(4) Autopilot 과 FSD Software
Autopilot 은 ADAS 수준이며, FSD 는 좀 더 높은 수준의 자율주행
테슬라의 자율주행 소프트웨어는 FSD(Full Self-Driving)으로 통용되지만, Autopilot 과 FSD Software 의 차이는 명확하다. Autopilot 은 기본적으로 TACC(주행 속도와 차량 간 거리 자동 조정), Auto Steer(차선 유지 보조) 기능을 제공하고 있으며, FSD 옵션을 구매할 경우 차선 변경, 고속도로 자율주행 등 더 높은 수준의 자율주행을 제공한다.
또한 완전자율주행에 가까운 FSD Beta 소프트웨어는 현재 북미 지역의 100,000 명을 대상으로 배포하고 있으며, 2022 년 중으로 지역을 더 확대할 예정이다. 다만 자율주행에서 구축한 데이터 엔진을 로봇에도 적용하기 시작한다는 관점에서, 각 소프트웨어 간의 차이보다는 FSD Beta 소프트웨어의 기술 수준이 더 중요하다.
자율주행의 기본은 인지-판단-제어
자율주행의 기본 과정은 ‘인지-판단-제어’이며, 차량은 센서와 컴퓨터를 탑재한 하나의 로봇이다. 앞서 언급한 인지와 예측의 과정 뿐만 아니라 판단과 제어도 포함되어야 한다. 즉, 카메라로 인지한 물체와 차선 등을 고려하여 어떻게 주행할 것인지 판단하고 제어하는 과정이 필요하다. 예를 들어, 사람이 갑자기 튀어나오면 멈춰야 한다고 판단하고 브레이크를 밟도록 연결한다.
FSD SW 는 앞서 구성한 공간을 사용해 목적지까지 어떻게 갈 것인지를 결정
즉 앞서 언급한 Vision Network 가 카메라의 비디오 데이터를 3D 공간으로 압축하였다면, FSD 소프트웨어는 이 공간 구성을 사용해 목적지까지 어떻게 갈 것인지를 결정한다.
기존 Action Space 는 비 볼록성, 고차원의 문제
기존 Action Space(행동공간)의 문제는 Non-Convex(비 볼록성)이다. 볼록 함수가 아니라는 것은 위아래로 Variance 가 크기 때문에 일관된 솔루션을 얻는 것이 어렵다. 즉, Minimum 이 여러 개 이기 때문에 Global Minimum 을 구하지 못하고 Local Minima 에 갇히는 문제가 생길 가능성이 높다. 또한 HighDimensional(고차원)의 문제도 있는데, 신경망이 너무 깊어져서 데이터보다 설명변수의 개수가 더 많다.
Hybrid Planning System 을 도입
이러한 문제들을 해결하기 위해 Hybrid-Planning System 을 도입했다. 우선, 비 볼록성을 해결하기(Convex Corridor) 위해 무작위적 탐색(Coarse Search)을 수행한다. 최적의 값을 찾기 위해 모든 노드를 하나씩 탐색을 진행하는데, MCTS(Monte Carlo Tree Search) 모델을 통해 임의로 모든 데이터들의 범위에서 임의로 데이터를 추출하여 탐색한다. 이후, 연속 최적화(Continuous Optimization)을 통해 궤적을 부드럽게 조정한다.
더 복잡한 실제 상황에 대해서는 Network Heuristic 을 적용
다만 실제 운전은 더 복잡하고 구조화되지 않은 상황이 더 많다. 이는 Neural Network Heuristic 을 통해 해결이 가능한데, 각 노드의 학습 가중치를 반복적으로 조정하여 점차 해를 찾아가는 기법이다. 예를 들어 주차를 하는 상황에서의 Heuristic 은 최단 거리를 찾는 것을 의미하며, 무작위 시뮬레이션을 통해 가능성이 높은 해를 선택한다. 이는 격자 기반의 A* 검색 알고리즘보다 더 적은 노드를 사용하여 해를 찾는 것이 가능하다.
경로 예측을 위해서는 비디오 데이터를 벡터 공간으로 구현한 뒤, 이 데이터를 Coarse Search 와 Continuous Optimization 을 활용해 기본 Planning 시스템에 입력한다. 다만 더 복잡한 상황에서는 네트워크 Planning 시스템이 궤적 분포를 생성해 End-to-End 로 최적화를 하고 다시 기본 Planning 시스템과 결합한다.
