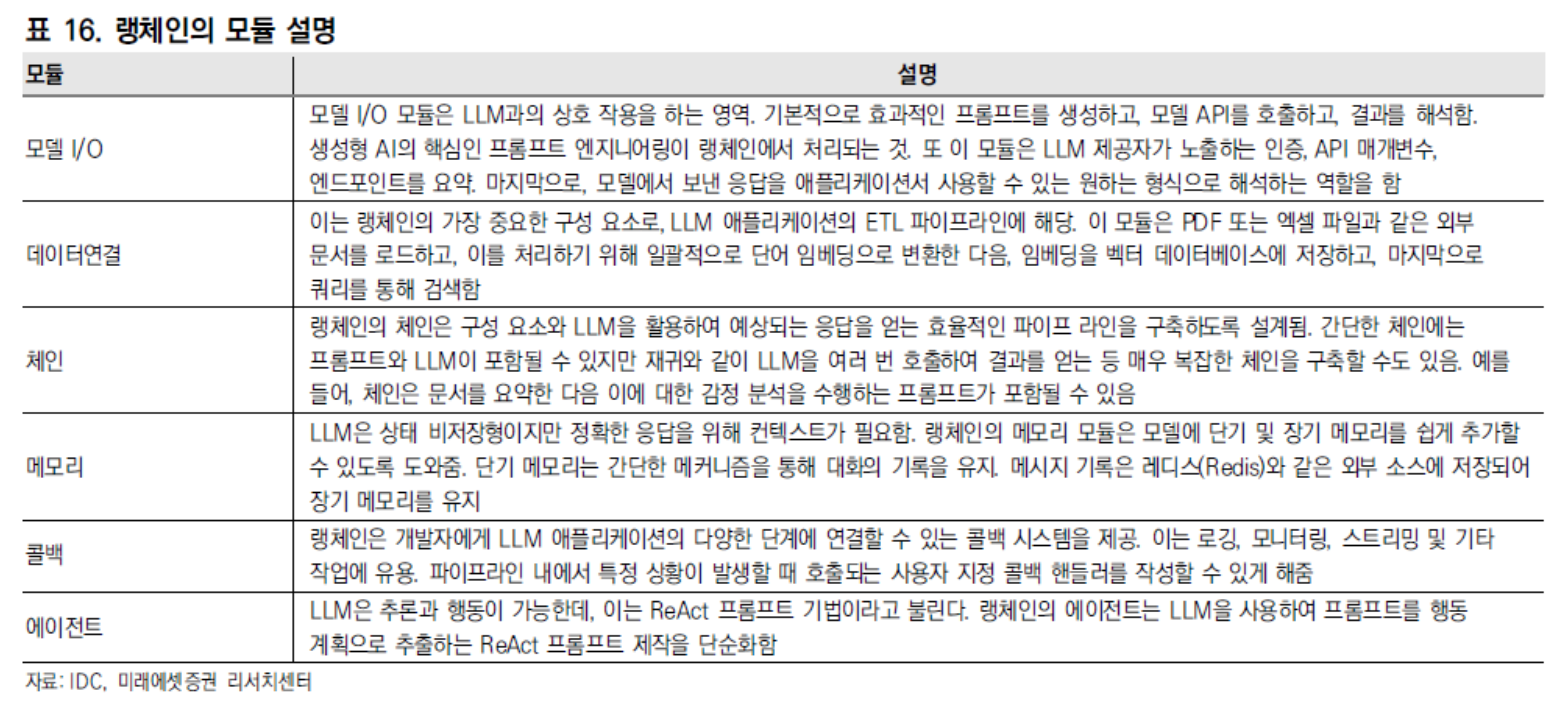
1. 생성AI의 ‘수익화’
현재 기업들의 가장 큰 고민은 생성AI의 ‘수익화’다. 이를 위해 테크 기업들은 이용자의 니즈를 충족할 수 있는 비즈니스 모델을 만들어 나가는 것에 집중하고 있다.
생성AI 밸류체인은 LLM(Large Language Model 초거대언어모델)부터 시작되는데, 이를 응용 어플리케이션으로 만들기 위해서는 중간에 LLM을 구동 시켜 줄 수 있는 인프라 플랫폼이 필요하다. 바로 클라우드 컴퓨팅과 미들웨어다.
결국 실질적으로 클라우드 컴퓨팅과 미들웨어가 어플리케이션의 비용과 성능에 직결되기 때문에, 이들을 얼마나 효율적이고 적합하게 사용하느냐가 어플리케이션을 개발해 나가는 현 시점에 핵심이 될 수 있다.
어플리케이션은 가시적인 사용처를 찾을 수 있는 B2B 영역에서 먼저 등장하고 있다. 기업에서는 주로 사람들이 하는 업무를 자동화하거나, 절차를 간소화하는 것 등에서 생성AI를 활용하려고 시도 중이다. 뿐만 아니라 각 산업별로 반드시 필요한 특정 업무에서 생성AI를 적극적으로 도입하고 있다.
기업에서 생성AI LLM을 사용할 때 가장 염두하는 부분은 크게 세 가지다. 1) 파인튜닝과 2) 보안, 3) 비용이다.

