다른 목적을 위해 설계되었다.
(1) CUDA cores (2) Tensor cores (3) Ray-Tracing cores

2. CUDA Core란?
GPU 상에서 CUDA Cores가 하는 일은 근본적으로 CPU 내부의 Core가 하는 일과 유사하다. 하지만 CPU와 달리 Instruction을 가져오거나 Decoding 할 수는 없다.
구조적으로 CPU는 큰 크기의 Cache memory와 함께 한 번에 몇 개의 Thread를 처리할 수 있는 소수의 Core로 구성된다. 이와 대조적으로 GPU는 수천 개의 Thread를 동시에 처리할 수 있는 수백에서 수천 개의 CUDA Core로 구성된다. 이를 통해 GPU는 CPU보다 훨씬 많은 작업을 빠르게 처리할 수 있으며 이런 특징을 통해 AI분야의 Deep Learning 연산에서 핵심적인 역할을 할 수 있다.
일반적으로 CUDA Cores는 Tensor Cores에 비해 느리지만 fp32 연산을 수행하기 때문에 더 정확한 연산을 수행할 수 있다. Tensor Cores 는 fp16 연산이기 때문에 계산 정확도를 어느 정도 희생해야 한다.
단순히 CUDA Cores의 수로 GPU의 성능을 판단하기에는 많은 제한 조건들이 있다. 어떤 GPU Architecture를 채택했는가 부터 *GPU Clock speeds, Memory Bandwidth, Meory speed, TMUs, *VRAM, ROPs 등은 성능에 영향을 미치는 요소들이다.
하지만 동일한 GPU Architecture 내에서는 이런 조건들이 비슷하기 때문에 CUDA Cores의 수로 성능을 비교할 수 있다. 많은 수의 CUDA Cores는 Performance bottleneck 현상을 일으키는 다른 요인이 없는 경우 같은 Generation에서 더 좋은 성능을 의미한다. 하지만 다른 Generation 사이에서 성능을 비교하는 경우는 이와 상황이 다르다.
예를 들어 GTX 1070은 GTX 780과 거의 동일한 수의 CUDA Core를 갖고 있지만 성능 면에서 월등한 차이를 갖고 있다. 이런 성능 차이는 단일 Core의 성능 차이와 세대를 거듭하며 발전하는 제조 공정 차이, 트랜지스터의 크기 차이 등에 기인한 것으로 판단된다.
GTX 980 Ti(Maxwell architecture)와 GTX 980 Ti(Pascal architecture)의 경우는 비슷한 수의 CUDA Core와 Transistor가 존재하지만 트랜지스터의 크기가 이 둘의 성능을 비교하는 데에 결정적인 역할을 했다. 더 작은 Transistor를 사용하는 Pascal architecture의 전력 소비 감소로 작은 공간에 많은 트랜지스터를 집적할 수 있었으며 이를 통해 최대 Clock frequency를 증가시킬 수 있었다. Clock frequency의 증가로 단일 Core가 더 빠르게 작업을 수행할 수 있었으며 이는 두 Architecture 간의 성능 차이로 이어졌다.
NVIDIA에서 자사의 GPU Cores를 CUDA Core로 명명한 것 처럼 AMD 사에서는 이를 Stream Processor라고 부른다. 두 회사의 Architecture가 근본적으로 다르게 설계되었기 때문에 CUDA Cores의 수와 Stream processor의 수만 보고 성능을 비교할 수는 없다. 하지만 Benchmark simulation을 통해 두 Architecture의 성능을 보다 정확히 비교할 수 있다.
*GPU Clock speeds : Core Clock speed(GPU 동작 속도)와 Memory Clock speed(VRAM 동작 속도)
*VRAM : GPU를 통해 처리되는 assets, textures, shadow maps등을 포함한 모든 Data를 저장합니다. DRAM, SSD, HDD에 비해 접근성이 좋고 빠릅니다.
3. Tensor Core란?
Tensor cores란 NVIDIA에서 개발한 행렬 곱셈 프로세스를 가속하는 처리 장치이다. CUDA Cores가 1 Core Clock에 하나의 fp32 부동소수점 연산을 수행하는 것에 비해 Tensor Cores는 같은 Term 동안 4 x 4 크기의 fp16 행렬 두 개를 곱하고 그 결과를 4 x 4 fp32 행렬에 더하는 Matrix multiply-accumulate 연산(A와 B를 곱하고 C를 더하는 과정을 하나의 연산으로 수행)을 수행한다.