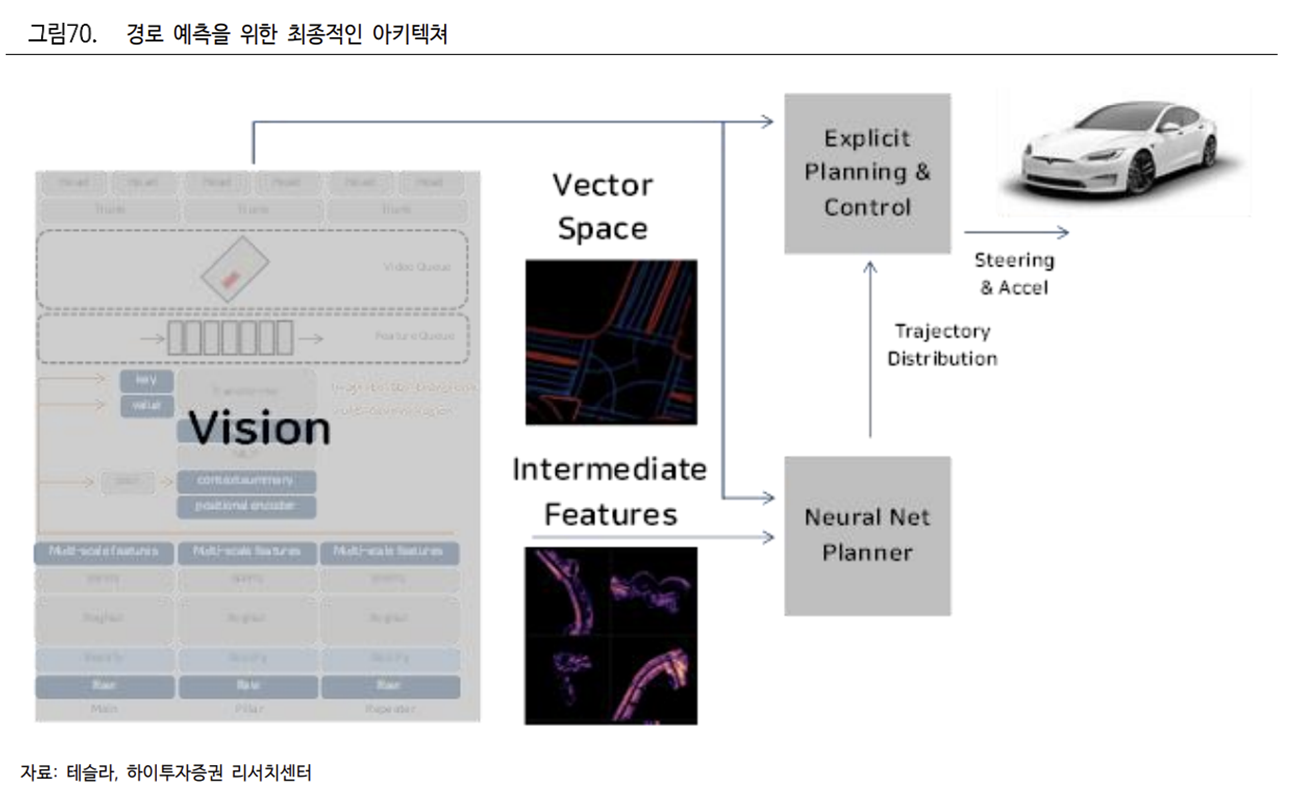
(5) FSD Computer: Mobileye → NVIDIA → Tesla
자율주행 칩을 유일하게 내재화
앞서 언급한 Pure Vision 방식의 핵심은 카메라로부터 얻은 데이터를 처리하는 방식이기 때문에, 이를 처리할 중앙 컴퓨터의 역할이 커지고 있다. 테슬라는 자동차 회사 중에서 유일하게 자율주행 칩을 내재화한 회사이다. Mobileye 의 EyeQ3 → 엔비디아의 Drive PX2 를 사용하다가, 2019 년 Autonomy Day 이후로 현재는 직접 설계한 FSD Chip 을 사용하고 있다. 이에 자연스럽게 타 업체들은 엔비디아, Mobileye 에 대한 의존도가 높아지고 있고, 앞으로 자율주행 시장에서 소수 기업의 과점이 전망된다.