기업에서는 특정 업무나 산업에 특화된 용도에 필요한 AI의 역할을 찾는다. 그러다보니 범용적인 데이터 세트를 학습한 LLM은 불충분하다. 산업에 특화된 데이터를 추가로 학습해야 한다. 이 때 파인튜닝이 필요하다. 기업용 솔루션을 위해서는 파인튜닝이 필수적이다. (파인튜닝: Fine-Tuning, 미세조정. 사전 학습된(pre-trained) 인공지능 모델을 이용해 필요한 과제에 맞게 모델을 다시 학습시키는 것을 말함. 사전 학습된 모델의 가중치를 새로운 데이터에 맞게 세밀하게 조정하여 성능을 향상시키고 학습 시간을 줄이는 과정)
두번째로는 보안이다. 기업에서 LLM을 사용할 때 기업의 내부 정보를 프롬프트에 작성할 수도 있고, 내부 데이터 자체를 파인튜닝 해야 할 수도 있다. 이 때 클라우드 기반의 LLM에 데이터가 유출되는 위험을 기업들은 우려한다.
그리고 기업들은 무엇보다 비용에 민감하다. 최근의 초거대 모델들은 비용이 많이 들 수밖에 없다. 따라서 기업들의 니즈를 충족하는 제품들이 등장하기 시작했다.
2. LLM 모델의 다양화
기업들이 원하는 방향으로 모델을 효율화하기 위해 기술적으로 다양한 형태의 LLM이 등장하고 있다. 대표적으로 private LLM, 온프레미스 LLM, sLLM이다.

Private LLM
Private LLM이란 개인 정보 보호 및 데이터 보호를 우선시하도록 설계된 언어 모델이다. 훈련 및 추론 중에 사용자의 데이터 노출을 최소화하는 것을 목표로 하는 기술로 구축됐다. Private LLM으로 데이터를 보호하는 방법으로 4가지가 있다.

- 연합학습 혹은 차등정보보호: Private LLM은 연합학습(federated learning)이나 차등정보보호(differential privacy) 등의 방법으로 데이터를 보호할 수 있다.
연합학습(federated learning)이란, 분산형 데이터 소스에서 모델을 훈련하는 방법이다. 기존 머신러닝은 하나의 고성능 서버에 대용량 데이터를 업로드해서 학습했다. 그러나 연합 학습은 여러 대의 컴퓨팅 자원에서 각각 알고리즘을 학습한 뒤, 그 결과를 통합해 최종 학습 모델을 만드는 방법이다.
대표적인 사례로 각 스마트폰에 저장된 데이터로 각각의 스마트폰에서 기계 학습을 진행한다. 학습된 모델을 압축하고 암호화한 뒤 클라우드에 전송한다. 클라우드에서 여러 스마트폰에서 학습된 정보가 결합되어 학습 모델이 개선될 수 있다. 이렇게 개선된 모델은 다시 개개인의 스마트폰에 전송되어 기존 모델보다 더 정밀한 예측 모델이 되는 것이다.