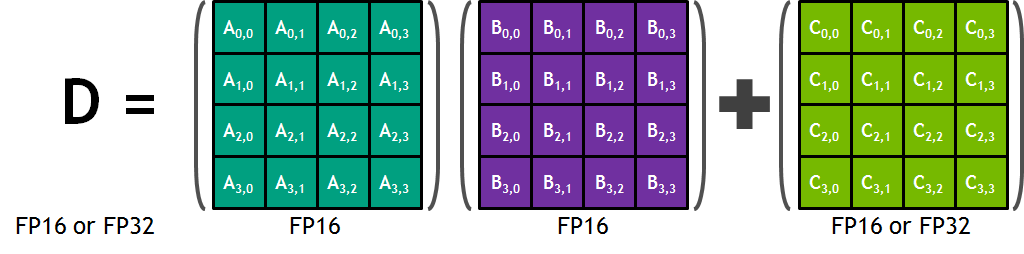
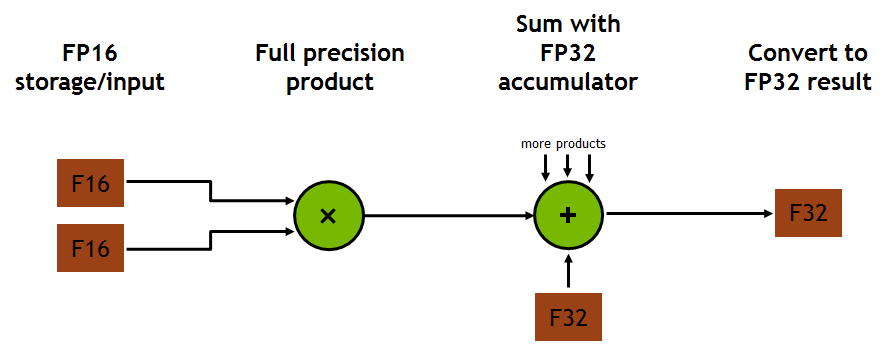
이 과정에서 fp16 행렬을 입력 받고 fp32 행렬을 출력하기 때문에 Mixed precision이라고 불린다. 또한 이 연산은 Rounding이 한번 일 때 FMA(Fused Multiply-Add)라고 불리기도 한다. 각 Tensor core는 한 번의 GPU Clock에 64개의 부동소수점 연산을 하는데 이는 출력 행렬의 한 원소를 계산하기 위해 4 개의 FMA 연산이 필요하고 총 4 x 4 (16개)의 원소가 존재하기 때문이다.
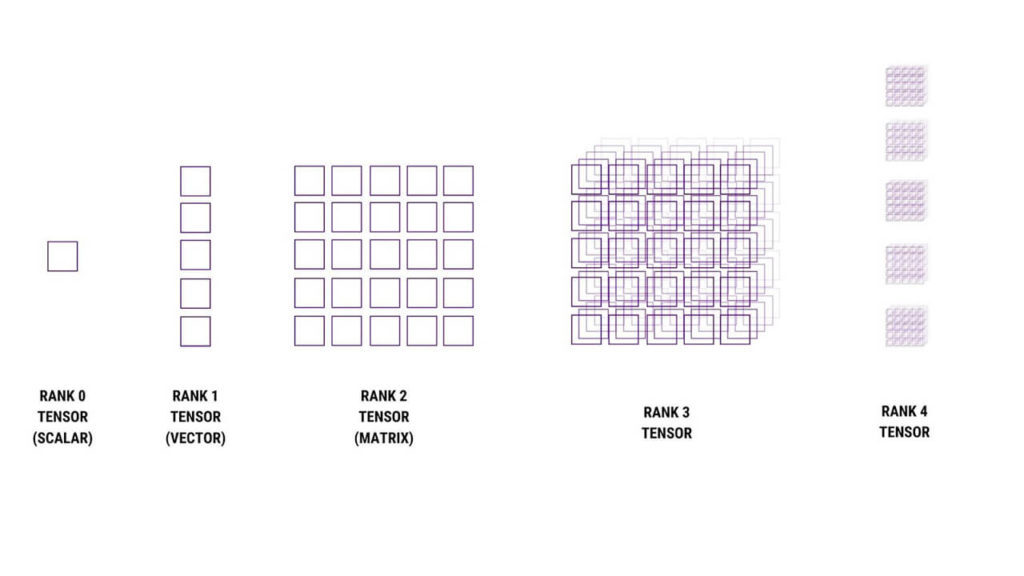
Tensor Cores라는 이름에서 'Tensor' 의 의미는 무엇일까? Tensor란 다차원의 Data sets 를 저장할 수 있는 컨테이너로 행렬의 확장으로 생각할 수 있다. 행렬은 숫자를 포함한 2차원 구조이지만 Tensor는 숫자의 다차원 집합으로 표현된다.
모든 마이크로 프로세서는 산술 및 논리 연산을 수행한다. 이 중 중요도가 높은 산술 연산 중 하나는 바로 행렬 곱셈 이다. 하지만 2개의 4 x 4 행렬의 곱셈을 수행하려면 이론적으로 64개의 곱셈 연산과 48개의 덧셈 연산이 필요하다. 그렇기 때문에 NVIDIA는 연산의 정확도를 희생하여 더 많은 연산을 빠르게 수행할 수 있는 Tensor Cores를 세상에 출시하였습다. NVIDIA의 Volta Architecture에서 이 기술이 최초로 적용되었으며 그 이후의 Architecture에도 이를 적용하여 훨씬 빠르게 연산을 수행할 수 있게 되었다.