내재화를 통해 기술적으로 효율을 높이는 것을 목표
엔비디아와 Mobileye 는 차량을 직접 제조하지 않기 때문에 어느 차량에 탑재되든 연산을 수행할 수 있도록 칩의 기본적인 성능을 높여 범용성을 확보하고자 한다. 이와 반대로 테슬라는 차량과 자율주행 소프트웨어까지 모두 내재화를 하였기 때문에 높은 성능보다는 기술적으로 효율을 높이는 것을 목적으로 한다.
신경 프로세서에서의 일반적인 기능들을 제거해 특수 목적으로 설계하였다. 앞서 언급한 뉴럴넷을 차량에서 수행하기 위해서는 Latency 를 최대한 줄이고 Frame Rate 를 최대한 높이는 과정이 필요하다. 현재 테슬라가 설계한 FSD Chip 은 Hardware 3.0 으로 초당 2,300 Frame 을 처리하며 144 TOPS 의 성능을 가지고 있다.

2 개의 FSD 칩은 Dual SoC 구조로 독립적으로 운영
FSD 컴퓨터는 2 개의 FSD 칩과 8 개의 카메라 커넥터, 자체 전력 서브 시스템, DRAM, 플래시 메모리로 구성되어 있다. 2 개의 FSD 칩은 Dual-SoC 구조로, 독립적으로 운영된다. 주로 하나의 엔진에서는 제어의 명령을 내리고, 다른 엔진은 확장 연산만 수행하는 방식으로 운영되지만, 하드웨어와 소프트웨어 레벨에서 대체하는 것도 가능하다. 즉 하나의 칩이 연산이 불가능한 상태가 되더라도 다른 칩을 활용해 주행을 마무리할 수 있다.
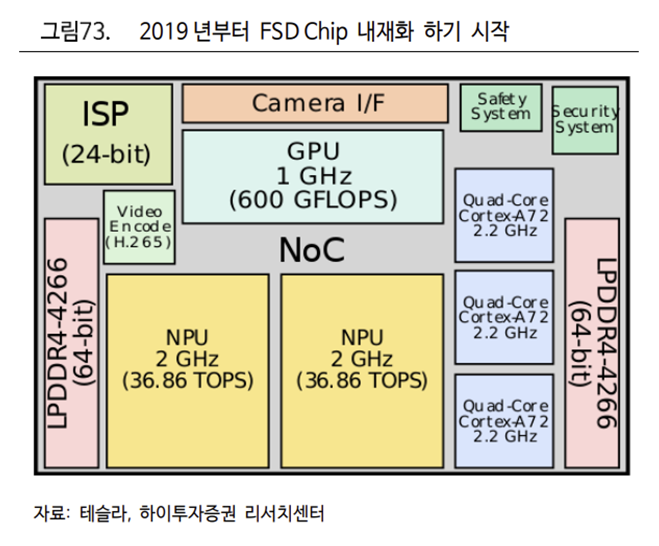
‘판단’과 관련하여 수많은 데이터 처리와 연산은 차량 외부의 슈퍼컴퓨터에서 진행되며, 통신을 통해 차량에 전달된 뒤에는 차량 내부에 저장될 필요가 없기 때문에 속도가 빠르지만 용량이 적은 SRAM 을 사용하여 신경망을 학습한다. 기존 CPU 에서 연산을 제외한 Icache, Register, Control 을 최소화하고, 연산 작업은 전체 파워의 0.15%만을 차지하기 때문에 전력 사용의 효율성 극대화가 가능했다.

(6) 필요한 데이터만 수집하는 Shadow Mode
롱테일 리스크를 줄이기 위해 데이터 셋 확장 필요
자율주행의 수준은 ‘판단 능력’이 결정하게 된다. 국가마다 조금씩 다르지만 충분한 경험이 축적되었다고 판단되는 17~20 세의 사람에게 주행 자격을 부여한다. 즉, 운전자를 대체할 자율주행 컴퓨터도 그에 준하는 충분한 경험과 데이터가 요구된다. 사고의 대부분은 20%의 특이 케이스에서 발생하며, 이러한 롱테일 리스크를 줄이기 위해 지속적인 데이터 셋 확장이 필요하다.
실주행 데이터를 중심으로 자율주행을 개발해 옴
테슬라는 실주행 데이터를 중심으로 자율주행을 개발해 왔다. 2020 년 공개된 자료에 따르면 테슬라는 98 만 대의 차량으로 33 억 마일의 데이터를 누적하였으며, 현재 250 만 대에 가까운 차량이 인도되었다는 점을 미루어봤을 때 훨씬 더 많은 데이터가 누적되고 있다. 이에 대해 10 초짜리 동영상 100 만 개와 바운딩 박스와 속도, 깊이 등의 특징까지 담은 60 억 개의 물체를 1.5PetaByte 만큼 축적하였다고 언급했다.