차등정보보호(differential privacy)란 데이터 트레이닝 과정에서 데이터에 노이즈를 추가해 특정 사용자 정보 식별을 어렵게 만드는 방법이다.
- 암호화 및 보안 계산: 훈련 및 추론 단계 전반에서 암호화 및 보안 프로토콜을 반드시 사용한다. 데이터를 모델로 보내기 전에 암호화하고, 안전한 보안 기술을 사용해 데이터를 처리하는 것이다.
- 데이터 최소화: 데이터 수집 및 저장을 최소화 해 양을 줄이면 잠재적인 개인정보 침해 위험이 크게 줄어들 수 있다.
- 정기 감사 및 평가: 정기적인 개인 정보 보호 감사와 평가를 수립해 사립 LLM에 구현된 보안 및 개인 정보 보호 조치를 평가한다.
온프레미스 LLM
모든 데이터 처리 및 모델 작업을 자체 인프라에서 진행하는 LLM이다. 이 LLM은 내부 네트워크에서 작동해 강력한 네트워크 보안 조치도 구현 가능하다. 현재 OpenAI의 GPT나 구글의 바드 등 우리가 잘 알고 있는 거대 파라미터의 LLM은 온프레미스로 제공될 수 없다. 온프레미스로는 감당할 수 없는 규모이기 때문이다. 따라서 온프레미스 LLM은 범용적인 기능보다는 한정된 기능을 제공하는 소형 LLM을 선택할 때 사용할 수 있다.
sLLM (엣지LLM)
기업에서는 메모 및 프레젠테이션 초안 작성, 이메일 편집, 질문 답변, 사본 요약 등을 위해 LLM 기반 앱을 채택하는데, LLM을 활용하여 효율성을 높이고 비용을 절감하는 것이 목표지만 사용량이 증가함에 따라 비용이 기하급수적으로 증가하게 된다. 파라미터가 1,000억개 넘는 LLM을 구동시키는 것은 매우 고사양의 인프라를 요구하기 때문에 비용이 많이 들기 때문이다.
이를 위해 등장한 것이 sLLM이다. 다른말로 엣지 LLM이라고도 부른다. 특정 요구 사항을 가진 사용자 정의에 맞게 소규모로 구축하는 LLM을 뜻한다. GPT-4나 Bard의 파라미터가 1,000억개가 넘는 것과 달리 10억개 수준의 파라미터를 가질 수 있다. 그러므로 당연히 데이터 학습에 사용되는 컴퓨팅 비용이 절감된다.

이 LLM은 산업별 데이터 세트를 교육함으로써 특정 요구 사항에 맞게 모델을 맞춤화하고, 이를 통해 AI 투자에서 최대 가치를 창출할 수 있다. 뿐만 아니라 소규모 데이터 세트를 학습하면 편향된 결과나 비윤리적 답변도 오히려 줄일 수 있다.
보안에서도 더 안전해진다. 예를 들어 최근 ‘구글 I/O’에서 구글은 PaLM2를 Gecko, Otter, Bison, Unicorn 4가지 크기로 세분화해 출시한다고 밝혔다. 사용 사례에 맞게 모델 크기를 선택해 쉽게 배포할 수 있게 한 것이다. Gecko는 가장 작은 사이즈의 모델로 모바일에서도 이용 가능해, 삼성 갤럭시를 통한 테스트에서 초당 20개 토큰 전달이 가능했다.
3. 파인튜닝(Fine-tuning, 미세조정)
파인튜닝(Fine-Tuning, 미세조정)이란 사전 학습된(pre-trained) 인공지능 모델을 이용해 필요한 과제에 맞게 모델을 다시 학습시키는 것을 말한다. 사전 학습된 모델의 가중치를 새로운 데이터에 맞게 세밀하게 조정하여 성능을 향상시키고 학습 시간을 줄이는 과정이다.
LLM을 특정 업무나 기능을 위해 사용하기 위해서는, pre-trained model을 특정 태스크에 맞게 파인튜닝 해야 하는 것이 필수적이다. 하지만 파인튜닝을 할 때, 모든 weight를 다시 학습시키게 되면 지금처럼 파라미터가 1,000억개 이상의 초대형 모델의 경우 파인튜닝 작업에만 몇 달이 소요되고 엄청나게 많은 GPU가 소모된다.
그래서 등장한 개념이 PEFT(Parameter Efficent Fine-Tuning)이다. 적은 양의 파라미터만 학습해서 유사한 성능을 가져오는 것을 목표로 하는 방법론이다. 대표적으로 adapter, LoRA, Promt tuning, Prefix tuning 등의 방법이 있는데, 최근 가장 주목받는 방법 중 하나는 21년 마이크로소프트가 발표한 논문 LoRA다.

