강화학습은 보상과 패널티로 최적의 행동을 유도하는 학습방법
강화학습은 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 인공지능이 보상을 통해 학습하는 것을 말한다. AI 는 올바른 행동을 취할 때마다 외부 환경에서 보상(Reward)을 받는다. 반면 반대 방향으로 행동을 할 때마다 패널티를 받으며 보상을 최대화하는 방향으로 학습한다.
예를 들어 로봇에게 A 지점에 있는 상자를 가지고 다시 원점으로 돌아오는 학습을 한다고 가정해보자. 곧바로 A 지점으로 이동하면 +3 점이라는 Reward 를 부여하고, A 지점이 아닌 B 지점으로 이동하면 -2 점을 부여한다. 같은 방법으로 상자를 원점으로 가져오면 +4 점, 가져오는 과정에서 물건을 떨어트린다면 -3 점을 부여하게 된다. 이처럼 강화학습은 점수를 높이는 방향으로 AI 스스로 학습한다.

강화학습이 인공지능의 학습에 본격적으로 사용되고 알려진 계기는 2016 년에 이루어진 알파고와 이세돌의 대국이었다. 알파고는 딥마인드에서 개발한 바둑 인공지능이다. 알파고는 실제 바둑 프로 기사들의 기보 데이터로 지도학습을 실시했다. 추가적으로 바둑 규칙과 보상(Reward) 및 벌칙(Punishment)만 설정한 후, 강화학습을 이용해서 바둑을 학습했다.
더 나아가 2017 년 등장한 알파고 제로는 실제 프로 기사들의 기보 데이터를 활용하지 않았다. 즉 지도학습이 아닌 강화학습으로만 바둑을 학습했다. 그 결과 구 버전 알파고와의 대국에서 모두 승리했다. 성능을 입증한 강화학습은 지도 학습의 보조적인 수단을 넘어 인공지능의 독립적인 학습법으로 자리잡았다.
로봇에의 강화학습 접목
알파고 제로는 로봇의 강화학습에도 많은 영향을 끼친다. 로봇의 학습은 다른 AI 플랫폼들보다 더 많은 데이터를 필요로 한다.
자동차 생산 공장에서 단순 조립 업무라고 해도, 주변 상황 및 조립 부품에 대한 이미지 처리가 필요하고, 부품을 파지해서 자동차에 조립하는 매니퓰레이터의 물리적인 동작도 학습해야 한다. 사람과 함께 일하는 현장이라면 안전 관리자의 자연어 명령에 대한 이해도 필요할 것이다. 이렇듯 많은 데이터를 사전에 전부 학습시키는 것은 불가능하다.
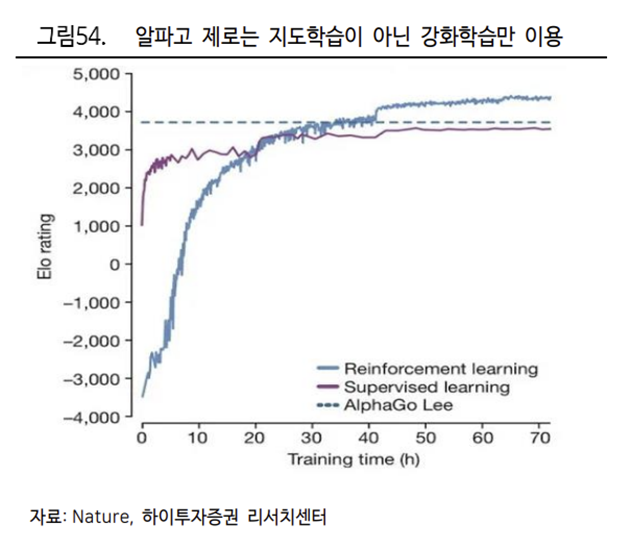
따라서 알파고 제로에 사용한 강화학습을 이용하여 로봇에게 이미지 처리, 자연어 처리 등 복합적이고 방대한 데이터를 학습시킬 수 있을 것이다. 뿐만 아니라 로봇은 다른 플랫폼들과 달리 중력이나 마찰력, 원심력 등 물리 법칙에 대한 높은 수준의 학습이나 운동학습도 필요하다.
앞으로 더욱 복잡한 업무를 수행하는 로봇들이 학습해야 할 물리 법칙은 계속 증가할 것이다. 이러한 물리법칙은 예외적 상황도 많이 연출하기에 학습으로 100% 커버하기란 쉽지 않다. 로봇이 움직이고 물건을 파지하는 간단한 학습은 실험실 내부에서 진행할 수 있겠지만 돌발 상황으로 차량과 충돌하여 기능이 고장난 경우, 오르막길을 오르다가 전복되는 경우 등은 실험실에서 훈련하기 쉽지 않다.
Digital Twin 을 이용한 물리법칙 학습도 병행
따라서 Digital Twin 을 이용하여 로봇은 물리 법칙을 학습할 수 있다. Digital Twin 은 GE 가 처음 제안한 개념으로, 현실 세계와 동일한 가상 현실을 말한다.
Digital Twin 의 성능을 판단하는 기준은 ‘얼마나 현실 세계와 가깝냐’이다. 현실 세계와 가깝다는 말은 곧 물리 법칙 및 빛의 성질을 이해하여, 가상 세계에의 학습 결과가 현실 세계에 바로 반영할 수 있다는 것을 뜻한다.
현재 대부분의 로봇 강화 학습은 각 로봇이 실제 세계에서 수행하는 과제와 동일한 환경을 가지는 ①Digital Twin에서 학습, ②현실 세계에 적용, ③피드백, ④Digital Twin에 업데이트의 순환 과정을 채택하고 있다.
더 나아가 개별적인 Digital Twin 을 연결하여 하나의 통합된 Digital Twin 을 구축할 수 있다. 이는 곧 현실 세계와 Digital Twin 이 가까워진다는 것을 의미하고, 강화 학습의 결과물은 더욱 정확해질 것이다.

https://www.youtube.com/watch?v=6m7SHphes4E
출처: 서울대학교AI연구원, 하이투자증권, 엔비디아, Nature
뜨리스땅
https://tristanchoi.tistory.com/387
로봇 기술 탐구: 로봇의 뇌(인공지능) 어디까지 왔나? - 2 (자연어 처리)
자연어처리(NLP)는 로봇과 컴퓨터에 명령체계로 매우 중요 - RNN 이나 LSTM 같은 알고리즘 사용 사람이 컴퓨터나 로봇에게 일정한 명령을 전달하기 위해선 약속된 수단이 있어야 한다. 지금은 주로
tristanchoi.tistory.com
'로보틱스' 카테고리의 다른 글
| 로봇 기업 탐구: Tesla. AI 와 로봇 기업으로의 확장 - 1 (0) | 2023.01.01 |
|---|---|
| 로봇 기업 탐구: 테슬라 vs. 엔비디아 (0) | 2022.12.31 |
| 로봇 기술 탐구: 로봇의 뇌(인공지능) 어디까지 왔나? - 2 (자연어 처리) (0) | 2022.12.31 |
| 로봇 기술 탐구: 로봇의 뇌(인공지능) 어디까지 왔나? - 1 (Neural Network) (1) | 2022.12.31 |
| 로봇 기술 탐구: 인공지능 용어 정리 (1) | 2022.12.30 |




댓글