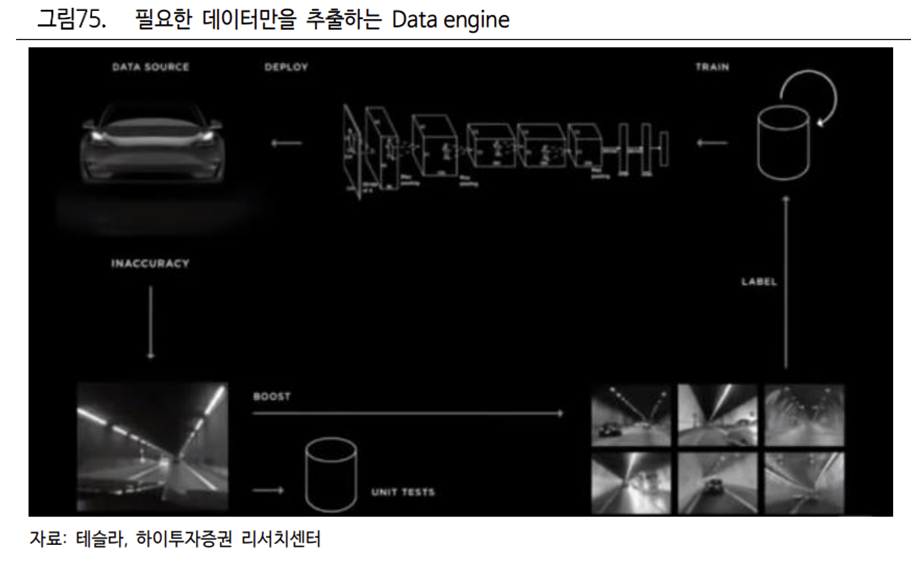
데이터의 질이 더 중요해짐. 221 개의 Trigger 로 필요한 데이터만 수집
그러나 점점 더 많은 데이터들이 축적되면서 데이터의 양보다는 데이터의 질이 더 중요해졌다. 수집되는 데이터들의 95%는 주행 판단에 사용되지 않는 다크 데이터이며 모든 데이터를 수집하고 처리하는 과정에는 시간과 비용이 소모될 수 밖에 없다. 그렇기 때문에 테슬라는 221 개의 Trigger 를 이용해 필요한 데이터만 수집하는 방식으로 효율성을 높였다. 이 Trigger 에는 센서 간 Noise, 터널 입출구 등의 시나리오들이 포함되어 있다.
차에 명령을 내리지 않고 조용히 운행하는 Shadow Mode
이러한 상황에 대한 비디오 Clip 을 보유하고 있다가 유사한 데이터들을 수집하는데, 차에 명령을 내리지 않고 조용히 운행하기 때문에 그림자 모드(Shadow Mode)라 불린다. 즉, Edge Case 에 대한 기준을 정의하여 운행 중인 각 차량을 검색 엔진처럼 활용한다. 특히 FSD 옵션을 갖춘 차량들은 물체 인지 알고리즘이 탑재되어 있기 때문에 미리 정의된 상황에 일치하는 데이터만을 저장하고 추출하는 것이 용이하다.
to be continued
https://www.youtube.com/watch?v=FwT4TSRsiVw
출처: 하이투자증권, 테슬라
뜨리스땅
https://tristanchoi.tistory.com/391
로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 2
(2) 2D 카메라로 구성한 Vector Space Pure Vision 의 핵심은 데이터 학습 다른 센서에 의존하지 않는, 카메라만을 활용한 물체 인지 알고리즘의 핵심은 결국 더 완벽한 데이터 학습을 통한 카메라 단점
tristanchoi.tistory.com
'로보틱스' 카테고리의 다른 글
| 로봇 산업 탐구: 로봇의 개요 및 시장 (1) | 2023.01.03 |
|---|---|
| 로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 4 (1) | 2023.01.02 |
| 로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 2 (1) | 2023.01.01 |
| 로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 1 (0) | 2023.01.01 |
| 로봇 기업 탐구: 테슬라 vs. 엔비디아 (0) | 2022.12.31 |




댓글