LoRA(Low-Rank Adaptation)
LoRA의 방법은 이러하다. 거대한 파라미터를 가진 LLM을 매번 학습시키는 대신, 이 pre-trained model은 weight를 고정시켜두고, 내가 필요한 데이터는 학습 가능한 랭크 분해 행렬을 사용해 파인튜닝 시켜 추가 학습되는 파라미터수를 줄이는 모델병렬 기술력이다. 이 방법을 쓰면, 전체 LLM 파라미터를 기반으로 파인튜닝 할 때와 유사한 결과값을 얻게 된다.
핵심은, 기존 LLM Model은 RAM에 저장을 해 CPU inference만 진행하고, LoRA의 가중치만 GPU에 저장해 학습을 진행한다는 점이다. 이에 LoRA를 사용하면 VRAM 사용량을 대폭 감소시킬 수 있고, 체크포인트 크기를 줄여 GPU 수도 줄일 수 있다. 또 파인튜닝 작업을 수행할 때 그레디언트 계산이 필요하지 않아 효율성이 극대화된다.
GPT-3의 경우, 사용하는 VRAM 사용량이 1.2TB에서(A100 80GB 1200개) 350GB(A100 80GB 4~5개)로 줄었다. 또 25%의 속도 향상이 있었다. 또 추론 과정에서 추가적인 latency가 없다는 점도 특징이다. 한 사례에서는 A100 GPU 하나로 30분만에 튜닝을 했다고 한다.

4. 어플리케이션 개발 활성화를 위한 미들웨어 지속 등장 중
1990년대 초반에 네트워크, 클라이언트-서버 및 여러 계층의 아키텍처가 등장하면서 통합적으로 발생하는 문제를 해결하고 개발을 가속화하는 솔루션에 대한 필요성이 커졌다. 이에 컴퓨터와 어플리케이션 사이의 계층에서 비즈니스 프로세스와 데이터 통신 및 통합을 촉진하는 미들웨어가 개발되기 시작했다.
생성AI가 클라우드 컴퓨팅, 웹 서비스, API와의 연동 등과 밀접하게 연관되며 미들웨어는 점점 더 중요한 존재로 부상했다. 생성AI가 IT 환경 전반에 걸쳐 여러 애플리케이션과 시스템을 연결하는 강력한 도구 역할을 하기 위해서는 통합, 콘텐츠 분석, 요청-응답, 작업 성능 및 어플리케이션/시스템 업데이트 등이 원할히 이뤄져야하므로, 이를 담당하는 미들웨어가 부상 중이다.
생성AI의 대표적인 미들웨어로 랭체인(LangChaing)과 마이크로소프트가 서비스하는 시멘틱 커널 (Symantic Kernel)이 있다.
랭체인(LangChain)
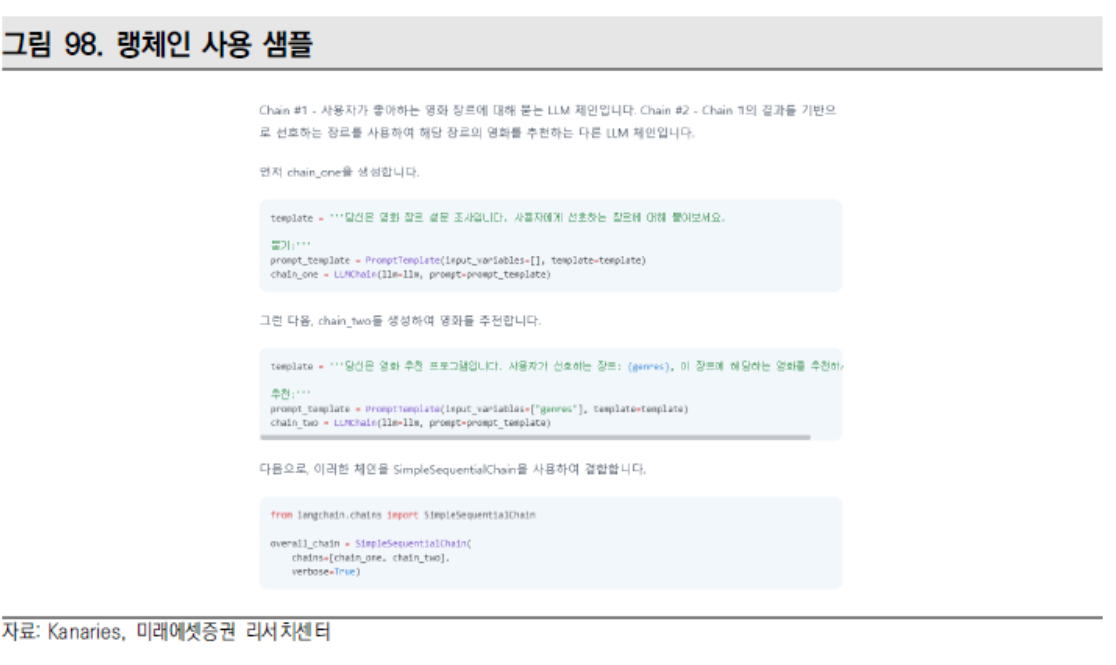
랭체인이란 LLM과 어플리케이션의 통합을 돕는 SDK다. 기존 프로그래밍 언어와 통합이 가능하다. 몇 줄의 코드로 기존 프로그래밍 언어와 연결되는 플러그인이 작동한다.