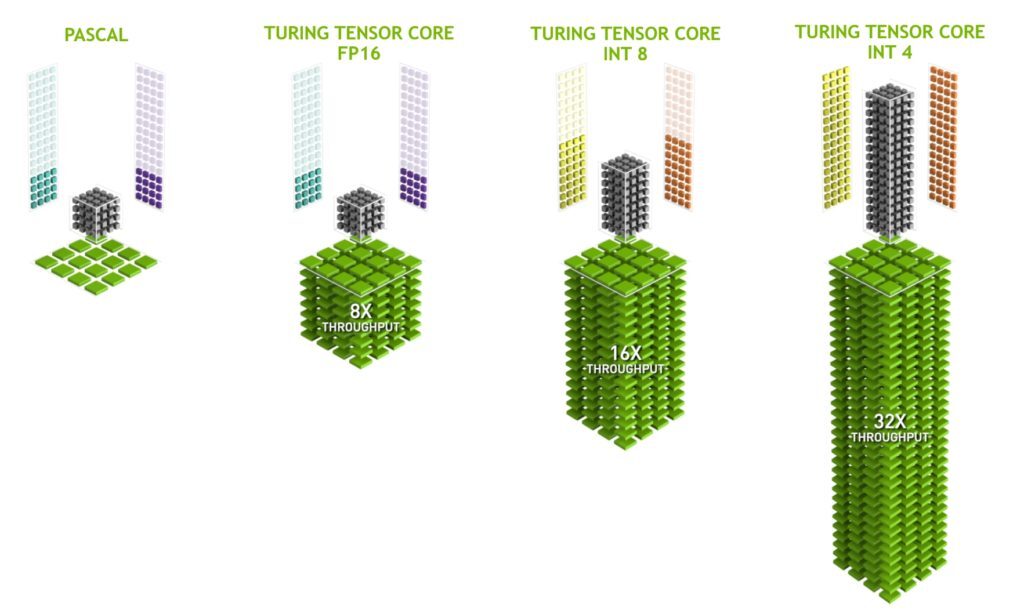
Tensor Cores는 Clk 주기 당 여러 작업을 한 번에 수행할 수 있으며 CUDA Cores 보다 훨씬 높은 처리량(Throughput)을 수행한다. 기계 학습 분야의 경우 비용과 계산 속도 면에서 Tensor Cores의 성능은 CUDA Cores를 크게 앞지르고 있으며 AI 연산 분야와 그 응용 분야들에서 널리 사용되고 있다.
CUDA Toolkit에서 제공하는 라이브러리인 cuBLAS와 cuDNN에서는 Tensor Cores를 지원하고 있다. cuBLAS는 행렬과 행렬의 곱셈 연산인 GEMM 연산에 Tensor Cores를 이용하고 cuDNN 에서는 Convolution 연산에 이를 이용하고 있다.
실험 결과 Tensor Cores는 cuBLAS에서 4에서 9배, cuDNN에서 4에서 5배의 성능 향상을 이끌었습니다. Tensor Cores가 처음 적용된 Architecture인 Volta의 model 중 Titan V는 5120개의 CUDA Cores와 640개의 Tensor Cores를 갖고 있다.
하나의 Tensor Core 는 한 Cycle에 64개의 FMA를 수행하며 이는 한 번에 128개의 부동소수점 연산을 수행하는 것과 같다. 따라서 Titan V 의 경우 640개의 Tensor Cores가 있으므로 Cycle마다 128 x 640 개의 부동소수점 연산을 수행할 수 있다. Turing Architecture의 경우 딥러닝 추론 속도 향상을 위하여 INT8과 INT4 연산을 추가했는데 이를 통해 연산에 필요한 비트 수를 대폭 줄이고 연산 속도를 극적으로 향상시키는 Quantization 기법을 적용하였다.
출처: 블로그 ComSys_jh
뜨리스땅
https://tristanchoi.tistory.com/609
엔비디아(NVIDIA) 아키텍처 로드맵
엔비디아는 2023년 10월 투자자 발표 슬라이드에서 "2024년 ~ 2025년의 차세대 '서버(데이터센터) GPU' 로드맵이 공개했다. ①-1. 서버(데이터센터) 'GPU' : x86 마이크로아키텍처 '훈련 & 추론' - 2021년 : A10
tristanchoi.tistory.com
'반도체, 소.부.장.' 카테고리의 다른 글
| 온디바이스 AI: NPU 시장을 견인하다 (0) | 2024.02.29 |
|---|---|
| CUDA: 소프트웨어 때문에 하드웨어를 못 바꾸나? (0) | 2024.02.28 |
| NPU: 딥러닝에 최적화된 칩 (0) | 2024.02.27 |
| 딥러닝: AI에 최적화된 알고리즘 (1) | 2024.02.27 |
| 엔비디아(NVIDIA) 아키텍처 로드맵 (0) | 2024.02.26 |




댓글