랭체인과 같은 프레임워크가 필요한 이유는 개발자가 AI를 사용해 어플리케이션을 만들 때 직면하는 문제들을 해결해주기 위함인데, 대표적으로
1) LLM에 단기 및 장기 메모리를 추가하는 것은 각 기업 개발자가 선택할 문제,
2) LLM에 대한 규칙을 만들어야 하는 것 - 매개변수 조정, 프롬프트 보강, 응답 조정부터 감정 분석, 분류, 질문과 답변 요약 등 적절한 상황에 맞는 모델 선택 등을 랭체인 프레임워크로 해결할 수 있다.
랭체인의 개발자는 해리슨 체이스로 2022년 10월 말 처음 랭체인을 선보였다. 랭체인이 지원하는 언어는 파이썬과 자바스크립트다.
시멘틱 커널(Symantic Kernel)
시멘틱 커널은 마이크로소프트가 오픈소스로 제공하는 SDK 프레임워크로, 랭체인과 같은 역할을 한다. 랭체인과 몇 가지 차이점이 있는데, 지원하는 언어가 C#, 파이썬, 자바 세 가지다.

출처: 미래에셋증권
뜨리스땅
https://tristanchoi.tistory.com/646
생성형 AI 시장의 경쟁 구도 - 빅테크 전략 종합 정리
빅테크의 Generative AI(생성AI) 주도권 싸움이 치열하다. OpenAI와 함께 ‘GPT-3.5’ 로 제일 먼저 생성AI를 수면위로 가져온 마이크로소프트(MSFT US)부터, AI 관련 연구가 가장 앞서 나간 구글(GOOGL US), 클
tristanchoi.tistory.com
'인터넷, 통신, 플랫폼, 컨텐츠 산업' 카테고리의 다른 글
| 생성형 AI 시장의 경쟁 구도 - 빅테크 전략 종합 정리 (0) | 2024.04.16 |
|---|---|
| 생성형 AI의 기술 트렌드 (0) | 2024.04.13 |
| AI 기업 - 딥노이드 (1) | 2024.02.12 |
| AI 기업 - 솔트룩스 (1) | 2024.02.11 |
| AI 기업 - 코난테크놀로지 (1) | 2024.02.11 |




댓글